 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift- and stretch-invariant non-negative matrix factorization with an application to brain tissue delineation in emission tomography data
Apr 09, 2026Dynamic neuroimaging data, such as emission tomography measurements of radiotracer transport in blood or cerebrospinal fluid, often exhibit diffusion-like properties. These introduce distance-dependent temporal delays, scale-differences, and stretching effects that limit the effectiveness of conventional linear modeling and decomposition methods. To address this, we present the shift- and stretch-invariant non-negative matrix factorization framework. Our approach estimates both integer and non-integer temporal shifts as well as temporal stretching, all implemented in the frequency domain, where shifts correspond to phase modifications, and where stretching is handled via zero-padding or truncation. The model is implemented in PyTorch (https://github.com/anders-s-olsen/shiftstretchNMF). We demonstrate on synthetic data and brain emission tomography data that the model is able to account for stretching to provide more detailed characterization of brain tissue structure.
A Survey on Archetypal Analysis
Apr 16, 2025Archetypal analysis (AA) was originally proposed in 1994 by Adele Cutler and Leo Breiman as a computational procedure to extract the distinct aspects called archetypes in observations with each observational record approximated as a mixture (i.e., convex combination) of these archetypes. AA thereby provides straightforward, interpretable, and explainable representations for feature extraction and dimensionality reduction, facilitating the understanding of the structure of high-dimensional data with wide applications throughout the sciences. However, AA also faces challenges, particularly as the associated optimization problem is non-convex. This survey provides researchers and data mining practitioners an overview of methodologies and opportunities that AA has to offer surveying the many applications of AA across disparate fields of science, as well as best practices for modeling data using AA and limitations. The survey concludes by explaining important future research directions concerning AA.
How Low Can You Go? Searching for the Intrinsic Dimensionality of Complex Networks using Metric Node Embeddings
Mar 03, 2025



Low-dimensional embeddings are essential for machine learning tasks involving graphs, such as node classification, link prediction, community detection, network visualization, and network compression. Although recent studies have identified exact low-dimensional embeddings, the limits of the required embedding dimensions remain unclear. We presently prove that lower dimensional embeddings are possible when using Euclidean metric embeddings as opposed to vector-based Logistic PCA (LPCA) embeddings. In particular, we provide an efficient logarithmic search procedure for identifying the exact embedding dimension and demonstrate how metric embeddings enable inference of the exact embedding dimensions of large-scale networks by exploiting that the metric properties can be used to provide linearithmic scaling. Empirically, we show that our approach extracts substantially lower dimensional representations of networks than previously reported for small-sized networks. For the first time, we demonstrate that even large-scale networks can be effectively embedded in very low-dimensional spaces, and provide examples of scalable, exact reconstruction for graphs with up to a million nodes. Our approach highlights that the intrinsic dimensionality of networks is substantially lower than previously reported and provides a computationally efficient assessment of the exact embedding dimension also of large-scale networks. The surprisingly low dimensional representations achieved demonstrate that networks in general can be losslessly represented using very low dimensional feature spaces, which can be used to guide existing network analysis tasks from community detection and node classification to structure revealing exact network visualizations.
Archetypal Analysis for Binary Data
Feb 06, 2025


Archetypal analysis (AA) is a matrix decomposition method that identifies distinct patterns using convex combinations of the data points denoted archetypes with each data point in turn reconstructed as convex combinations of the archetypes. AA thereby forms a polytope representing trade-offs of the distinct aspects in the data. Most existing methods for AA are designed for continuous data and do not exploit the structure of the data distribution. In this paper, we propose two new optimization frameworks for archetypal analysis for binary data. i) A second order approximation of the AA likelihood based on the Bernoulli distribution with efficient closed-form updates using an active set procedure for learning the convex combinations defining the archetypes, and a sequential minimal optimization strategy for learning the observation specific reconstructions. ii) A Bernoulli likelihood based version of the principal convex hull analysis (PCHA) algorithm originally developed for least squares optimization. We compare these approaches with the only existing binary AA procedure relying on multiplicative updates and demonstrate their superiority on both synthetic and real binary data. Notably, the proposed optimization frameworks for AA can easily be extended to other data distributions providing generic efficient optimization frameworks for AA based on tailored likelihood functions reflecting the underlying data distribution.
