 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Data Types More Problems: A Temporal Analysis of Complexity, Stability, and Sensitivity in Privacy Policies
Feb 17, 2023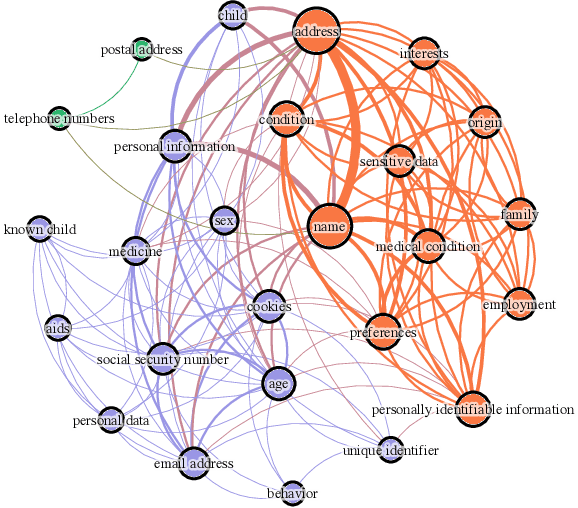



Collecting personally identifiable information (PII) on data subjects has become big business. Data brokers and data processors are part of a multi-billion-dollar industry that profits from collecting, buying, and selling consumer data. Yet there is little transparency in the data collection industry which makes it difficult to understand what types of data are being collected, used, and sold, and thus the risk to individual data subjects. In this study, we examine a large textual dataset of privacy policies from 1997-2019 in order to investigate the data collection activities of data brokers and data processors. We also develop an original lexicon of PII-related terms representing PII data types curated from legislative texts. This mesoscale analysis looks at privacy policies overtime on the word, topic, and network levels to understand the stability, complexity, and sensitivity of privacy policies over time. We find that (1) privacy legislation correlates with changes in stability and turbulence of PII data types in privacy policies; (2) the complexity of privacy policies decreases over time and becomes more regularized; (3) sensitivity rises over time and shows spikes that are correlated with events when new privacy legislation is introduced.
Sirius: A Mutual Information Tool for Exploratory Visualization of Mixed Data
Jun 09, 2021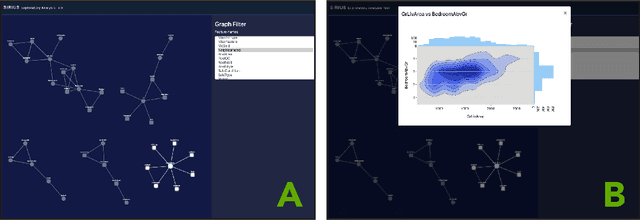
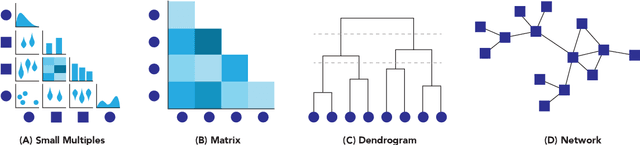
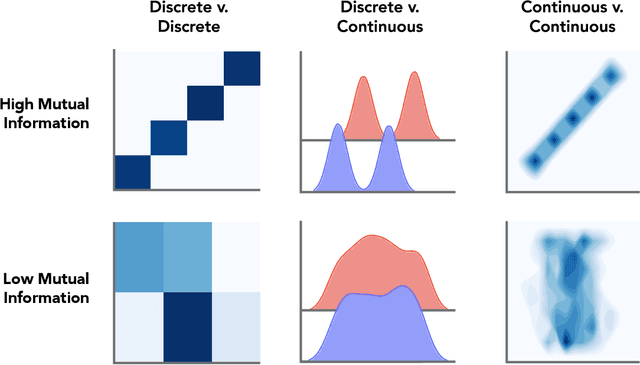

Data scientists across disciplines are increasingly in need of exploratory analysis tools for data sets with a high volume of features. We expand upon graph mining approaches for exploratory analysis of high-dimensional data to introduce Sirius, a visualization package for researchers to explore feature relationships among mixed data types using mutual information and network backbone sparsification. Visualizations of feature relationships aid data scientists in finding meaningful dependence among features, which can engender further analysis for feature selection, feature extraction, projection, identification of proxy variables, or insight into temporal