 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActing Flatterers via LLMs Sycophancy: Combating Clickbait with LLMs Opposing-Stance Reasoning
Jan 17, 2026The widespread proliferation of online content has intensified concerns about clickbait, deceptive or exaggerated headlines designed to attract attention. While Large Language Models (LLMs) offer a promising avenue for addressing this issue, their effectiveness is often hindered by Sycophancy, a tendency to produce reasoning that matches users' beliefs over truthful ones, which deviates from instruction-following principles. Rather than treating sycophancy as a flaw to be eliminated, this work proposes a novel approach that initially harnesses this behavior to generate contrastive reasoning from opposing perspectives. Specifically, we design a Self-renewal Opposing-stance Reasoning Generation (SORG) framework that prompts LLMs to produce high-quality agree and disagree reasoning pairs for a given news title without requiring ground-truth labels. To utilize the generated reasoning, we develop a local Opposing Reasoning-based Clickbait Detection (ORCD) model that integrates three BERT encoders to represent the title and its associated reasoning. The model leverages contrastive learning, guided by soft labels derived from LLM-generated credibility scores, to enhance detection robustness. Experimental evaluations on three benchmark datasets demonstrate that our method consistently outperforms LLM prompting, fine-tuned smaller language models, and state-of-the-art clickbait detection baselines.
Explainability-Guided Defense: Attribution-Aware Model Refinement Against Adversarial Data Attacks
Jan 02, 2026The growing reliance on deep learning models in safety-critical domains such as healthcare and autonomous navigation underscores the need for defenses that are both robust to adversarial perturbations and transparent in their decision-making. In this paper, we identify a connection between interpretability and robustness that can be directly leveraged during training. Specifically, we observe that spurious, unstable, or semantically irrelevant features identified through Local Interpretable Model-Agnostic Explanations (LIME) contribute disproportionately to adversarial vulnerability. Building on this insight, we introduce an attribution-guided refinement framework that transforms LIME from a passive diagnostic into an active training signal. Our method systematically suppresses spurious features using feature masking, sensitivity-aware regularization, and adversarial augmentation in a closed-loop refinement pipeline. This approach does not require additional datasets or model architectures and integrates seamlessly into standard adversarial training. Theoretically, we derive an attribution-aware lower bound on adversarial distortion that formalizes the link between explanation alignment and robustness. Empirical evaluations on CIFAR-10, CIFAR-10-C, and CIFAR-100 demonstrate substantial improvements in adversarial robustness and out-of-distribution generalization.
AI4Reading: Chinese Audiobook Interpretation System Based on Multi-Agent Collaboration
Dec 29, 2025Audiobook interpretations are attracting increasing attention, as they provide accessible and in-depth analyses of books that offer readers practical insights and intellectual inspiration. However, their manual creation process remains time-consuming and resource-intensive. To address this challenge, we propose AI4Reading, a multi-agent collaboration system leveraging large language models (LLMs) and speech synthesis technology to generate podcast, like audiobook interpretations. The system is designed to meet three key objectives: accurate content preservation, enhanced comprehensibility, and a logical narrative structure. To achieve these goals, we develop a framework composed of 11 specialized agents,including topic analysts, case analysts, editors, a narrator, and proofreaders that work in concert to explore themes, extract real world cases, refine content organization, and synthesize natural spoken language. By comparing expert interpretations with our system's output, the results show that although AI4Reading still has a gap in speech generation quality, the generated interpretative scripts are simpler and more accurate.
RepText: Rendering Visual Text via Replicating
Apr 28, 2025Although contemporary text-to-image generation models have achieved remarkable breakthroughs in producing visually appealing images, their capacity to generate precise and flexible typographic elements, especially non-Latin alphabets, remains constrained. To address these limitations, we start from an naive assumption that text understanding is only a sufficient condition for text rendering, but not a necessary condition. Based on this, we present RepText, which aims to empower pre-trained monolingual text-to-image generation models with the ability to accurately render, or more precisely, replicate, multilingual visual text in user-specified fonts, without the need to really understand them. Specifically, we adopt the setting from ControlNet and additionally integrate language agnostic glyph and position of rendered text to enable generating harmonized visual text, allowing users to customize text content, font and position on their needs. To improve accuracy, a text perceptual loss is employed along with the diffusion loss. Furthermore, to stabilize rendering process, at the inference phase, we directly initialize with noisy glyph latent instead of random initialization, and adopt region masks to restrict the feature injection to only the text region to avoid distortion of the background. We conducted extensive experiments to verify the effectiveness of our RepText relative to existing works, our approach outperforms existing open-source methods and achieves comparable results to native multi-language closed-source models. To be more fair, we also exhaustively discuss its limitations in the end.
