 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMini-InternVL: A Flexible-Transfer Pocket Multimodal Model with 5% Parameters and 90% Performance
Paper and Code
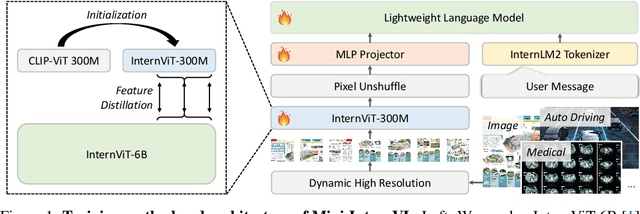
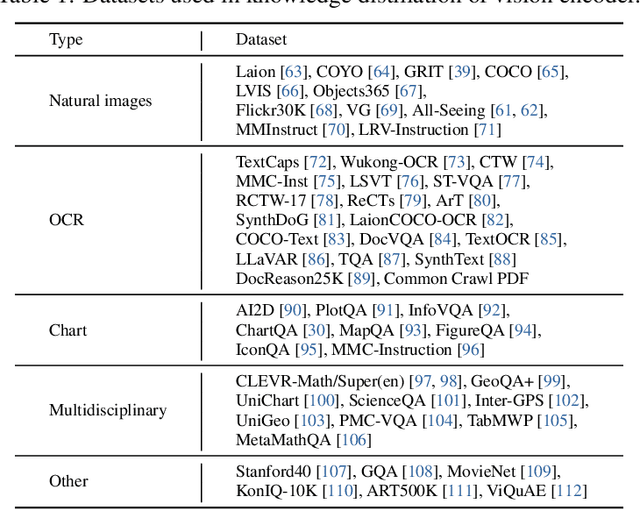
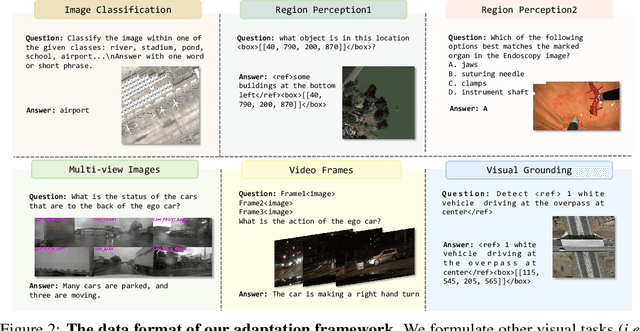
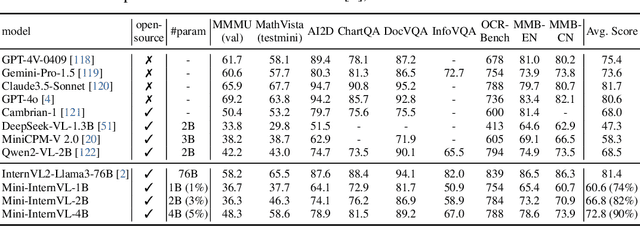
Multimodal large language models (MLLMs) have demonstrated impressive performance in vision-language tasks across a broad spectrum of domains. However, the large model scale and associated high computational costs pose significant challenges for training and deploying MLLMs on consumer-grade GPUs or edge devices, thereby hindering their widespread application. In this work, we introduce Mini-InternVL, a series of MLLMs with parameters ranging from 1B to 4B, which achieves 90% of the performance with only 5% of the parameters. This significant improvement in efficiency and effectiveness makes our models more accessible and applicable in various real-world scenarios. To further promote the adoption of our models, we develop a unified adaptation framework for Mini-InternVL, which enables our models to transfer and outperform specialized models in downstream tasks, including autonomous driving, medical images, and remote sensing. We believe that our study can provide valuable insights and resources to advance the development of efficient and effective MLLMs. Code is available at https://github.com/OpenGVLab/InternVL.