 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActing Flatterers via LLMs Sycophancy: Combating Clickbait with LLMs Opposing-Stance Reasoning
Jan 17, 2026The widespread proliferation of online content has intensified concerns about clickbait, deceptive or exaggerated headlines designed to attract attention. While Large Language Models (LLMs) offer a promising avenue for addressing this issue, their effectiveness is often hindered by Sycophancy, a tendency to produce reasoning that matches users' beliefs over truthful ones, which deviates from instruction-following principles. Rather than treating sycophancy as a flaw to be eliminated, this work proposes a novel approach that initially harnesses this behavior to generate contrastive reasoning from opposing perspectives. Specifically, we design a Self-renewal Opposing-stance Reasoning Generation (SORG) framework that prompts LLMs to produce high-quality agree and disagree reasoning pairs for a given news title without requiring ground-truth labels. To utilize the generated reasoning, we develop a local Opposing Reasoning-based Clickbait Detection (ORCD) model that integrates three BERT encoders to represent the title and its associated reasoning. The model leverages contrastive learning, guided by soft labels derived from LLM-generated credibility scores, to enhance detection robustness. Experimental evaluations on three benchmark datasets demonstrate that our method consistently outperforms LLM prompting, fine-tuned smaller language models, and state-of-the-art clickbait detection baselines.
Chinese Morph Resolution in E-commerce Live Streaming Scenarios
Dec 29, 2025E-commerce live streaming in China, particularly on platforms like Douyin, has become a major sales channel, but hosts often use morphs to evade scrutiny and engage in false advertising. This study introduces the Live Auditory Morph Resolution (LiveAMR) task to detect such violations. Unlike previous morph research focused on text-based evasion in social media and underground industries, LiveAMR targets pronunciation-based evasion in health and medical live streams. We constructed the first LiveAMR dataset with 86,790 samples and developed a method to transform the task into a text-to-text generation problem. By leveraging large language models (LLMs) to generate additional training data, we improved performance and demonstrated that morph resolution significantly enhances live streaming regulation.
AI4Reading: Chinese Audiobook Interpretation System Based on Multi-Agent Collaboration
Dec 29, 2025Audiobook interpretations are attracting increasing attention, as they provide accessible and in-depth analyses of books that offer readers practical insights and intellectual inspiration. However, their manual creation process remains time-consuming and resource-intensive. To address this challenge, we propose AI4Reading, a multi-agent collaboration system leveraging large language models (LLMs) and speech synthesis technology to generate podcast, like audiobook interpretations. The system is designed to meet three key objectives: accurate content preservation, enhanced comprehensibility, and a logical narrative structure. To achieve these goals, we develop a framework composed of 11 specialized agents,including topic analysts, case analysts, editors, a narrator, and proofreaders that work in concert to explore themes, extract real world cases, refine content organization, and synthesize natural spoken language. By comparing expert interpretations with our system's output, the results show that although AI4Reading still has a gap in speech generation quality, the generated interpretative scripts are simpler and more accurate.
Is LLMs Hallucination Usable? LLM-based Negative Reasoning for Fake News Detection
Mar 12, 2025The questionable responses caused by knowledge hallucination may lead to LLMs' unstable ability in decision-making. However, it has never been investigated whether the LLMs' hallucination is possibly usable to generate negative reasoning for facilitating the detection of fake news. This study proposes a novel supervised self-reinforced reasoning rectification approach - SR$^3$ that yields both common reasonable reasoning and wrong understandings (negative reasoning) for news via LLMs reflection for semantic consistency learning. Upon that, we construct a negative reasoning-based news learning model called - \emph{NRFE}, which leverages positive or negative news-reasoning pairs for learning the semantic consistency between them. To avoid the impact of label-implicated reasoning, we deploy a student model - \emph{NRFE-D} that only takes news content as input to inspect the performance of our method by distilling the knowledge from \emph{NRFE}. The experimental results verified on three popular fake news datasets demonstrate the superiority of our method compared with three kinds of baselines including prompting on LLMs, fine-tuning on pre-trained SLMs, and other representative fake news detection methods.
Redefining Simplicity: Benchmarking Large Language Models from Lexical to Document Simplification
Feb 12, 2025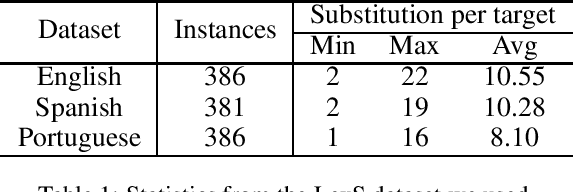