variation at the macro scale. Graph mining approaches for feature analysis exist, such as association networks of binary features, or correlation networks of quantitative features, but mixed data types present a unique challenge for developing comprehensive feature networks for exploratory analysis. Using an information theoretic approach, Sirius supports heterogeneous data sets consisting of binary, continuous quantitative, and discrete categorical data types, and provides a user interface exploring feature pairs with high mutual information scores. We leverage a backbone sparsification approach from network theory as a dimensionality reduction technique, which probabilistically trims edges according to the local network context. Sirius is an open source Python package and Django web application for exploratory visualization, which can be deployed in data analysis pipelines. The Sirius codebase and exemplary data sets can be found at: https://github.com/compstorylab/sirius
What we write about when we write about causality: Features of causal statements across large-scale social discourse
Apr 21, 2016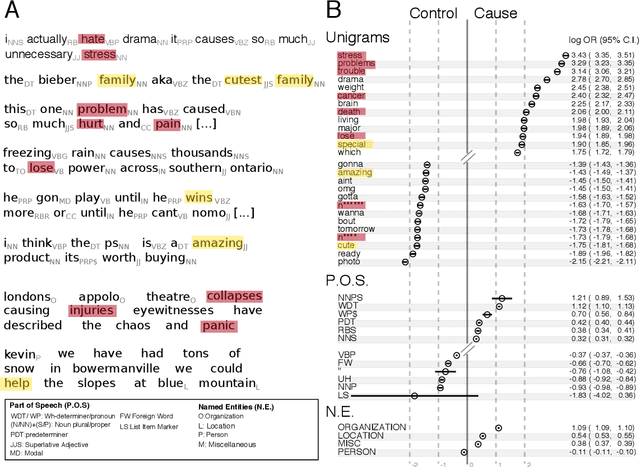
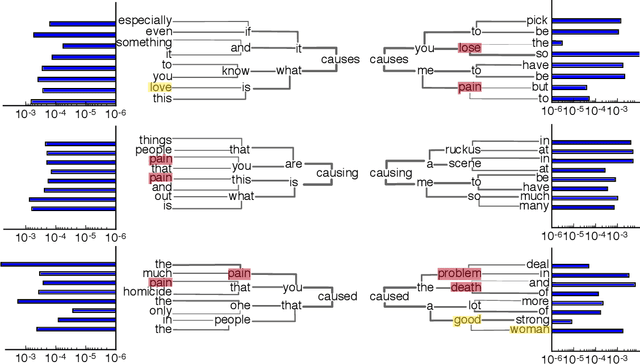
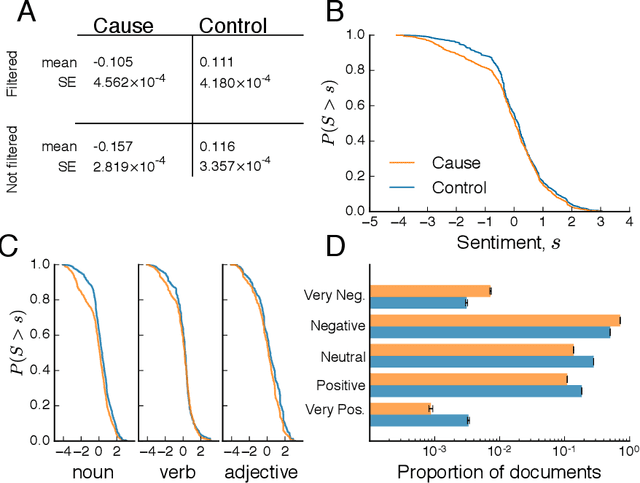

Identifying and communicating relationships between causes and effects is important for understanding our world, but is affected by language structure, cognitive and emotional biases, and the properties of the communication medium. Despite the increasing importance of social media, much remains unknown about causal statements made online. To study real-world causal attribution, we extract a large-scale corpus of causal statements made on the Twitter social network platform as well as a comparable random control corpus. We compare causal and control statements using statistical language and sentiment analysis tools. We find that causal statements have a number of significant lexical and grammatical differences compared with controls and tend to be more negative in sentiment than controls. Causal statements made online tend to focus on news and current events, medicine and health, or interpersonal relationships, as shown by topic models. By quantifying the features and potential biases of causality communication, this study improves our understanding of the accuracy of information and opinions found online.
