 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Instance Selection Strategies in Self-training for Sentiment Analysis
Sep 15, 2023



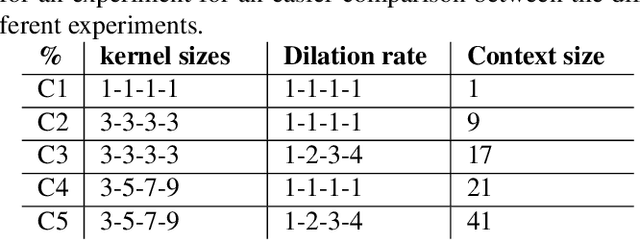
Sentiment analysis is a crucial task in natural language processing that involves identifying and extracting subjective sentiment from text. Self-training has recently emerged as an economical and efficient technique for developing sentiment analysis models by leveraging a small amount of labeled data and a larger amount of unlabeled data. However, the performance of a self-training procedure heavily relies on the choice of the instance selection strategy, which has not been studied thoroughly. This paper presents an empirical study on various instance selection strategies for self-training on two public sentiment datasets, and investigates the influence of the strategy and hyper-parameters on the performance of self-training in various few-shot settings.
Switch Point biased Self-Training: Re-purposing Pretrained Models for Code-Switching
Nov 01, 2021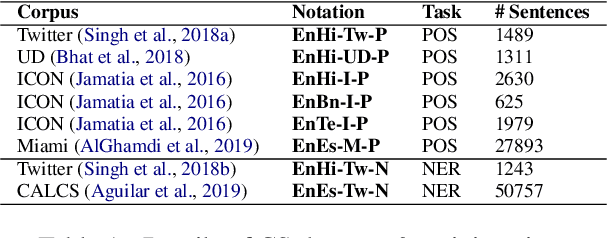

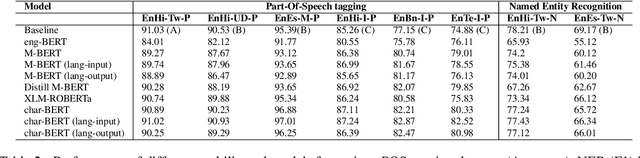
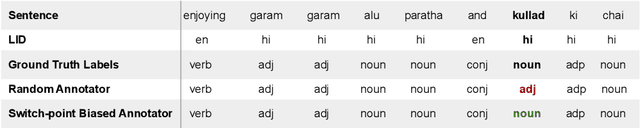
Code-switching (CS), a ubiquitous phenomenon due to the ease of communication it offers in multilingual communities still remains an understudied problem in language processing. The primary reasons behind this are: (1) minimal efforts in leveraging large pretrained multilingual models, and (2) the lack of annotated data. The distinguishing case of low performance of multilingual models in CS is the intra-sentence mixing of languages leading to switch points. We first benchmark two sequence labeling tasks -- POS and NER on 4 different language pairs with a suite of pretrained models to identify the problems and select the best performing model, char-BERT, among them (addressing (1)). We then propose a self training method to repurpose the existing pretrained models using a switch-point bias by leveraging unannotated data (addressing (2)). We finally demonstrate that our approach performs well on both tasks by reducing the gap between the switch point performance while retaining the overall performance on two distinct language pairs in both the tasks. Our code is available here: https://github.com/PC09/EMNLP2021-Switch-Point-biased-Self-Training.
Intent Classification Using Pre-Trained Embeddings For Low Resource Languages
Oct 18, 2021
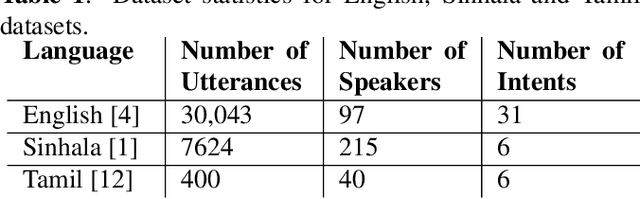

Building Spoken Language Understanding (SLU) systems that do not rely on language specific Automatic Speech Recognition (ASR) is an important yet less explored problem in language processing. In this paper, we present a comparative study aimed at employing a pre-trained acoustic model to perform SLU in low resource scenarios. Specifically, we use three different embeddings extracted using Allosaurus, a pre-trained universal phone decoder: (1) Phone (2) Panphone, and (3) Allo embeddings. These embeddings are then used in identifying the spoken intent. We perform experiments across three different languages: English, Sinhala, and Tamil each with different data sizes to simulate high, medium, and low resource scenarios. Our system improves on the state-of-the-art (SOTA) intent classification accuracy by approximately 2.11% for Sinhala and 7.00% for Tamil and achieves competitive results on English. Furthermore, we present a quantitative analysis of how the performance scales with the number of training examples used per intent.
Intent Recognition and Unsupervised Slot Identification for Low Resourced Spoken Dialog Systems
Apr 03, 2021