SepMamba: State-space models for speaker separation using Mamba
Oct 28, 2024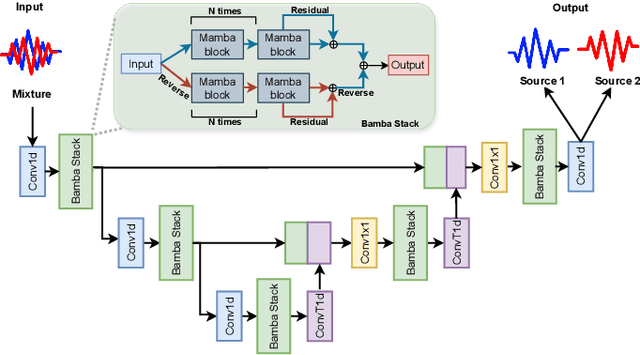
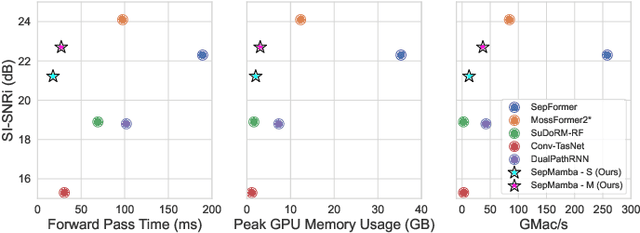

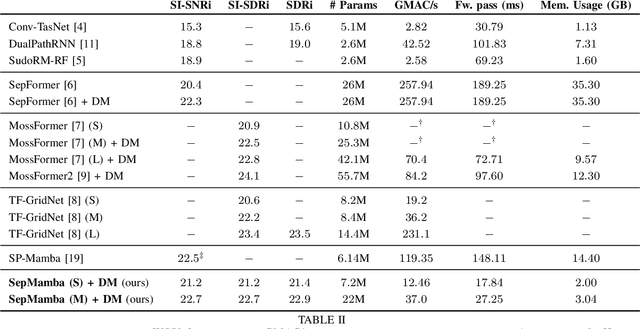
Deep learning-based single-channel speaker separation has improved significantly in recent years largely due to the introduction of the transformer-based attention mechanism. However, these improvements come at the expense of intense computational demands, precluding their use in many practical applications. As a computationally efficient alternative with similar modeling capabilities, Mamba was recently introduced. We propose SepMamba, a U-Net-based architecture composed primarily of bidirectional Mamba layers. We find that our approach outperforms similarly-sized prominent models - including transformer-based models - on the WSJ0 2-speaker dataset while enjoying a significant reduction in computational cost, memory usage, and forward pass time. We additionally report strong results for causal variants of SepMamba. Our approach provides a computationally favorable alternative to transformer-based architectures for deep speech separation.
Modeling Human Responses by Ordinal Archetypal Analysis
Sep 12, 2024

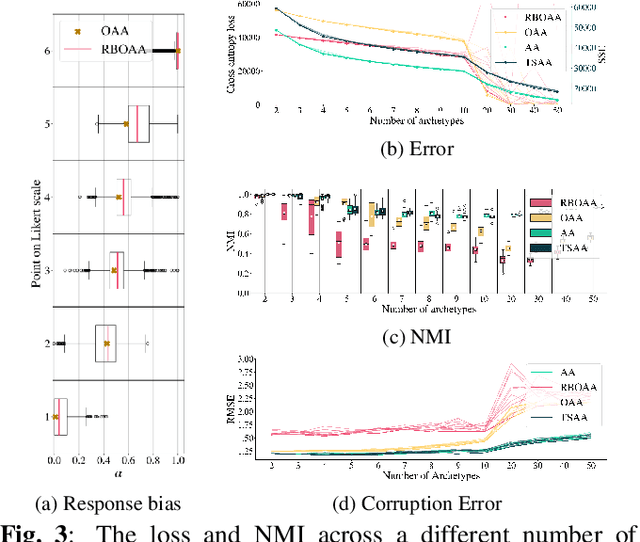
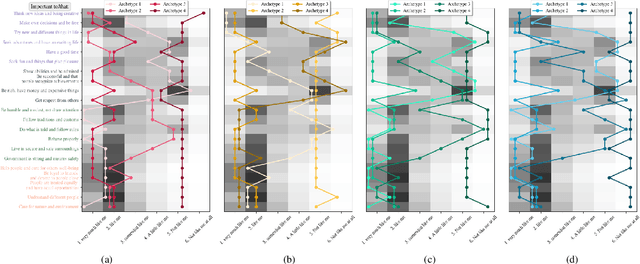
This paper introduces a novel framework for Archetypal Analysis (AA) tailored to ordinal data, particularly from questionnaires. Unlike existing methods, the proposed method, Ordinal Archetypal Analysis (OAA), bypasses the two-step process of transforming ordinal data into continuous scales and operates directly on the ordinal data. We extend traditional AA methods to handle the subjective nature of questionnaire-based data, acknowledging individual differences in scale perception. We introduce the Response Bias Ordinal Archetypal Analysis (RBOAA), which learns individualized scales for each subject during optimization. The effectiveness of these methods is demonstrated on synthetic data and the European Social Survey dataset, highlighting their potential to provide deeper insights into human behavior and perception. The study underscores the importance of considering response bias in cross-national research and offers a principled approach to analyzing ordinal data through Archetypal Analysis.