Nonlinear functional mapping of the human brain
Sep 08, 2015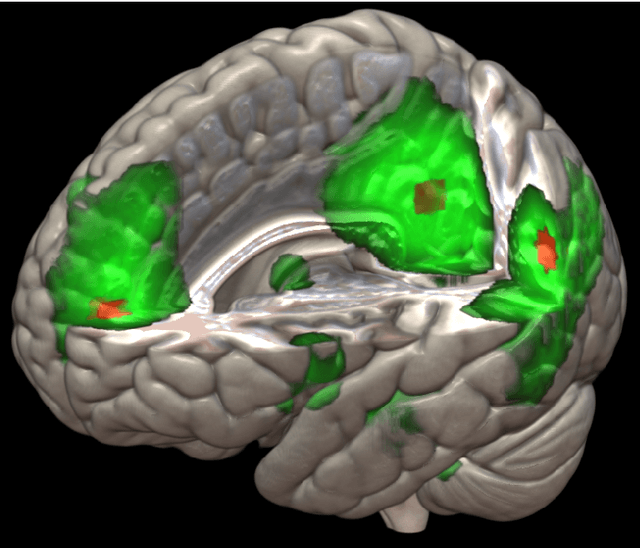
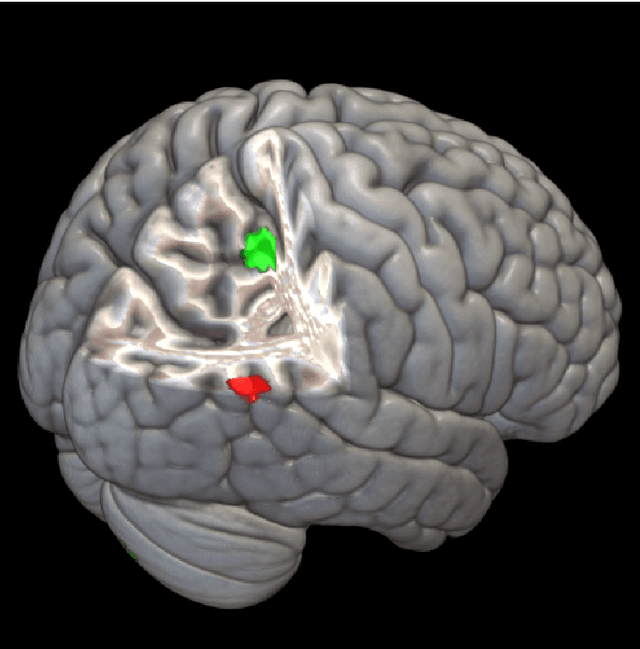
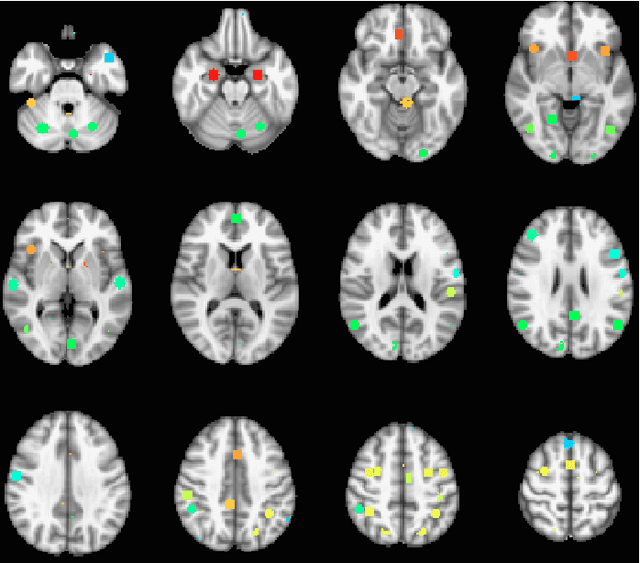
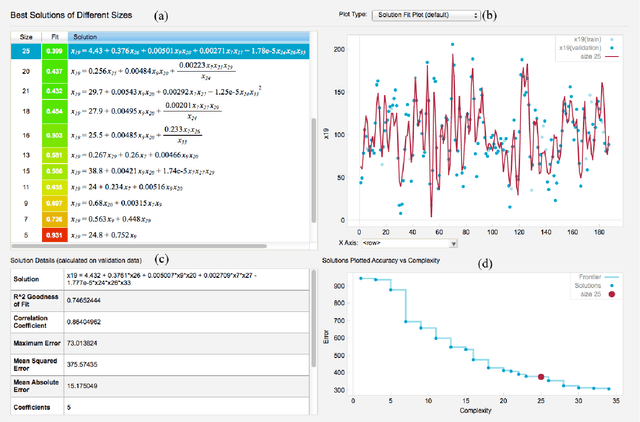
The field of neuroimaging has truly become data rich, and novel analytical methods capable of gleaning meaningful information from large stores of imaging data are in high demand. Those methods that might also be applicable on the level of individual subjects, and thus potentially useful clinically, are of special interest. In the present study, we introduce just such a method, called nonlinear functional mapping (NFM), and demonstrate its application in the analysis of resting state fMRI from a 242-subject subset of the IMAGEN project, a European study of adolescents that includes longitudinal phenotypic, behavioral, genetic, and neuroimaging data. NFM employs a computational technique inspired by biological evolution to discover and mathematically characterize interactions among ROI (regions of interest), without making linear or univariate assumptions. We show that statistics of the resulting interaction relationships comport with recent independent work, constituting a preliminary cross-validation. Furthermore, nonlinear terms are ubiquitous in the models generated by NFM, suggesting that some of the interactions characterized here are not discoverable by standard linear methods of analysis. We discuss one such nonlinear interaction in the context of a direct comparison with a procedure involving pairwise correlation, designed to be an analogous linear version of functional mapping. We find another such interaction that suggests a novel distinction in brain function between drinking and non-drinking adolescents: a tighter coupling of ROI associated with emotion, reward, and interoceptive processes such as thirst, among drinkers. Finally, we outline many improvements and extensions of the methodology to reduce computational expense, complement other analytical tools like graph-theoretic analysis, and allow for voxel level NFM to eliminate the necessity of ROI selection.