 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJetsons at FinNLP 2024: Towards Understanding the ESG Impact of a News Article using Transformer-based Models
Mar 30, 2024In this paper, we describe the different approaches explored by the Jetsons team for the Multi-Lingual ESG Impact Duration Inference (ML-ESG-3) shared task. The shared task focuses on predicting the duration and type of the ESG impact of a news article. The shared task dataset consists of 2,059 news titles and articles in English, French, Korean, and Japanese languages. For the impact duration classification task, we fine-tuned XLM-RoBERTa with a custom fine-tuning strategy and using self-training and DeBERTa-v3 using only English translations. These models individually ranked first on the leaderboard for Korean and Japanese and in an ensemble for the English language, respectively. For the impact type classification task, our XLM-RoBERTa model fine-tuned using a custom fine-tuning strategy ranked first for the English language.
BlendSQL: A Scalable Dialect for Unifying Hybrid Question Answering in Relational Algebra
Feb 27, 2024Many existing end-to-end systems for hybrid question answering tasks can often be boiled down to a "prompt-and-pray" paradigm, where the user has limited control and insight into the intermediate reasoning steps used to achieve the final result. Additionally, due to the context size limitation of many transformer-based LLMs, it is often not reasonable to expect that the full structured and unstructured context will fit into a given prompt in a zero-shot setting, let alone a few-shot setting. We introduce BlendSQL, a superset of SQLite to act as a unified dialect for orchestrating reasoning across both unstructured and structured data. For hybrid question answering tasks involving multi-hop reasoning, we encode the full decomposed reasoning roadmap into a single interpretable BlendSQL query. Notably, we show that BlendSQL can scale to massive datasets and improve the performance of end-to-end systems while using 35% fewer tokens. Our code is available and installable as a package at https://github.com/parkervg/blendsql.
Towards leveraging LLMs for Conditional QA
Dec 02, 2023This study delves into the capabilities and limitations of Large Language Models (LLMs) in the challenging domain of conditional question-answering. Utilizing the Conditional Question Answering (CQA) dataset and focusing on generative models like T5 and UL2, we assess the performance of LLMs across diverse question types. Our findings reveal that fine-tuned LLMs can surpass the state-of-the-art (SOTA) performance in some cases, even without fully encoding all input context, with an increase of 7-8 points in Exact Match (EM) and F1 scores for Yes/No questions. However, these models encounter challenges in extractive question answering, where they lag behind the SOTA by over 10 points, and in mitigating the risk of injecting false information. A study with oracle-retrievers emphasizes the critical role of effective evidence retrieval, underscoring the necessity for advanced solutions in this area. Furthermore, we highlight the significant influence of evaluation metrics on performance assessments and advocate for a more comprehensive evaluation framework. The complexity of the task, the observed performance discrepancies, and the need for effective evidence retrieval underline the ongoing challenges in this field and underscore the need for future work focusing on refining training tasks and exploring prompt-based techniques to enhance LLM performance in conditional question-answering tasks.
An Empirical Study on Instance Selection Strategies in Self-training for Sentiment Analysis
Sep 15, 2023



Sentiment analysis is a crucial task in natural language processing that involves identifying and extracting subjective sentiment from text. Self-training has recently emerged as an economical and efficient technique for developing sentiment analysis models by leveraging a small amount of labeled data and a larger amount of unlabeled data. However, the performance of a self-training procedure heavily relies on the choice of the instance selection strategy, which has not been studied thoroughly. This paper presents an empirical study on various instance selection strategies for self-training on two public sentiment datasets, and investigates the influence of the strategy and hyper-parameters on the performance of self-training in various few-shot settings.
Correcting Semantic Parses with Natural Language through Dynamic Schema Encoding
May 31, 2023
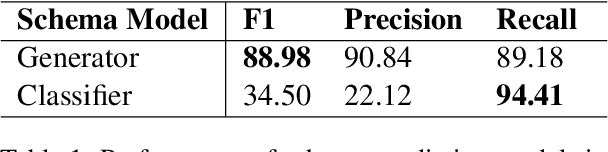
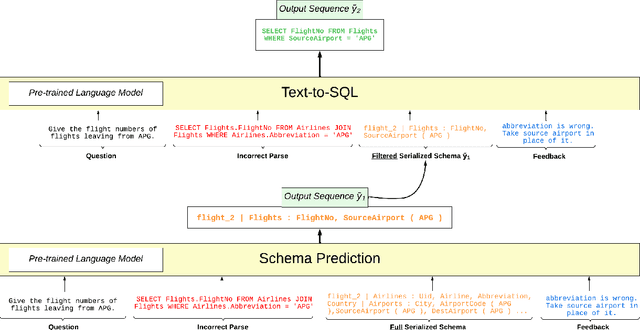
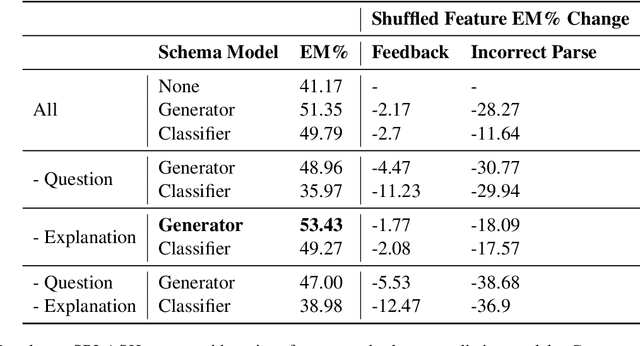
In addressing the task of converting natural language to SQL queries, there are several semantic and syntactic challenges. It becomes increasingly important to understand and remedy the points of failure as the performance of semantic parsing systems improve. We explore semantic parse correction with natural language feedback, proposing a new solution built on the success of autoregressive decoders in text-to-SQL tasks. By separating the semantic and syntactic difficulties of the task, we show that the accuracy of text-to-SQL parsers can be boosted by up to 26% with only one turn of correction with natural language. Additionally, we show that a T5-base model is capable of correcting the errors of a T5-large model in a zero-shot, cross-parser setting.
HeySQuAD: A Spoken Question Answering Dataset
Apr 26, 2023