Intent Recognition and Slot Identification are crucial components in spoken language understanding (SLU) systems. In this paper, we present a novel approach towards both these tasks in the context of low resourced and unwritten languages. We present an acoustic based SLU system that converts speech to its phonetic transcription using a universal phone recognition system. We build a word-free natural language understanding module that does intent recognition and slot identification from these phonetic transcription. Our proposed SLU system performs competitively for resource rich scenarios and significantly outperforms existing approaches as the amount of available data reduces. We observe more than 10% improvement for intent classification in Tamil and more than 5% improvement for intent classification in Sinhala. We also present a novel approach towards unsupervised slot identification using normalized attention scores. This approach can be used for unsupervised slot labelling, data augmentation and to generate data for a new slot in a one-shot way with only one speech recording
Unsupervised Self-Training for Sentiment Analysis of Code-Switched Data
Mar 27, 2021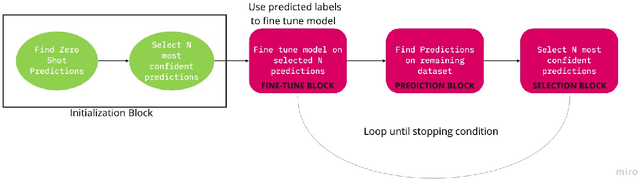



Sentiment analysis is an important task in understanding social media content like customer reviews, Twitter and Facebook feeds etc. In multilingual communities around the world, a large amount of social media text is characterized by the presence of Code-Switching. Thus, it has become important to build models that can handle code-switched data. However, annotated code-switched data is scarce and there is a need for unsupervised models and algorithms. We propose a general framework called Unsupervised Self-Training and show its applications for the specific use case of sentiment analysis of code-switched data. We use the power of pre-trained BERT models for initialization and fine-tune them in an unsupervised manner, only using pseudo labels produced by zero-shot transfer. We test our algorithm on multiple code-switched languages and provide a detailed analysis of the learning dynamics of the algorithm with the aim of answering the question - `Does our unsupervised model understand the Code-Switched languages or does it just learn its representations?'. Our unsupervised models compete well with their supervised counterparts, with their performance reaching within 1-7\% (weighted F1 scores) when compared to supervised models trained for a two class problem.
Task-Specific Pre-Training and Cross Lingual Transfer for Code-Switched Data
Feb 24, 2021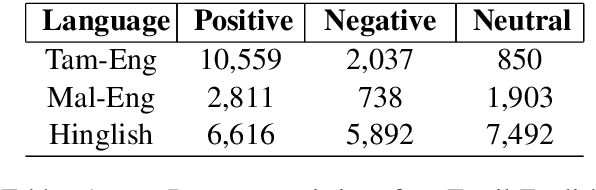
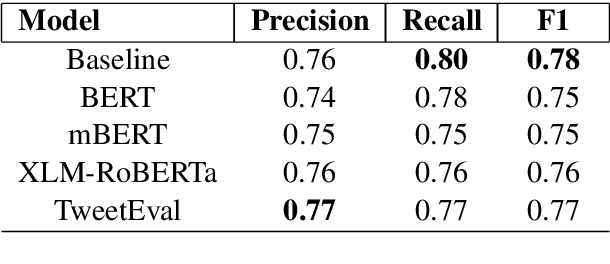
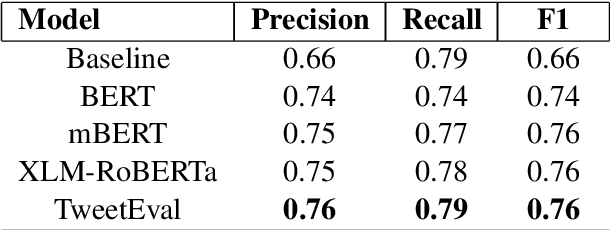
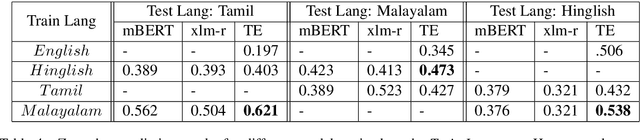
Using task-specific pre-training and leveraging cross-lingual transfer are two of the most popular ways to handle code-switched data. In this paper, we aim to compare the effects of both for the task of sentiment analysis. We work with two Dravidian Code-Switched languages - Tamil-Engish and Malayalam-English and four different BERT based models. We compare the effects of task-specific pre-training and cross-lingual transfer and find that task-specific pre-training results in superior zero-shot and supervised performance when compared to performance achieved by leveraging cross-lingual transfer from multilingual BERT models.
Acoustics Based Intent Recognition Using Discovered Phonetic Units for Low Resource Languages
Nov 07, 2020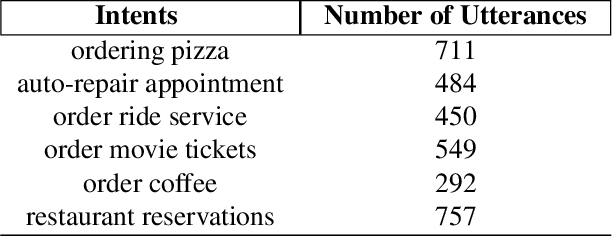

