 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvX: Agentize Everything with Agentic AI
Sep 09, 2025


The widespread availability of open-source repositories has led to a vast collection of reusable software components, yet their utilization remains manual, error-prone, and disconnected. Developers must navigate documentation, understand APIs, and write integration code, creating significant barriers to efficient software reuse. To address this, we present EnvX, a framework that leverages Agentic AI to agentize GitHub repositories, transforming them into intelligent, autonomous agents capable of natural language interaction and inter-agent collaboration. Unlike existing approaches that treat repositories as static code resources, EnvX reimagines them as active agents through a three-phase process: (1) TODO-guided environment initialization, which sets up the necessary dependencies, data, and validation datasets; (2) human-aligned agentic automation, allowing repository-specific agents to autonomously perform real-world tasks; and (3) Agent-to-Agent (A2A) protocol, enabling multiple agents to collaborate. By combining large language model capabilities with structured tool integration, EnvX automates not just code generation, but the entire process of understanding, initializing, and operationalizing repository functionality. We evaluate EnvX on the GitTaskBench benchmark, using 18 repositories across domains such as image processing, speech recognition, document analysis, and video manipulation. Our results show that EnvX achieves a 74.07% execution completion rate and 51.85% task pass rate, outperforming existing frameworks. Case studies further demonstrate EnvX's ability to enable multi-repository collaboration via the A2A protocol. This work marks a shift from treating repositories as passive code resources to intelligent, interactive agents, fostering greater accessibility and collaboration within the open-source ecosystem.
The Avengers: A Simple Recipe for Uniting Smaller Language Models to Challenge Proprietary Giants
May 26, 2025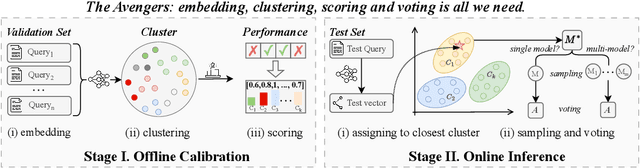
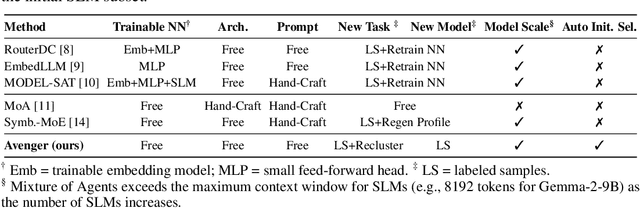
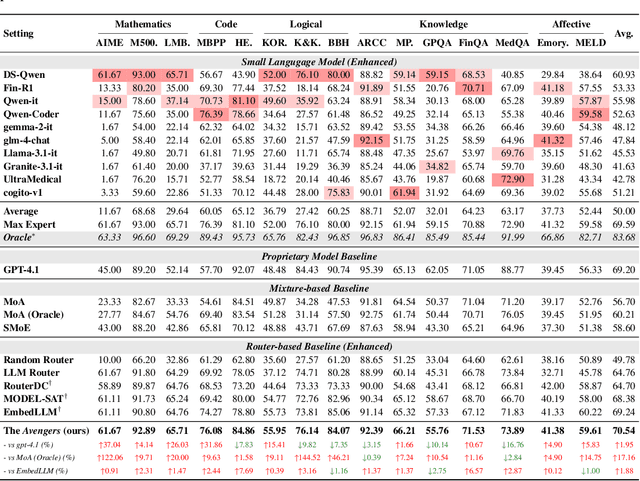
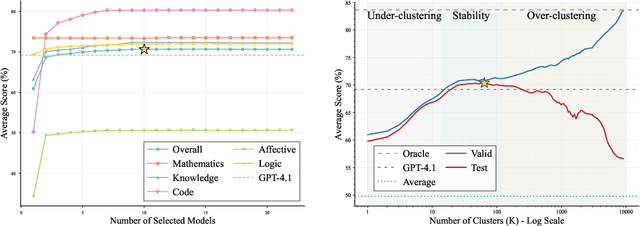
As proprietary giants increasingly dominate the race for ever-larger language models, a pressing question arises for the open-source community: can smaller models remain competitive across a broad range of tasks? In this paper, we present the Avengers--a simple recipe that effectively leverages the collective intelligence of open-source, smaller language models. Our framework is built upon four lightweight operations: (i) embedding: encode queries using a text embedding model; (ii) clustering: group queries based on their semantic similarity; (iii) scoring: scores each model's performance within each cluster; and (iv) voting: improve outputs via repeated sampling and voting. At inference time, each query is embedded and assigned to its nearest cluster. The top-performing model(s) within that cluster are selected to generate the response using the Self-Consistency or its multi-model variant. Remarkably, with 10 open-source models (~7B parameters each), the Avengers collectively outperforms GPT-4.1 on 10 out of 15 datasets (spanning mathematics, code, logic, knowledge, and affective tasks). In particular, it surpasses GPT-4.1 on mathematics tasks by 18.21% and on code tasks by 7.46%. Furthermore, the Avengers delivers superior out-of-distribution generalization, and remains robust across various embedding models, clustering algorithms, ensemble strategies, and values of its sole parameter--the number of clusters. We have open-sourced the code on GitHub: https://github.com/ZhangYiqun018/Avengers
Finding the Sweet Spot: Preference Data Construction for Scaling Preference Optimization
Feb 24, 2025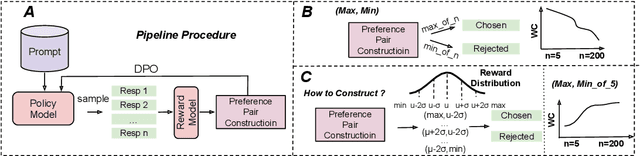
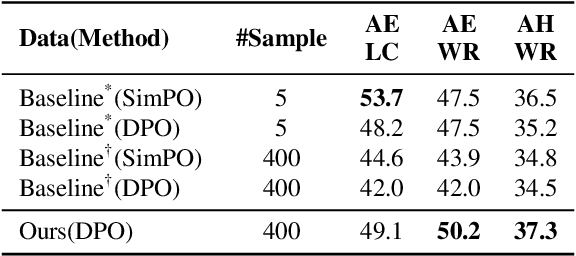
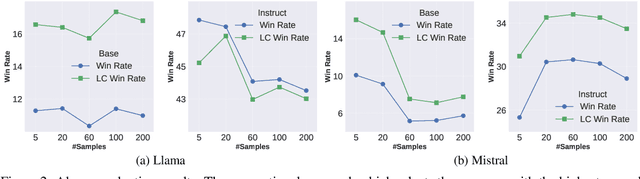
Iterative data generation and model retraining are widely used to align large language models (LLMs). It typically involves a policy model to generate on-policy responses and a reward model to guide training data selection. Direct Preference Optimization (DPO) further enhances this process by constructing preference pairs of chosen and rejected responses. In this work, we aim to \emph{scale up} the number of on-policy samples via repeated random sampling to improve alignment performance. Conventional practice selects the sample with the highest reward as chosen and the lowest as rejected for DPO. However, our experiments reveal that this strategy leads to a \emph{decline} in performance as the sample size increases. To address this, we investigate preference data construction through the lens of underlying normal distribution of sample rewards. We categorize the reward space into seven representative points and systematically explore all 21 ($C_7^2$) pairwise combinations. Through evaluations on four models using AlpacaEval 2, we find that selecting the rejected response at reward position $\mu - 2\sigma$ rather than the minimum reward, is crucial for optimal performance. We finally introduce a scalable preference data construction strategy that consistently enhances model performance as the sample scale increases.
SensorLLM: Aligning Large Language Models with Motion Sensors for Human Activity Recognition
Oct 14, 2024In this work, we bridge the gap between wearable sensor technology and personalized AI assistants by enabling Large Language Models (LLMs) to understand time-series tasks like human activity recognition (HAR). Despite the strong reasoning and generalization capabilities of LLMs, leveraging them for sensor data tasks remains largely unexplored. This gap stems from challenges like the lack of semantic context in time-series data, computational limitations, and LLMs' difficulty processing numerical inputs. To address these issues, we introduce SensorLLM, a two-stage framework to unlock LLMs' potential for sensor data tasks. In the Sensor-Language Alignment Stage, we introduce special tokens for each sensor channel and automatically generate trend-descriptive text to align sensor data with textual inputs, enabling SensorLLM to capture numerical changes, channel-specific information, and sensor data of varying lengths-capabilities that existing LLMs typically struggle with, all without the need for human annotations. Next, in Task-Aware Tuning Stage, we refine the model for HAR classification using the frozen LLM and alignment module, achieving performance on par with or surpassing state-of-the-art models. We further demonstrate that SensorLLM evolves into an effective sensor learner, reasoner, and classifier through Sensor-Language Alignment, enabling it to generalize across diverse datasets for HAR tasks. We strongly believe our work lays the stepstone for future time-series and text alignment research, offering a path toward foundation models for sensor data.
CRAB: Cross-environment Agent Benchmark for Multimodal Language Model Agents
Jul 01, 2024



