 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJetsons at FinNLP 2024: Towards Understanding the ESG Impact of a News Article using Transformer-based Models
Mar 30, 2024In this paper, we describe the different approaches explored by the Jetsons team for the Multi-Lingual ESG Impact Duration Inference (ML-ESG-3) shared task. The shared task focuses on predicting the duration and type of the ESG impact of a news article. The shared task dataset consists of 2,059 news titles and articles in English, French, Korean, and Japanese languages. For the impact duration classification task, we fine-tuned XLM-RoBERTa with a custom fine-tuning strategy and using self-training and DeBERTa-v3 using only English translations. These models individually ranked first on the leaderboard for Korean and Japanese and in an ensemble for the English language, respectively. For the impact type classification task, our XLM-RoBERTa model fine-tuned using a custom fine-tuning strategy ranked first for the English language.
Towards leveraging LLMs for Conditional QA
Dec 02, 2023This study delves into the capabilities and limitations of Large Language Models (LLMs) in the challenging domain of conditional question-answering. Utilizing the Conditional Question Answering (CQA) dataset and focusing on generative models like T5 and UL2, we assess the performance of LLMs across diverse question types. Our findings reveal that fine-tuned LLMs can surpass the state-of-the-art (SOTA) performance in some cases, even without fully encoding all input context, with an increase of 7-8 points in Exact Match (EM) and F1 scores for Yes/No questions. However, these models encounter challenges in extractive question answering, where they lag behind the SOTA by over 10 points, and in mitigating the risk of injecting false information. A study with oracle-retrievers emphasizes the critical role of effective evidence retrieval, underscoring the necessity for advanced solutions in this area. Furthermore, we highlight the significant influence of evaluation metrics on performance assessments and advocate for a more comprehensive evaluation framework. The complexity of the task, the observed performance discrepancies, and the need for effective evidence retrieval underline the ongoing challenges in this field and underscore the need for future work focusing on refining training tasks and exploring prompt-based techniques to enhance LLM performance in conditional question-answering tasks.
HeySQuAD: A Spoken Question Answering Dataset
Apr 26, 2023



Human-spoken questions are critical to evaluating the performance of spoken question answering (SQA) systems that serve several real-world use cases including digital assistants. We present a new large-scale community-shared SQA dataset, HeySQuAD that consists of 76k human-spoken questions and 97k machine-generated questions and corresponding textual answers derived from the SQuAD QA dataset. The goal of HeySQuAD is to measure the ability of machines to understand noisy spoken questions and answer the questions accurately. To this end, we run extensive benchmarks on the human-spoken and machine-generated questions to quantify the differences in noise from both sources and its subsequent impact on the model and answering accuracy. Importantly, for the task of SQA, where we want to answer human-spoken questions, we observe that training using the transcribed human-spoken and original SQuAD questions leads to significant improvements (12.51%) over training using only the original SQuAD textual questions.
Understanding BLOOM: An empirical study on diverse NLP tasks
Nov 27, 2022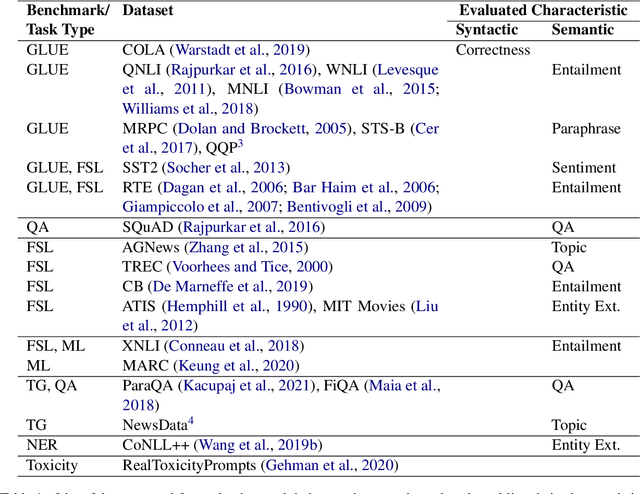
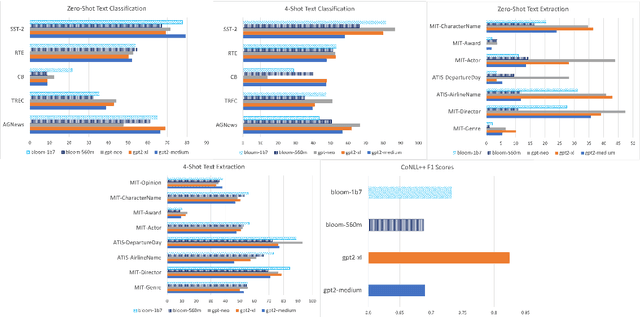
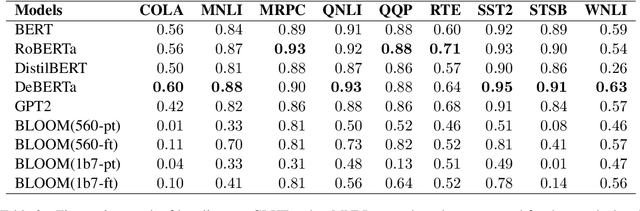
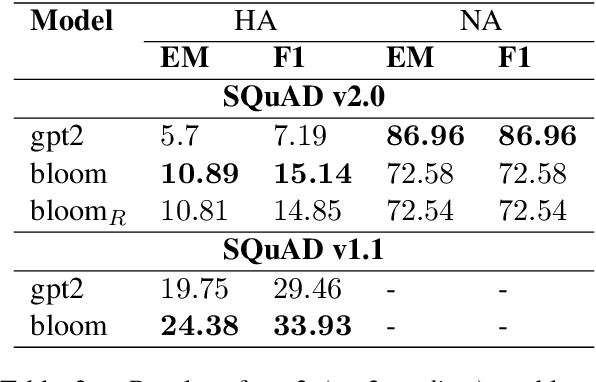
In this work, we present an evaluation of smaller BLOOM model variants (350m/560m and 1b3/1b7) on various natural language processing tasks. This includes GLUE - language understanding, prompt-based zero-shot and few-shot text classification and extraction, question answering, prompt-based text generation, and multi-lingual text classification to understand model strengths/weaknesses and behavior. Empirical results show that BLOOM variants under-perform on all GLUE tasks (except WNLI), question-answering, and text generation. The variants bloom for WNLI, with an accuracy of 56.3%, and for prompt-based few-shot text extraction on MIT Movies and ATIS datasets. The BLOOM variants on average have 7% greater accuracy over GPT-2 and GPT-Neo models on Director and Airline Name extraction from MIT Movies and ATIS datasets, respectively.
On Controlled DeEntanglement for Natural Language Processing
Sep 22, 2019Latest addition to the toolbox of human species is Artificial Intelligence(AI). Thus far, AI has made significant progress in low stake low risk scenarios such as playing Go and we are currently in a transition toward medium stake scenarios such as Visual Dialog. In my thesis, I argue that we need to incorporate controlled de-entanglement as first class object to succeed in this transition. I present mathematical analysis from information theory to show that employing stochasticity leads to controlled de-entanglement of relevant factors of variation at various levels. Based on this, I highlight results from initial experiments that depict efficacy of the proposed framework. I conclude this writeup by a roadmap of experiments that show the applicability of this framework to scalability, flexibility and interpretibility.