 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient crowdsourcing of crowd-generated microtasks
Dec 10, 2019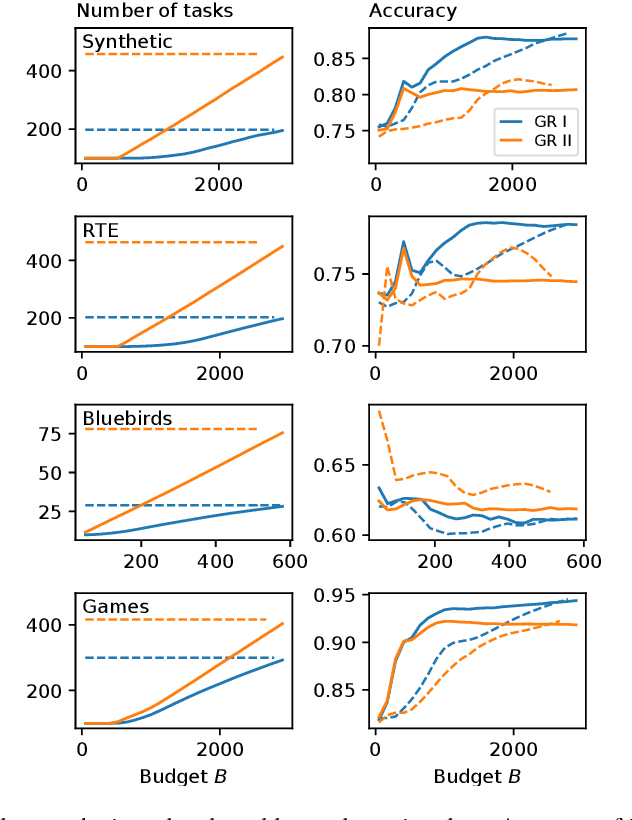
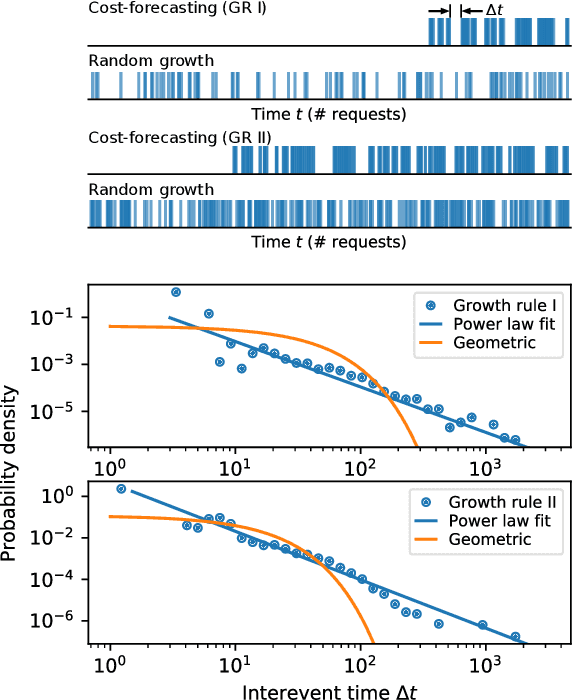
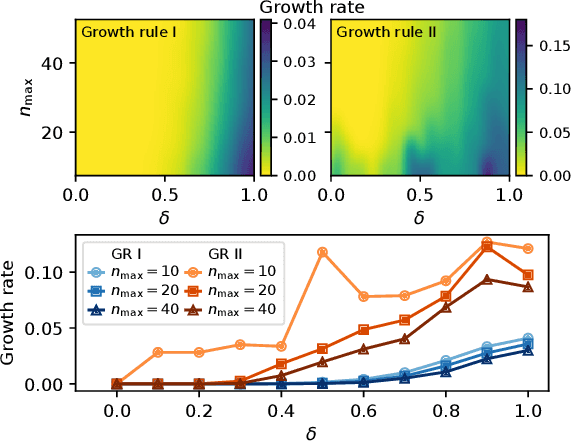
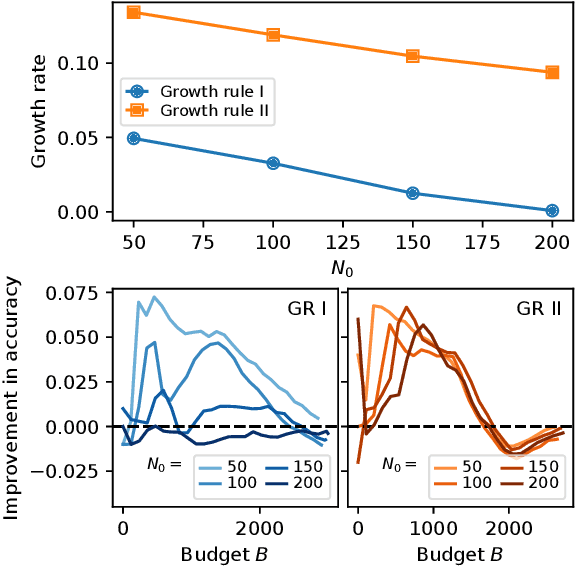
Allowing members of the crowd to propose novel microtasks for one another is an effective way to combine the efficiencies of traditional microtask work with the inventiveness and hypothesis generation potential of human workers. However, microtask proposal leads to a growing set of tasks that may overwhelm limited crowdsourcer resources. Crowdsourcers can employ methods to utilize their resources efficiently, but algorithmic approaches to efficient crowdsourcing generally require a fixed task set of known size. In this paper, we introduce *cost forecasting* as a means for a crowdsourcer to use efficient crowdsourcing algorithms with a growing set of microtasks. Cost forecasting allows the crowdsourcer to decide between eliciting new tasks from the crowd or receiving responses to existing tasks based on whether or not new tasks will cost less to complete than existing tasks, efficiently balancing resources as crowdsourcing occurs. Experiments with real and synthetic crowdsourcing data show that cost forecasting leads to improved accuracy. Accuracy and efficiency gains for crowd-generated microtasks hold the promise to further leverage the creativity and wisdom of the crowd, with applications such as generating more informative and diverse training data for machine learning applications and improving the performance of user-generated content and question-answering platforms.