The development of autonomous agents increasingly relies on Multimodal Language Models (MLMs) to perform tasks described in natural language with GUI environments, such as websites, desktop computers, or mobile phones. Existing benchmarks for MLM agents in interactive environments are limited by their focus on a single environment, lack of detailed and generalized evaluation methods, and the complexities of constructing tasks and evaluators. To overcome these limitations, we introduce Crab, the first agent benchmark framework designed to support cross-environment tasks, incorporating a graph-based fine-grained evaluation method and an efficient mechanism for task and evaluator construction. Our framework supports multiple devices and can be easily extended to any environment with a Python interface. Leveraging Crab, we developed a cross-platform Crab Benchmark-v0 comprising 100 tasks in computer desktop and mobile phone environments. We evaluated four advanced MLMs using different single and multi-agent system configurations on this benchmark. The experimental results demonstrate that the single agent with GPT-4o achieves the best completion ratio of 35.26%. All framework code, agent code, and task datasets are publicly available at https://github.com/camel-ai/crab.
XDLM: Cross-lingual Diffusion Language Model for Machine Translation
Jul 31, 2023



Recently, diffusion models have excelled in image generation tasks and have also been applied to neural language processing (NLP) for controllable text generation. However, the application of diffusion models in a cross-lingual setting is less unexplored. Additionally, while pretraining with diffusion models has been studied within a single language, the potential of cross-lingual pretraining remains understudied. To address these gaps, we propose XDLM, a novel Cross-lingual diffusion model for machine translation, consisting of pretraining and fine-tuning stages. In the pretraining stage, we propose TLDM, a new training objective for mastering the mapping between different languages; in the fine-tuning stage, we build up the translation system based on the pretrained model. We evaluate the result on several machine translation benchmarks and outperformed both diffusion and Transformer baselines.