 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJetsons at FinNLP 2024: Towards Understanding the ESG Impact of a News Article using Transformer-based Models
Mar 30, 2024In this paper, we describe the different approaches explored by the Jetsons team for the Multi-Lingual ESG Impact Duration Inference (ML-ESG-3) shared task. The shared task focuses on predicting the duration and type of the ESG impact of a news article. The shared task dataset consists of 2,059 news titles and articles in English, French, Korean, and Japanese languages. For the impact duration classification task, we fine-tuned XLM-RoBERTa with a custom fine-tuning strategy and using self-training and DeBERTa-v3 using only English translations. These models individually ranked first on the leaderboard for Korean and Japanese and in an ensemble for the English language, respectively. For the impact type classification task, our XLM-RoBERTa model fine-tuned using a custom fine-tuning strategy ranked first for the English language.
Revisiting the Architectures like Pointer Networks to Efficiently Improve the Next Word Distribution, Summarization Factuality, and Beyond
May 20, 2023


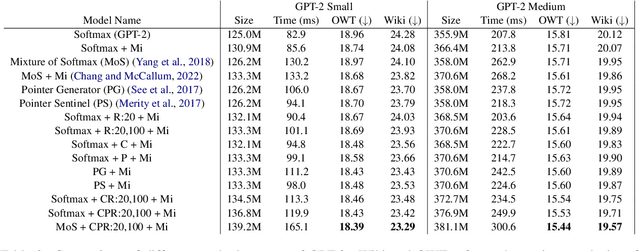
Is the output softmax layer, which is adopted by most language models (LMs), always the best way to compute the next word probability? Given so many attention layers in a modern transformer-based LM, are the pointer networks redundant nowadays? In this study, we discover that the answers to both questions are no. This is because the softmax bottleneck sometimes prevents the LMs from predicting the desired distribution and the pointer networks can be used to break the bottleneck efficiently. Based on the finding, we propose several softmax alternatives by simplifying the pointer networks and accelerating the word-by-word rerankers. In GPT-2, our proposals are significantly better and more efficient than mixture of softmax, a state-of-the-art softmax alternative. In summarization experiments, without significantly decreasing its training/testing speed, our best method based on T5-Small improves factCC score by 2 points in CNN/DM and XSUM dataset, and improves MAUVE scores by 30% in BookSum paragraph-level dataset.
HeySQuAD: A Spoken Question Answering Dataset
Apr 26, 2023



Human-spoken questions are critical to evaluating the performance of spoken question answering (SQA) systems that serve several real-world use cases including digital assistants. We present a new large-scale community-shared SQA dataset, HeySQuAD that consists of 76k human-spoken questions and 97k machine-generated questions and corresponding textual answers derived from the SQuAD QA dataset. The goal of HeySQuAD is to measure the ability of machines to understand noisy spoken questions and answer the questions accurately. To this end, we run extensive benchmarks on the human-spoken and machine-generated questions to quantify the differences in noise from both sources and its subsequent impact on the model and answering accuracy. Importantly, for the task of SQA, where we want to answer human-spoken questions, we observe that training using the transcribed human-spoken and original SQuAD questions leads to significant improvements (12.51%) over training using only the original SQuAD textual questions.