 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Temporal Nature of Human Behavior for Demographics Prediction
Nov 15, 2017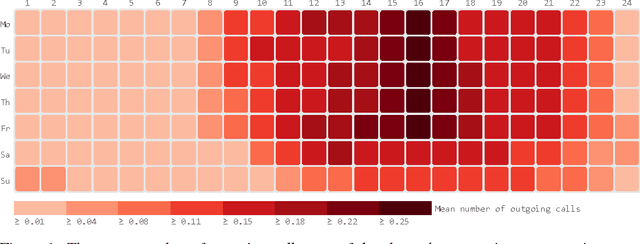
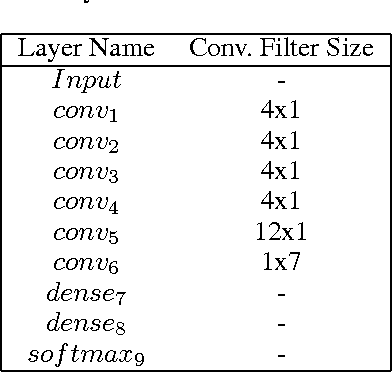
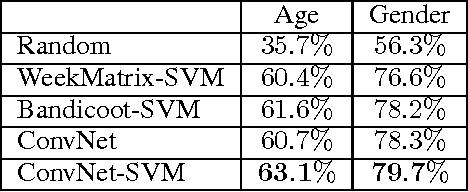

Mobile phone metadata is increasingly used for humanitarian purposes in developing countries as traditional data is scarce. Basic demographic information is however often absent from mobile phone datasets, limiting the operational impact of the datasets. For these reasons, there has been a growing interest in predicting demographic information from mobile phone metadata. Previous work focused on creating increasingly advanced features to be modeled with standard machine learning algorithms. We here instead model the raw mobile phone metadata directly using deep learning, exploiting the temporal nature of the patterns in the data. From high-level assumptions we design a data representation and convolutional network architecture for modeling patterns within a week. We then examine three strategies for aggregating patterns across weeks and show that our method reaches state-of-the-art accuracy on both age and gender prediction using only the temporal modality in mobile metadata. We finally validate our method on low activity users and evaluate the modeling assumptions.
Can mobile usage predict illiteracy in a developing country?
Jul 05, 2016
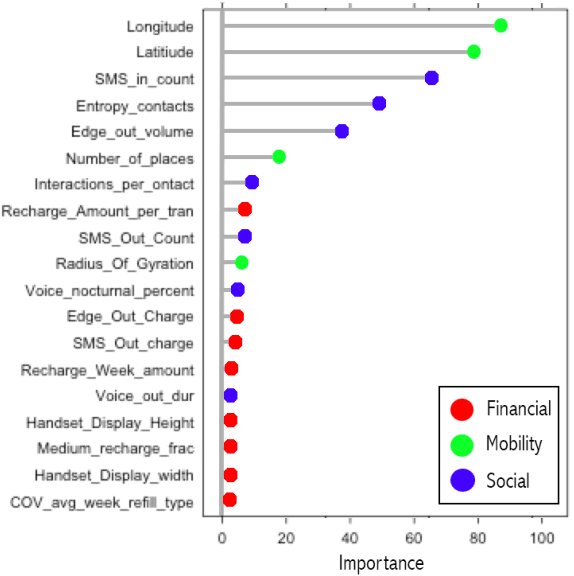


The present study provides the first evidence that illiteracy can be reliably predicted from standard mobile phone logs. By deriving a broad set of mobile phone indicators reflecting users financial, social and mobility patterns we show how supervised machine learning can be used to predict individual illiteracy in an Asian developing country, externally validated against a large-scale survey. On average the model performs 10 times better than random guessing with a 70% accuracy. Further we show how individual illiteracy can be aggregated and mapped geographically at cell tower resolution. Geographical mapping of illiteracy is crucial to know where the illiterate people are, and where to put in resources. In underdeveloped countries such mappings are often based on out-dated household surveys with low spatial and temporal resolution. One in five people worldwide struggle with illiteracy, and it is estimated that illiteracy costs the global economy more than 1 trillion dollars each year. These results potentially enable costeffective, questionnaire-free investigation of illiteracy-related questions on an unprecedented scale