 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding BLOOM: An empirical study on diverse NLP tasks
Paper and Code
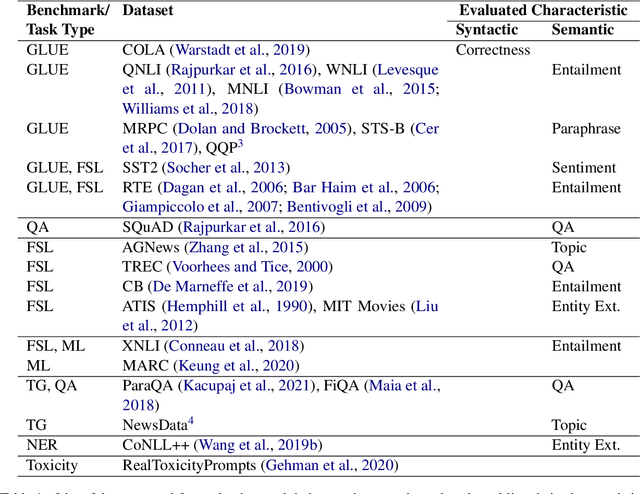
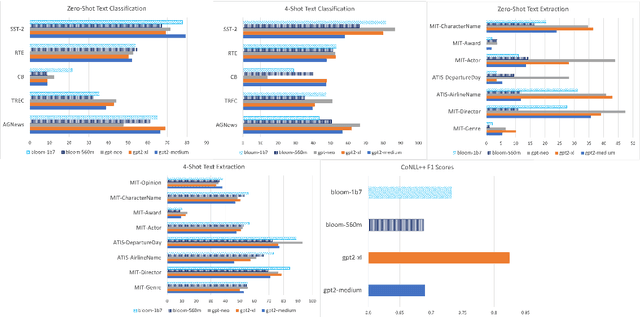
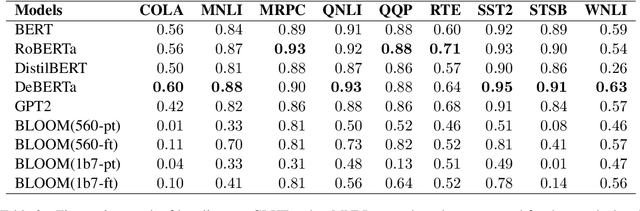
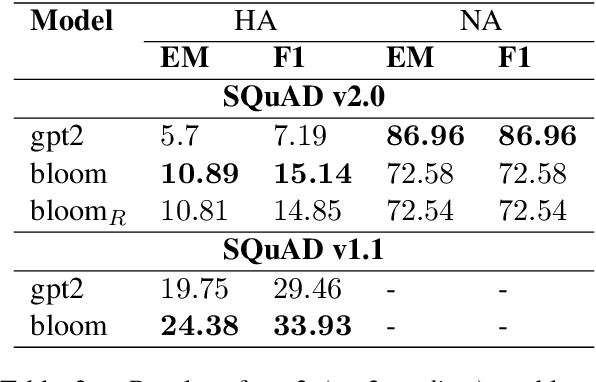
In this work, we present an evaluation of smaller BLOOM model variants (350m/560m and 1b3/1b7) on various natural language processing tasks. This includes GLUE - language understanding, prompt-based zero-shot and few-shot text classification and extraction, question answering, prompt-based text generation, and multi-lingual text classification to understand model strengths/weaknesses and behavior. Empirical results show that BLOOM variants under-perform on all GLUE tasks (except WNLI), question-answering, and text generation. The variants bloom for WNLI, with an accuracy of 56.3%, and for prompt-based few-shot text extraction on MIT Movies and ATIS datasets. The BLOOM variants on average have 7% greater accuracy over GPT-2 and GPT-Neo models on Director and Airline Name extraction from MIT Movies and ATIS datasets, respectively.