Is LLMs Hallucination Usable? LLM-based Negative Reasoning for Fake News Detection
Mar 12, 2025The questionable responses caused by knowledge hallucination may lead to LLMs' unstable ability in decision-making. However, it has never been investigated whether the LLMs' hallucination is possibly usable to generate negative reasoning for facilitating the detection of fake news. This study proposes a novel supervised self-reinforced reasoning rectification approach - SR$^3$ that yields both common reasonable reasoning and wrong understandings (negative reasoning) for news via LLMs reflection for semantic consistency learning. Upon that, we construct a negative reasoning-based news learning model called - \emph{NRFE}, which leverages positive or negative news-reasoning pairs for learning the semantic consistency between them. To avoid the impact of label-implicated reasoning, we deploy a student model - \emph{NRFE-D} that only takes news content as input to inspect the performance of our method by distilling the knowledge from \emph{NRFE}. The experimental results verified on three popular fake news datasets demonstrate the superiority of our method compared with three kinds of baselines including prompting on LLMs, fine-tuning on pre-trained SLMs, and other representative fake news detection methods.
Redefining Simplicity: Benchmarking Large Language Models from Lexical to Document Simplification
Feb 12, 2025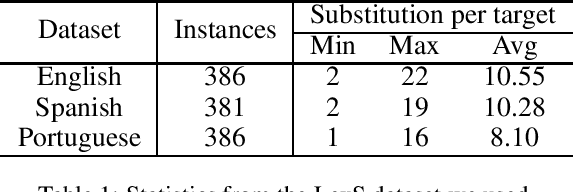

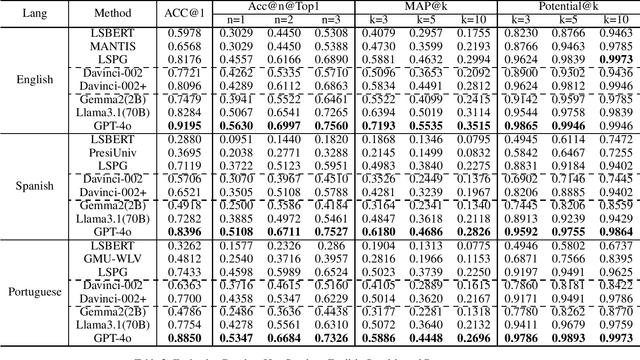
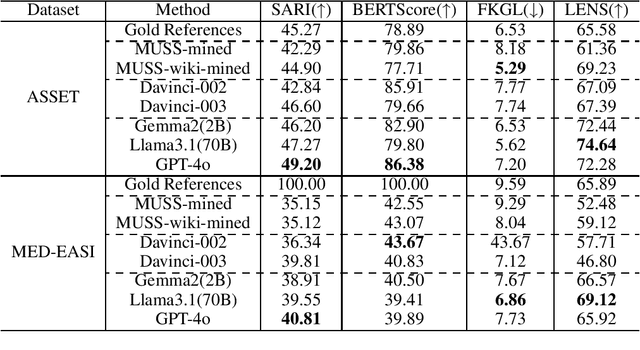
Text simplification (TS) refers to the process of reducing the complexity of a text while retaining its original meaning and key information. Existing work only shows that large language models (LLMs) have outperformed supervised non-LLM-based methods on sentence simplification. This study offers the first comprehensive analysis of LLM performance across four TS tasks: lexical, syntactic, sentence, and document simplification. We compare lightweight, closed-source and open-source LLMs against traditional non-LLM methods using automatic metrics and human evaluations. Our experiments reveal that LLMs not only outperform non-LLM approaches in all four tasks but also often generate outputs that exceed the quality of existing human-annotated references. Finally, we present some future directions of TS in the era of LLMs.