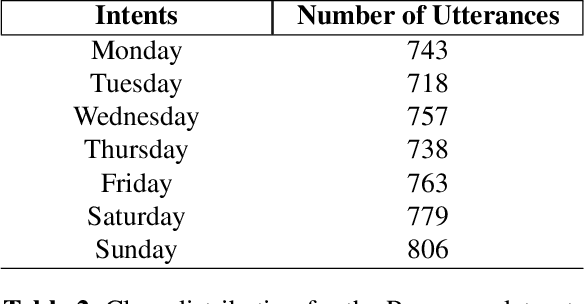
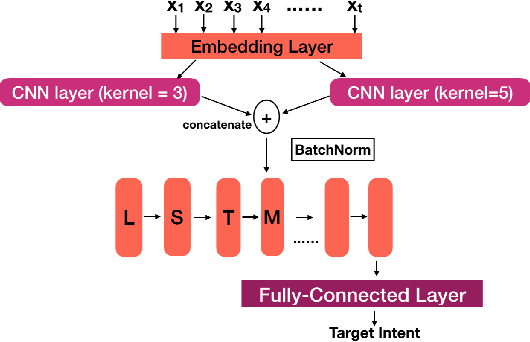
With recent advancements in language technologies, humansare now interacting with technology through speech. To in-crease the reach of these technologies, we need to build suchsystems in local languages. A major bottleneck here are theunderlying data-intensive parts that make up such systems,including automatic speech recognition (ASR) systems thatrequire large amounts of labelled data. With the aim of aidingdevelopment of dialog systems in low resourced languages,we propose a novel acoustics based intent recognition systemthat uses discovered phonetic units for intent classification.The system is made up of two blocks - the first block gen-erates a transcript of discovered phonetic units for the inputaudio, and the second block which performs intent classifi-cation from the generated phonemic transcripts. Our workpresents results for such a system for two languages families- Indic languages and Romance languages, for two differentintent recognition tasks. We also perform multilingual train-ing of our intent classifier and show improved cross-lingualtransfer and performance on an unknown language with zeroresources in the same language family.
A Resource for Computational Experiments on Mapudungun
Dec 04, 2019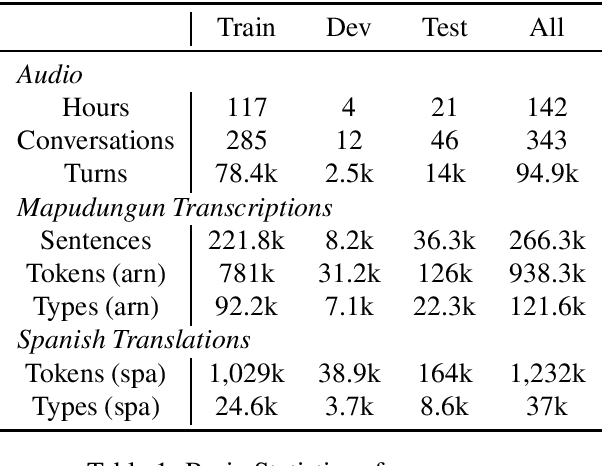

