 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSepMamba: State-space models for speaker separation using Mamba
Oct 28, 2024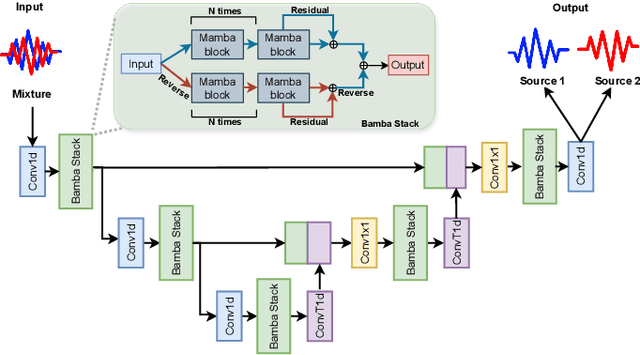
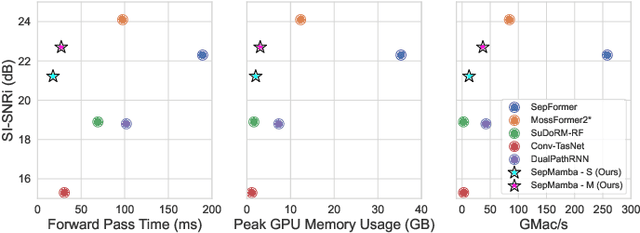

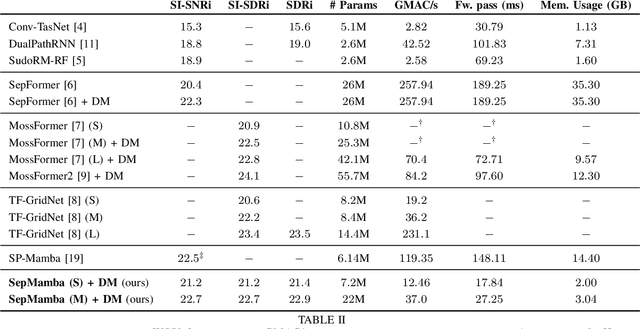
Deep learning-based single-channel speaker separation has improved significantly in recent years largely due to the introduction of the transformer-based attention mechanism. However, these improvements come at the expense of intense computational demands, precluding their use in many practical applications. As a computationally efficient alternative with similar modeling capabilities, Mamba was recently introduced. We propose SepMamba, a U-Net-based architecture composed primarily of bidirectional Mamba layers. We find that our approach outperforms similarly-sized prominent models - including transformer-based models - on the WSJ0 2-speaker dataset while enjoying a significant reduction in computational cost, memory usage, and forward pass time. We additionally report strong results for causal variants of SepMamba. Our approach provides a computationally favorable alternative to transformer-based architectures for deep speech separation.
Reinforcement learning guided fuzz testing for a browser's HTML rendering engine
Jul 27, 2023



Generation-based fuzz testing can uncover various bugs and security vulnerabilities. However, compared to mutation-based fuzz testing, it takes much longer to develop a well-balanced generator that produces good test cases and decides where to break the underlying structure to exercise new code paths. We propose a novel approach to combine a trained test case generator deep learning model with a double deep Q-network (DDQN) for the first time. The DDQN guides test case creation based on a code coverage signal. Our approach improves the code coverage performance of the underlying generator model by up to 18.5\% for the Firefox HTML rendering engine compared to the baseline grammar based fuzzer.
Learning Robust Controllers Via Probabilistic Model-Based Policy Search
Oct 26, 2021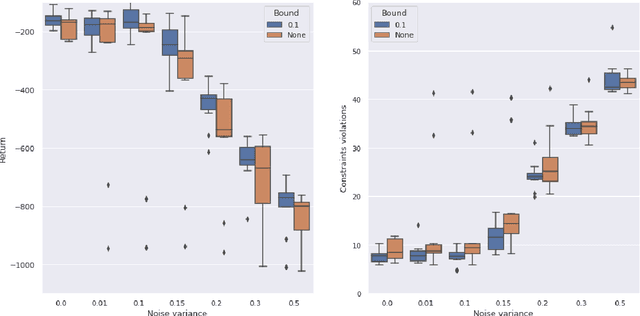

