 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Domain Image Translation: More Photo-realistic, Better Identity-preserving
Paper and Code

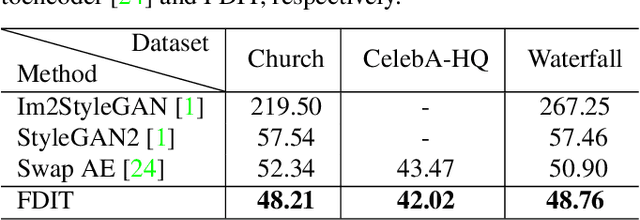
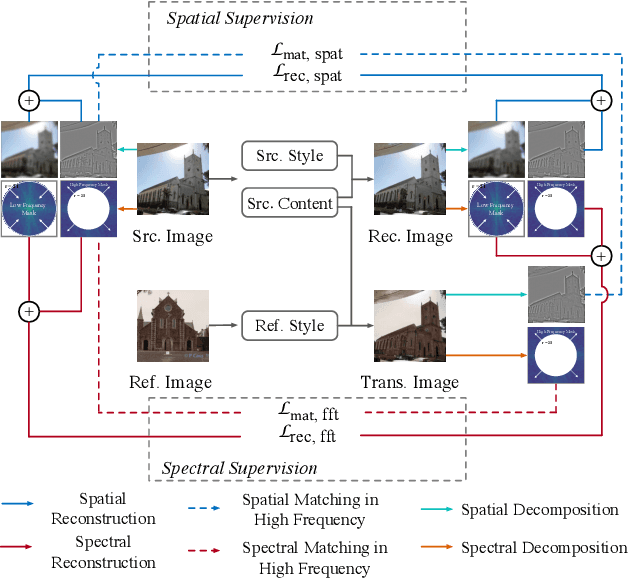
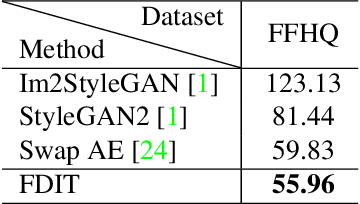
Image-to-image translation aims at translating a particular style of an image to another. The synthesized images can be more photo-realistic and identity-preserving by decomposing the image into content and style in a disentangled manner. While existing models focus on designing specialized network architecture to separate the two components, this paper investigates how to explicitly constrain the content and style statistics of images. We achieve this goal by transforming the input image into high frequency and low frequency information, which correspond to the content and style, respectively. We regulate the frequency distribution from two aspects: a) a spatial level restriction to locally restrict the frequency distribution of images; b) a spectral level regulation to enhance the global consistency among images. On multiple datasets we show that the proposed approach consistently leads to significant improvements on top of various state-of-the-art image translation models.