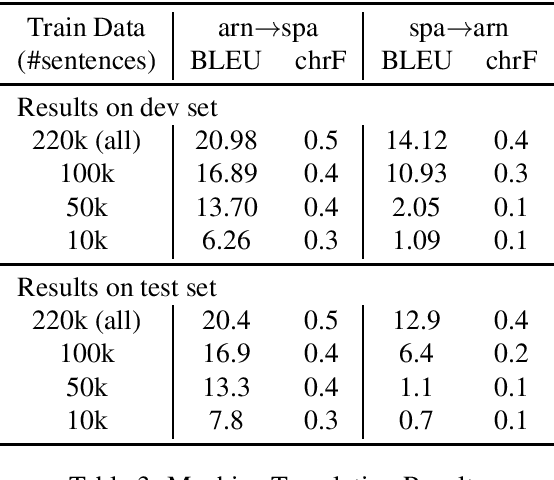
We present a resource for computational experiments on Mapudungun, a polysynthetic indigenous language spoken in Chile with upwards of 200 thousand speakers. We provide 142 hours of culturally significant conversations in the domain of medical treatment. The conversations are fully transcribed and translated into Spanish. The transcriptions also include annotations for code-switching and non-standard pronunciations. We also provide baseline results on three core NLP tasks: speech recognition, speech synthesis, and machine translation between Spanish and Mapudungun. We further explore other applications for which the corpus will be suitable, including the study of code-switching, historical orthography change, linguistic structure, and sociological and anthropological studies.
Disentangling Speech and Non-Speech Components for Building Robust Acoustic Models from Found Data
Sep 25, 2019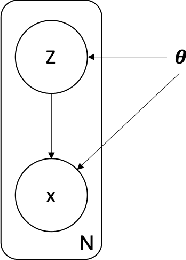
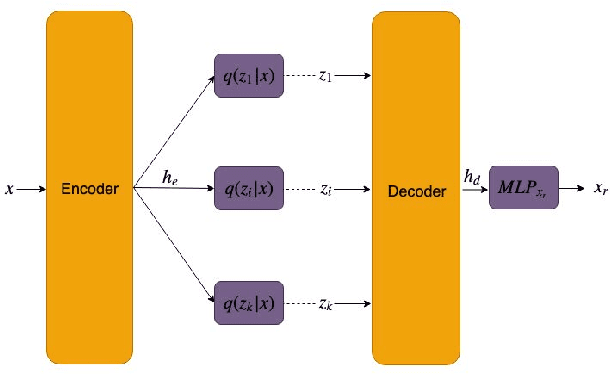
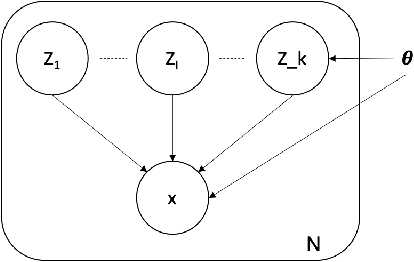
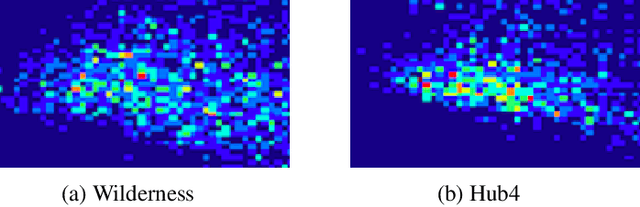
In order to build language technologies for majority of the languages, it is important to leverage the resources available in public domain on the internet - commonly referred to as `Found Data'. However, such data is characterized by the presence of non-standard, non-trivial variations. For instance, speech resources found on the internet have non-speech content, such as music. Therefore, speech recognition and speech synthesis models need to be robust to such variations. In this work, we present an analysis to show that it is important to disentangle the latent causal factors of variation in the original data to accomplish these tasks. Based on this, we present approaches to disentangle such variations from the data using Latent Stochastic Models. Specifically, we present a method to split the latent prior space into continuous representations of dominant speech modes present in the magnitude spectra of audio signals. We propose a completely unsupervised approach using multinode latent space variational autoencoders (VAE). We show that the constraints on the latent space of a VAE can be in-fact used to separate speech and music, independent of the language of the speech. This paper also analytically presents the requirement on the number of latent variables for the task based on distribution of the speech data.
A Survey of Code-switched Speech and Language Processing
Apr 02, 2019Code-switching, the alternation of languages within a conversation or utterance, is a common communicative phenomenon that occurs in multilingual communities across the world. This survey reviews computational approaches for code-switched Speech and Natural Language Processing. We motivate why processing code-switched text and speech is essential for building intelligent agents and systems that interact with users in multilingual communities. As code-switching data and resources are scarce, we list what is available in various code-switched language pairs with the language processing tasks they can be used for. We review code-switching research in various Speech and NLP applications, including language processing tools and end-to-end systems. We conclude with future directions and open problems in the field.