 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionMAC: Deformation-Free Fashion Image Generation with Fine-Grained Model Appearance Customization
Nov 18, 2025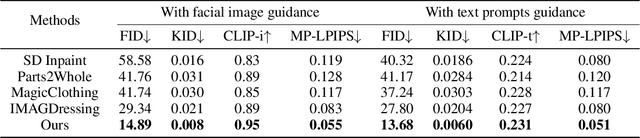
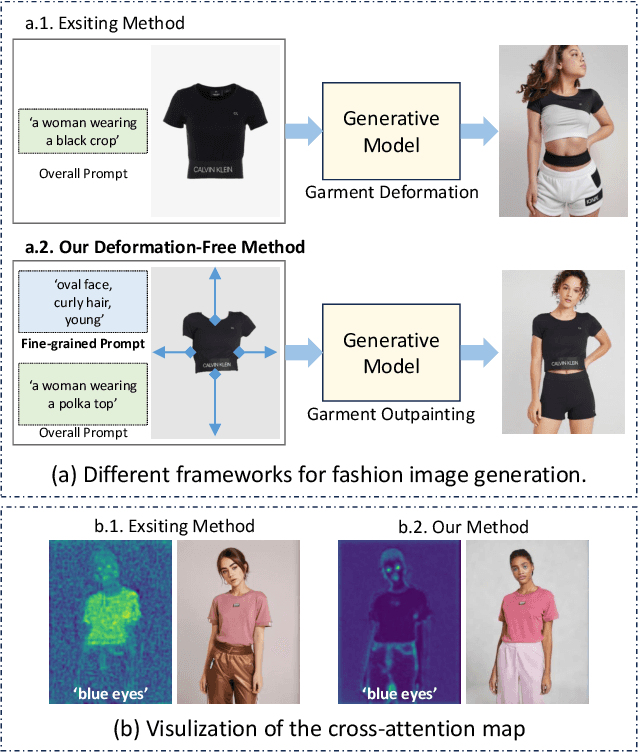

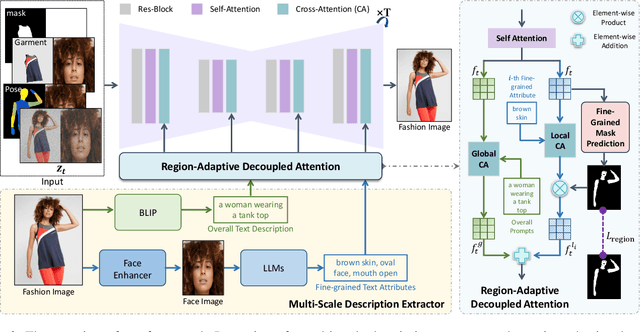
Garment-centric fashion image generation aims to synthesize realistic and controllable human models dressing a given garment, which has attracted growing interest due to its practical applications in e-commerce. The key challenges of the task lie in two aspects: (1) faithfully preserving the garment details, and (2) gaining fine-grained controllability over the model's appearance. Existing methods typically require performing garment deformation in the generation process, which often leads to garment texture distortions. Also, they fail to control the fine-grained attributes of the generated models, due to the lack of specifically designed mechanisms. To address these issues, we propose FashionMAC, a novel diffusion-based deformation-free framework that achieves high-quality and controllable fashion showcase image generation. The core idea of our framework is to eliminate the need for performing garment deformation and directly outpaint the garment segmented from a dressed person, which enables faithful preservation of the intricate garment details. Moreover, we propose a novel region-adaptive decoupled attention (RADA) mechanism along with a chained mask injection strategy to achieve fine-grained appearance controllability over the synthesized human models. Specifically, RADA adaptively predicts the generated regions for each fine-grained text attribute and enforces the text attribute to focus on the predicted regions by a chained mask injection strategy, significantly enhancing the visual fidelity and the controllability. Extensive experiments validate the superior performance of our framework compared to existing state-of-the-art methods.
Supporting renewable energy planning and operation with data-driven high-resolution ensemble weather forecast
May 07, 2025The planning and operation of renewable energy, especially wind power, depend crucially on accurate, timely, and high-resolution weather information. Coarse-grid global numerical weather forecasts are typically downscaled to meet these requirements, introducing challenges of scale inconsistency, process representation error, computation cost, and entanglement of distinct uncertainty sources from chaoticity, model bias, and large-scale forcing. We address these challenges by learning the climatological distribution of a target wind farm using its high-resolution numerical weather simulations. An optimal combination of this learned high-resolution climatological prior with coarse-grid large scale forecasts yields highly accurate, fine-grained, full-variable, large ensemble of weather pattern forecasts. Using observed meteorological records and wind turbine power outputs as references, the proposed methodology verifies advantageously compared to existing numerical/statistical forecasting-downscaling pipelines, regarding either deterministic/probabilistic skills or economic gains. Moreover, a 100-member, 10-day forecast with spatial resolution of 1 km and output frequency of 15 min takes < 1 hour on a moderate-end GPU, as contrast to $\mathcal{O}(10^3)$ CPU hours for conventional numerical simulation. By drastically reducing computational costs while maintaining accuracy, our method paves the way for more efficient and reliable renewable energy planning and operation.
Generative assimilation and prediction for weather and climate
Mar 04, 2025Machine learning models have shown great success in predicting weather up to two weeks ahead, outperforming process-based benchmarks. However, existing approaches mostly focus on the prediction task, and do not incorporate the necessary data assimilation. Moreover, these models suffer from error accumulation in long roll-outs, limiting their applicability to seasonal predictions or climate projections. Here, we introduce Generative Assimilation and Prediction (GAP), a unified deep generative framework for assimilation and prediction of both weather and climate. By learning to quantify the probabilistic distribution of atmospheric states under observational, predictive, and external forcing constraints, GAP excels in a broad range of weather-climate related tasks, including data assimilation, seamless prediction, and climate simulation. In particular, GAP is competitive with state-of-the-art ensemble assimilation, probabilistic weather forecast and seasonal prediction, yields stable millennial simulations, and reproduces climate variability from daily to decadal time scales.
Fine-Grained Controllable Apparel Showcase Image Generation via Garment-Centric Outpainting
Mar 03, 2025In this paper, we propose a novel garment-centric outpainting (GCO) framework based on the latent diffusion model (LDM) for fine-grained controllable apparel showcase image generation. The proposed framework aims at customizing a fashion model wearing a given garment via text prompts and facial images. Different from existing methods, our framework takes a garment image segmented from a dressed mannequin or a person as the input, eliminating the need for learning cloth deformation and ensuring faithful preservation of garment details. The proposed framework consists of two stages. In the first stage, we introduce a garment-adaptive pose prediction model that generates diverse poses given the garment. Then, in the next stage, we generate apparel showcase images, conditioned on the garment and the predicted poses, along with specified text prompts and facial images. Notably, a multi-scale appearance customization module (MS-ACM) is designed to allow both overall and fine-grained text-based control over the generated model's appearance. Moreover, we leverage a lightweight feature fusion operation without introducing any extra encoders or modules to integrate multiple conditions, which is more efficient. Extensive experiments validate the superior performance of our framework compared to state-of-the-art methods.