Non-negative Tensor Mixture Learning for Discrete Density Estimation
May 28, 2024We present an expectation-maximization (EM) based unified framework for non-negative tensor decomposition that optimizes the Kullback-Leibler divergence. To avoid iterations in each M-step and learning rate tuning, we establish a general relationship between low-rank decomposition and many-body approximation. Using this connection, we exploit that the closed-form solution of the many-body approximation can be used to update all parameters simultaneously in the M-step. Our framework not only offers a unified methodology for a variety of low-rank structures, including CP, Tucker, and Train decompositions, but also their combinations forming mixtures of tensors as well as robust adaptive noise modeling. Empirically, we demonstrate that our framework provides superior generalization for discrete density estimation compared to conventional tensor-based approaches.
Time to Cite: Modeling Citation Networks using the Dynamic Impact Single-Event Embedding Model
Feb 28, 2024Understanding the structure and dynamics of scientific research, i.e., the science of science (SciSci), has become an important area of research in order to address imminent questions including how scholars interact to advance science, how disciplines are related and evolve, and how research impact can be quantified and predicted. Central to the study of SciSci has been the analysis of citation networks. Here, two prominent modeling methodologies have been employed: one is to assess the citation impact dynamics of papers using parametric distributions, and the other is to embed the citation networks in a latent space optimal for characterizing the static relations between papers in terms of their citations. Interestingly, citation networks are a prominent example of single-event dynamic networks, i.e., networks for which each dyad only has a single event (i.e., the point in time of citation). We presently propose a novel likelihood function for the characterization of such single-event networks. Using this likelihood, we propose the Dynamic Impact Single-Event Embedding model (DISEE). The \textsc{\modelabbrev} model characterizes the scientific interactions in terms of a latent distance model in which random effects account for citation heterogeneity while the time-varying impact is characterized using existing parametric representations for assessment of dynamic impact. We highlight the proposed approach on several real citation networks finding that the DISEE well reconciles static latent distance network embedding approaches with classical dynamic impact assessments.
Continuous-time Graph Representation with Sequential Survival Process
Dec 20, 2023Over the past two decades, there has been a tremendous increase in the growth of representation learning methods for graphs, with numerous applications across various fields, including bioinformatics, chemistry, and the social sciences. However, current dynamic network approaches focus on discrete-time networks or treat links in continuous-time networks as instantaneous events. Therefore, these approaches have limitations in capturing the persistence or absence of links that continuously emerge and disappear over time for particular durations. To address this, we propose a novel stochastic process relying on survival functions to model the durations of links and their absences over time. This forms a generic new likelihood specification explicitly accounting for intermittent edge-persistent networks, namely GraSSP: Graph Representation with Sequential Survival Process. We apply the developed framework to a recent continuous time dynamic latent distance model characterizing network dynamics in terms of a sequence of piecewise linear movements of nodes in latent space. We quantitatively assess the developed framework in various downstream tasks, such as link prediction and network completion, demonstrating that the developed modeling framework accounting for link persistence and absence well tracks the intrinsic trajectories of nodes in a latent space and captures the underlying characteristics of evolving network structure.
CSLP-AE: A Contrastive Split-Latent Permutation Autoencoder Framework for Zero-Shot Electroencephalography Signal Conversion
Nov 13, 2023Electroencephalography (EEG) is a prominent non-invasive neuroimaging technique providing insights into brain function. Unfortunately, EEG data exhibit a high degree of noise and variability across subjects hampering generalizable signal extraction. Therefore, a key aim in EEG analysis is to extract the underlying neural activation (content) as well as to account for the individual subject variability (style). We hypothesize that the ability to convert EEG signals between tasks and subjects requires the extraction of latent representations accounting for content and style. Inspired by recent advancements in voice conversion technologies, we propose a novel contrastive split-latent permutation autoencoder (CSLP-AE) framework that directly optimizes for EEG conversion. Importantly, the latent representations are guided using contrastive learning to promote the latent splits to explicitly represent subject (style) and task (content). We contrast CSLP-AE to conventional supervised, unsupervised (AE), and self-supervised (contrastive learning) training and find that the proposed approach provides favorable generalizable characterizations of subject and task. Importantly, the procedure also enables zero-shot conversion between unseen subjects. While the present work only considers conversion of EEG, the proposed CSLP-AE provides a general framework for signal conversion and extraction of content (task activation) and style (subject variability) components of general interest for the modeling and analysis of biological signals.