Accurate inference of crowdsourcing properties when using efficient allocation strategies
Mar 07, 2019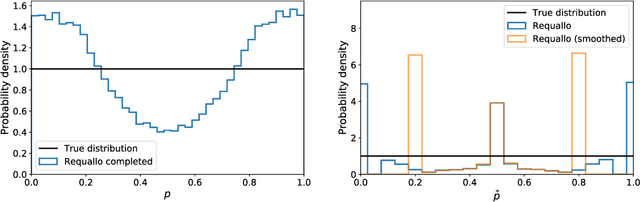
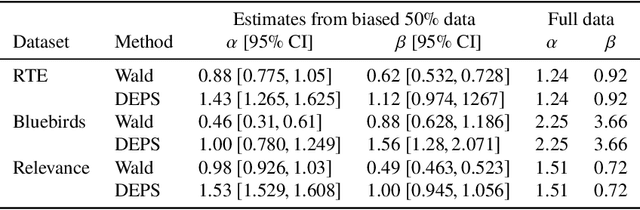
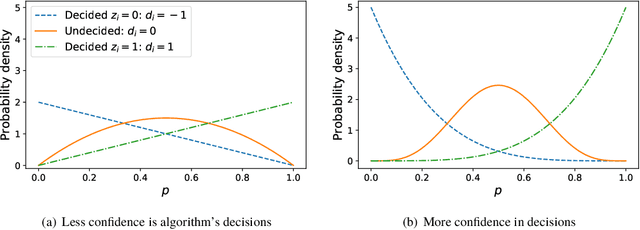
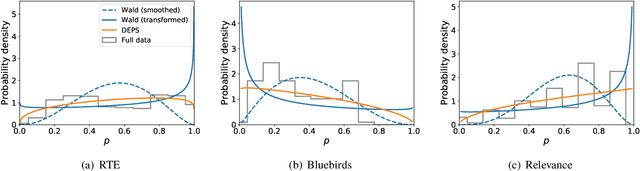
Allocation strategies improve the efficiency of crowdsourcing by decreasing the work needed to complete individual tasks accurately. However, these algorithms introduce bias by preferentially allocating workers onto easy tasks, leading to sets of completed tasks that are no longer representative of all tasks. This bias challenges inference of problem-wide properties such as typical task difficulty or crowd properties such as worker completion times, important information that goes beyond the crowd responses themselves. Here we study inference about problem properties when using an allocation algorithm to improve crowd efficiency. We introduce Decision-Explicit Probability Sampling (DEPS), a method to perform inference of problem properties while accounting for the potential bias introduced by an allocation strategy. Experiments on real and synthetic crowdsourcing data show that DEPS outperforms baseline inference methods while still leveraging the efficiency gains of the allocation method. The ability to perform accurate inference of general properties when using non-representative data allows crowdsourcers to extract more knowledge out of a given crowdsourced dataset.