 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSepMamba: State-space models for speaker separation using Mamba
Oct 28, 2024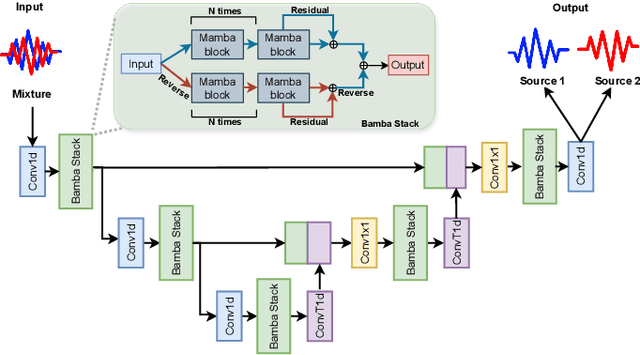
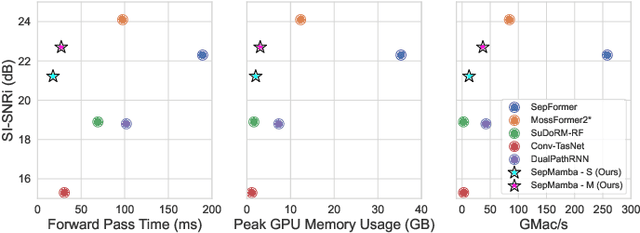

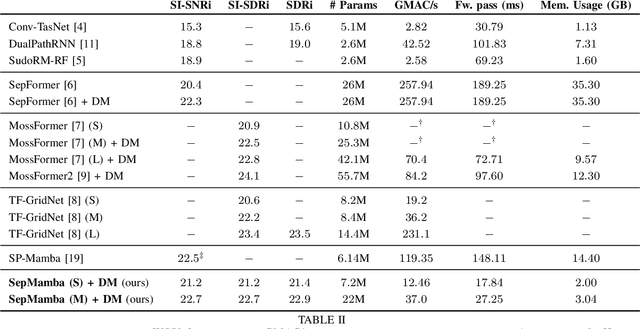
Deep learning-based single-channel speaker separation has improved significantly in recent years largely due to the introduction of the transformer-based attention mechanism. However, these improvements come at the expense of intense computational demands, precluding their use in many practical applications. As a computationally efficient alternative with similar modeling capabilities, Mamba was recently introduced. We propose SepMamba, a U-Net-based architecture composed primarily of bidirectional Mamba layers. We find that our approach outperforms similarly-sized prominent models - including transformer-based models - on the WSJ0 2-speaker dataset while enjoying a significant reduction in computational cost, memory usage, and forward pass time. We additionally report strong results for causal variants of SepMamba. Our approach provides a computationally favorable alternative to transformer-based architectures for deep speech separation.