New Evaluation Paradigm for Lexical Simplification
Jan 25, 2025Lexical Simplification (LS) methods use a three-step pipeline: complex word identification, substitute generation, and substitute ranking, each with separate evaluation datasets. We found large language models (LLMs) can simplify sentences directly with a single prompt, bypassing the traditional pipeline. However, existing LS datasets are not suitable for evaluating these LLM-generated simplified sentences, as they focus on providing substitutes for single complex words without identifying all complex words in a sentence. To address this gap, we propose a new annotation method for constructing an all-in-one LS dataset through human-machine collaboration. Automated methods generate a pool of potential substitutes, which human annotators then assess, suggesting additional alternatives as needed. Additionally, we explore LLM-based methods with single prompts, in-context learning, and chain-of-thought techniques. We introduce a multi-LLMs collaboration approach to simulate each step of the LS task. Experimental results demonstrate that LS based on multi-LLMs approaches significantly outperforms existing baselines.
Chinese Idiom Paraphrasing
Apr 20, 2022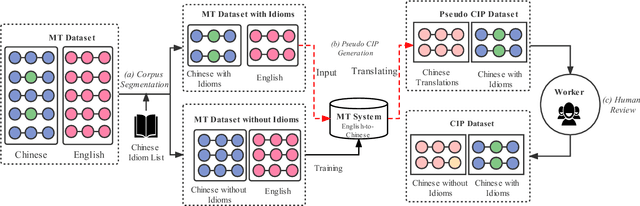
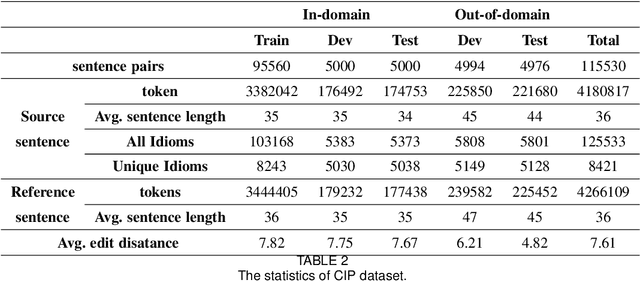
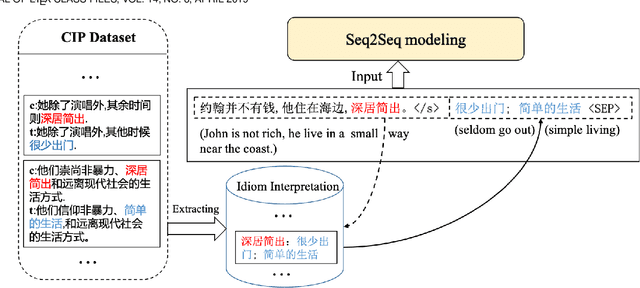

Idioms, are a kind of idiomatic expression in Chinese, most of which consist of four Chinese characters. Due to the properties of non-compositionality and metaphorical meaning, Chinese Idioms are hard to be understood by children and non-native speakers. This study proposes a novel task, denoted as Chinese Idiom Paraphrasing (CIP). CIP aims to rephrase idioms-included sentences to non-idiomatic ones under the premise of preserving the original sentence's meaning. Since the sentences without idioms are easier handled by Chinese NLP systems, CIP can be used to pre-process Chinese datasets, thereby facilitating and improving the performance of Chinese NLP tasks, e.g., machine translation system, Chinese idiom cloze, and Chinese idiom embeddings. In this study, CIP task is treated as a special paraphrase generation task. To circumvent difficulties in acquiring annotations, we first establish a large-scale CIP dataset based on human and machine collaboration, which consists of 115,530 sentence pairs. We further deploy three baselines and two novel CIP approaches to deal with CIP problems. The results show that the proposed methods have better performances than the baselines based on the established CIP dataset.