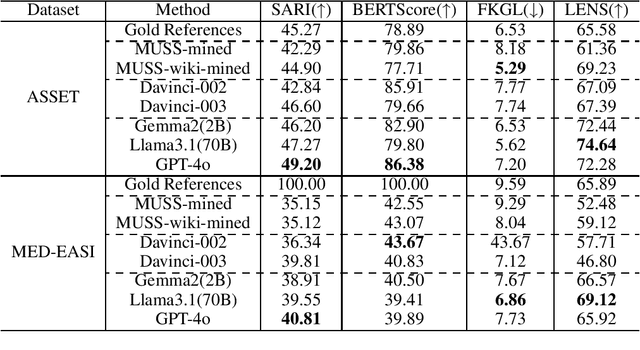
Text simplification (TS) refers to the process of reducing the complexity of a text while retaining its original meaning and key information. Existing work only shows that large language models (LLMs) have outperformed supervised non-LLM-based methods on sentence simplification. This study offers the first comprehensive analysis of LLM performance across four TS tasks: lexical, syntactic, sentence, and document simplification. We compare lightweight, closed-source and open-source LLMs against traditional non-LLM methods using automatic metrics and human evaluations. Our experiments reveal that LLMs not only outperform non-LLM approaches in all four tasks but also often generate outputs that exceed the quality of existing human-annotated references. Finally, we present some future directions of TS in the era of LLMs.
New Evaluation Paradigm for Lexical Simplification
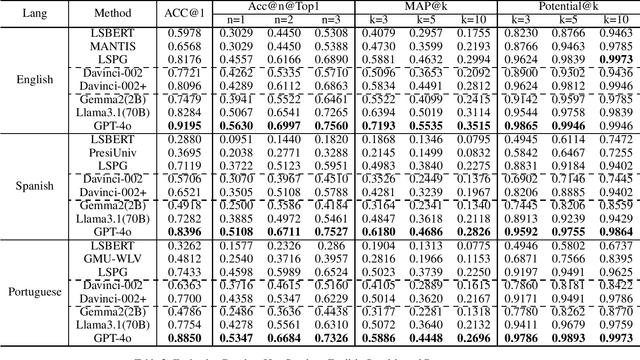
Jan 25, 2025Lexical Simplification (LS) methods use a three-step pipeline: complex word identification, substitute generation, and substitute ranking, each with separate evaluation datasets. We found large language models (LLMs) can simplify sentences directly with a single prompt, bypassing the traditional pipeline. However, existing LS datasets are not suitable for evaluating these LLM-generated simplified sentences, as they focus on providing substitutes for single complex words without identifying all complex words in a sentence. To address this gap, we propose a new annotation method for constructing an all-in-one LS dataset through human-machine collaboration. Automated methods generate a pool of potential substitutes, which human annotators then assess, suggesting additional alternatives as needed. Additionally, we explore LLM-based methods with single prompts, in-context learning, and chain-of-thought techniques. We introduce a multi-LLMs collaboration approach to simulate each step of the LS task. Experimental results demonstrate that LS based on multi-LLMs approaches significantly outperforms existing baselines.
Progressive Document-level Text Simplification via Large Language Models
Jan 07, 2025



Research on text simplification has primarily focused on lexical and sentence-level changes. Long document-level simplification (DS) is still relatively unexplored. Large Language Models (LLMs), like ChatGPT, have excelled in many natural language processing tasks. However, their performance on DS tasks is unsatisfactory, as they often treat DS as merely document summarization. For the DS task, the generated long sequences not only must maintain consistency with the original document throughout, but complete moderate simplification operations encompassing discourses, sentences, and word-level simplifications. Human editors employ a hierarchical complexity simplification strategy to simplify documents. This study delves into simulating this strategy through the utilization of a multi-stage collaboration using LLMs. We propose a progressive simplification method (ProgDS) by hierarchically decomposing the task, including the discourse-level, topic-level, and lexical-level simplification. Experimental results demonstrate that ProgDS significantly outperforms existing smaller models or direct prompting with LLMs, advancing the state-of-the-art in the document simplification task.
Prompt-tuning for Clickbait Detection via Text Summarization
Apr 17, 2024Clickbaits are surprising social posts or deceptive news headlines that attempt to lure users for more clicks, which have posted at unprecedented rates for more profit or commercial revenue. The spread of clickbait has significant negative impacts on the users, which brings users misleading or even click-jacking attacks. Different from fake news, the crucial problem in clickbait detection is determining whether the headline matches the corresponding content. Most existing methods compute the semantic similarity between the headlines and contents for detecting clickbait. However, due to significant differences in length and semantic features between headlines and contents, directly calculating semantic similarity is often difficult to summarize the relationship between them. To address this problem, we propose a prompt-tuning method for clickbait detection via text summarization in this paper, text summarization is introduced to summarize the contents, and clickbait detection is performed based on the similarity between the generated summary and the contents. Specifically, we first introduce a two-stage text summarization model to produce high-quality news summaries based on pre-trained language models, and then both the headlines and new generated summaries are incorporated as the inputs for prompt-tuning. Additionally, a variety of strategies are conducted to incorporate external knowledge for improving the performance of clickbait detection. The extensive experiments on well-known clickbait detection datasets demonstrate that our method achieved state-of-the-art performance.
Multilingual Lexical Simplification via Paraphrase Generation
Jul 28, 2023



Lexical simplification (LS) methods based on pretrained language models have made remarkable progress, generating potential substitutes for a complex word through analysis of its contextual surroundings. However, these methods require separate pretrained models for different languages and disregard the preservation of sentence meaning. In this paper, we propose a novel multilingual LS method via paraphrase generation, as paraphrases provide diversity in word selection while preserving the sentence's meaning. We regard paraphrasing as a zero-shot translation task within multilingual neural machine translation that supports hundreds of languages. After feeding the input sentence into the encoder of paraphrase modeling, we generate the substitutes based on a novel decoding strategy that concentrates solely on the lexical variations of the complex word. Experimental results demonstrate that our approach surpasses BERT-based methods and zero-shot GPT3-based method significantly on English, Spanish, and Portuguese.
Clickbait Detection via Large Language Models
Jun 16, 2023



Clickbait, which aims to induce users with some surprising and even thrilling headlines for increasing click-through rates, permeates almost all online content publishers, such as news portals and social media. Recently, Large Language Models (LLMs) have emerged as a powerful instrument and achieved tremendous success in a serious of NLP downstream tasks. However, it is not yet known whether LLMs can be served as a high-quality clickbait detection system. In this paper, we analyze the performance of LLMs in the few-shot scenarios on a number of English and Chinese benchmark datasets. Experimental results show that LLMs cannot achieve the best results compared to the state-of-the-art deep and fine-tuning PLMs methods. Different from the human intuition, the experiments demonstrated that LLMs cannot make satisfied clickbait detection just by the headlines.