Human-spoken questions are critical to evaluating the performance of spoken question answering (SQA) systems that serve several real-world use cases including digital assistants. We present a new large-scale community-shared SQA dataset, HeySQuAD that consists of 76k human-spoken questions and 97k machine-generated questions and corresponding textual answers derived from the SQuAD QA dataset. The goal of HeySQuAD is to measure the ability of machines to understand noisy spoken questions and answer the questions accurately. To this end, we run extensive benchmarks on the human-spoken and machine-generated questions to quantify the differences in noise from both sources and its subsequent impact on the model and answering accuracy. Importantly, for the task of SQA, where we want to answer human-spoken questions, we observe that training using the transcribed human-spoken and original SQuAD questions leads to significant improvements (12.51%) over training using only the original SQuAD textual questions.
Understanding BLOOM: An empirical study on diverse NLP tasks
Nov 27, 2022
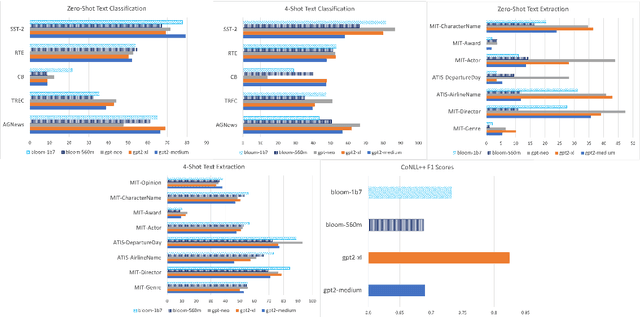
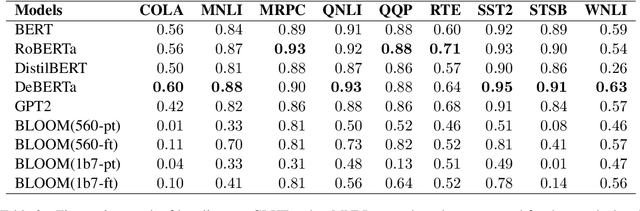
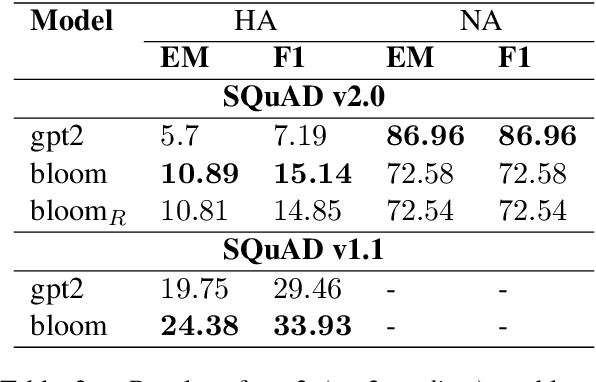
In this work, we present an evaluation of smaller BLOOM model variants (350m/560m and 1b3/1b7) on various natural language processing tasks. This includes GLUE - language understanding, prompt-based zero-shot and few-shot text classification and extraction, question answering, prompt-based text generation, and multi-lingual text classification to understand model strengths/weaknesses and behavior. Empirical results show that BLOOM variants under-perform on all GLUE tasks (except WNLI), question-answering, and text generation. The variants bloom for WNLI, with an accuracy of 56.3%, and for prompt-based few-shot text extraction on MIT Movies and ATIS datasets. The BLOOM variants on average have 7% greater accuracy over GPT-2 and GPT-Neo models on Director and Airline Name extraction from MIT Movies and ATIS datasets, respectively.
CEREC: A Corpus for Entity Resolution in Email Conversations
Jun 02, 2021



We present the first large scale corpus for entity resolution in email conversations (CEREC). The corpus consists of 6001 email threads from the Enron Email Corpus containing 36,448 email messages and 60,383 entity coreference chains. The annotation is carried out as a two-step process with minimal manual effort. Experiments are carried out for evaluating different features and performance of four baselines on the created corpus. For the task of mention identification and coreference resolution, a best performance of 59.2 F1 is reported, highlighting the room for improvement. An in-depth qualitative and quantitative error analysis is presented to understand the limitations of the baselines considered.