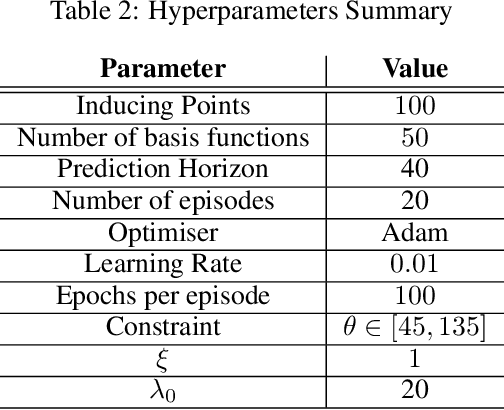
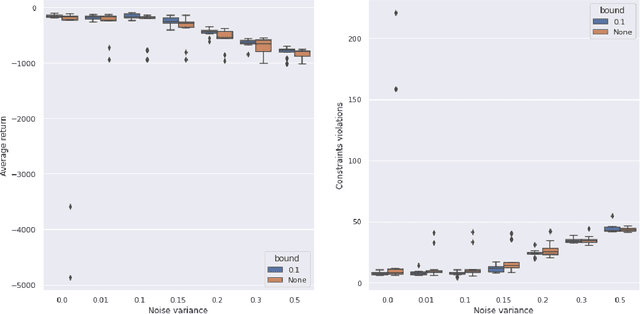
Model-based Reinforcement Learning estimates the true environment through a world model in order to approximate the optimal policy. This family of algorithms usually benefits from better sample efficiency than their model-free counterparts. We investigate whether controllers learned in such a way are robust and able to generalize under small perturbations of the environment. Our work is inspired by the PILCO algorithm, a method for probabilistic policy search. We show that enforcing a lower bound to the likelihood noise in the Gaussian Process dynamics model regularizes the policy updates and yields more robust controllers. We demonstrate the empirical benefits of our method in a simulation benchmark.
Odd-One-Out Representation Learning
Dec 14, 2020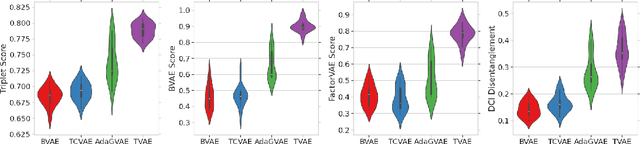
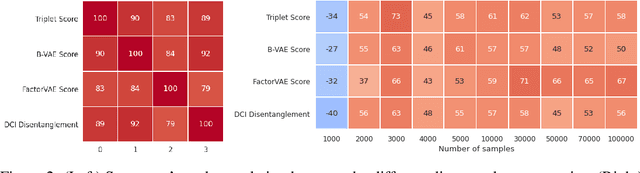
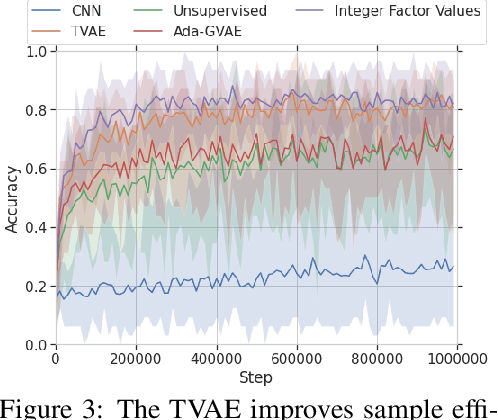

The effective application of representation learning to real-world problems requires both techniques for learning useful representations, and also robust ways to evaluate properties of representations. Recent work in disentangled representation learning has shown that unsupervised representation learning approaches rely on fully supervised disentanglement metrics, which assume access to labels for ground-truth factors of variation. In many real-world cases ground-truth factors are expensive to collect, or difficult to model, such as for perception. Here we empirically show that a weakly-supervised downstream task based on odd-one-out observations is suitable for model selection by observing high correlation on a difficult downstream abstract visual reasoning task. We also show that a bespoke metric-learning VAE model which performs highly on this task also out-performs other standard unsupervised and a weakly-supervised disentanglement model across several metrics.
Probabilistic selection of inducing points in sparse Gaussian processes
Oct 31, 2020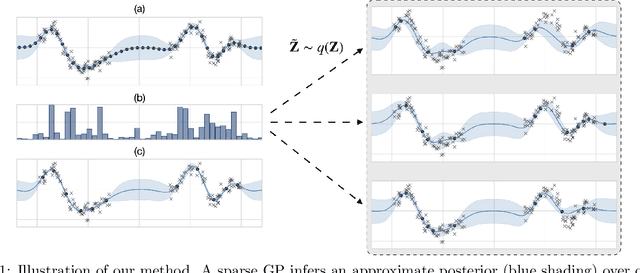

