 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan mobile usage predict illiteracy in a developing country?
Paper and Code
Jul 05, 2016
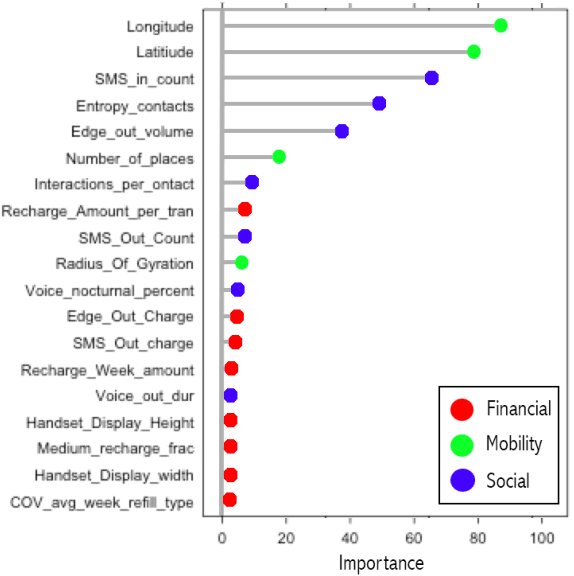


The present study provides the first evidence that illiteracy can be reliably predicted from standard mobile phone logs. By deriving a broad set of mobile phone indicators reflecting users financial, social and mobility patterns we show how supervised machine learning can be used to predict individual illiteracy in an Asian developing country, externally validated against a large-scale survey. On average the model performs 10 times better than random guessing with a 70% accuracy. Further we show how individual illiteracy can be aggregated and mapped geographically at cell tower resolution. Geographical mapping of illiteracy is crucial to know where the illiterate people are, and where to put in resources. In underdeveloped countries such mappings are often based on out-dated household surveys with low spatial and temporal resolution. One in five people worldwide struggle with illiteracy, and it is estimated that illiteracy costs the global economy more than 1 trillion dollars each year. These results potentially enable costeffective, questionnaire-free investigation of illiteracy-related questions on an unprecedented scale