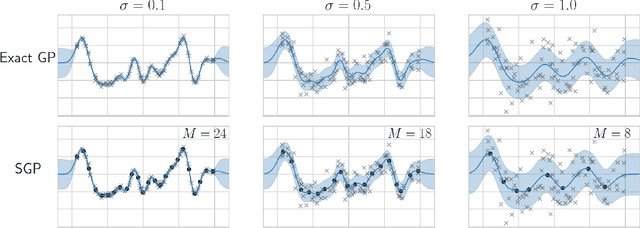
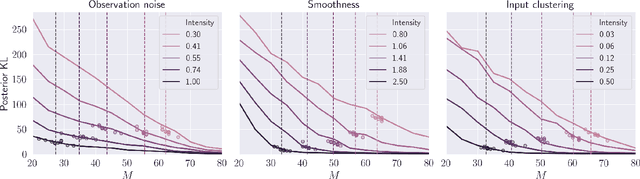
Sparse Gaussian processes and various extensions thereof are enabled through inducing points, that simultaneously bottleneck the predictive capacity and act as the main contributor towards model complexity. However, the number of inducing points is generally not associated with uncertainty which prevents us from applying the apparatus of Bayesian reasoning in identifying an appropriate trade-off. In this work we place a point process prior on the inducing points and approximate the associated posterior through stochastic variational inference. By letting the prior encourage a moderate number of inducing points, we enable the model to learn which and how many points to utilise. We experimentally show that fewer inducing points are preferred by the model as the points become less informative, and further demonstrate how the method can be applied in deep Gaussian processes and latent variable modelling.
Recurrent Neural Networks for Fuzz Testing Web Browsers
Dec 12, 2018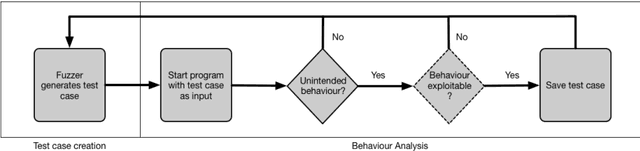
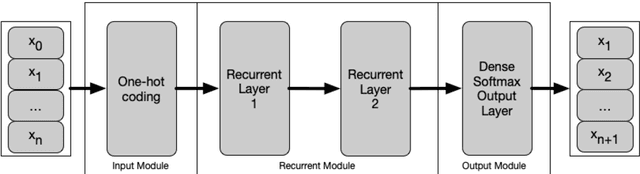
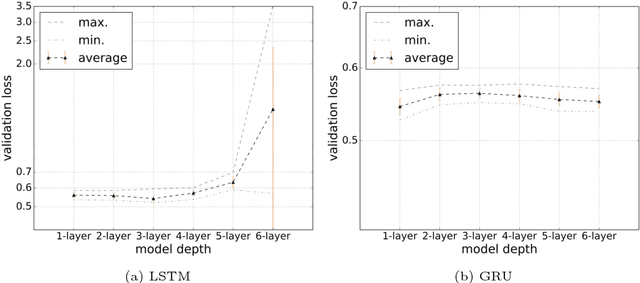
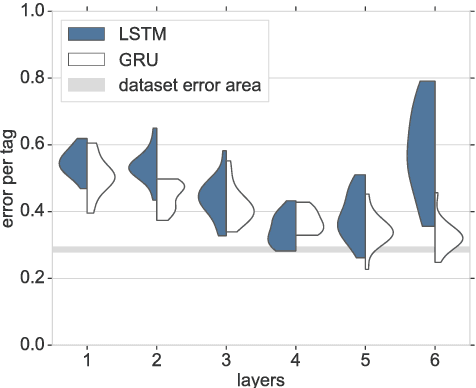
Generation-based fuzzing is a software testing approach which is able to discover different types of bugs and vulnerabilities in software. It is, however, known to be very time consuming to design and fine tune classical fuzzers to achieve acceptable coverage, even for small-scale software systems. To address this issue, we investigate a machine learning-based approach to fuzz testing in which we outline a family of test-case generators based on Recurrent Neural Networks (RNNs) and train those on readily available datasets with a minimum of human fine tuning. The proposed generators do, in contrast to previous work, not rely on heuristic sampling strategies but principled sampling from the predictive distributions. We provide a detailed analysis to demonstrate the characteristics and efficacy of the proposed generators in a challenging web browser testing scenario. The empirical results show that the RNN-based generators are able to provide better coverage than a mutation based method and are able to discover paths not discovered by a classical fuzzer. Our results supplement findings in other domains suggesting that generation based fuzzing with RNNs is a viable route to better software quality conditioned on the use of a suitable model selection/analysis procedure.
A Topic Model Approach to Multi-Modal Similarity
May 27, 2014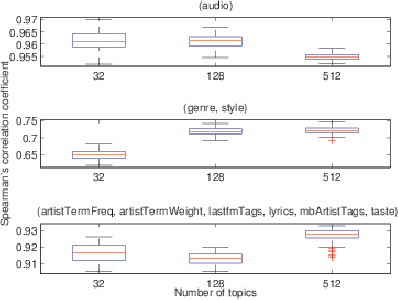
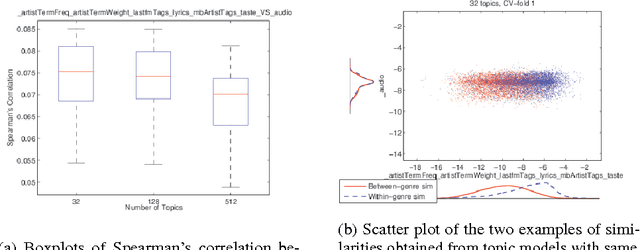
Calculating similarities between objects defined by many heterogeneous data modalities is an important challenge in many multimedia applications. We use a multi-modal topic model as a basis for defining such a similarity between objects. We propose to compare the resulting similarities from different model realizations using the non-parametric Mantel test. The approach is evaluated on a music dataset.