 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Architectures like Pointer Networks to Efficiently Improve the Next Word Distribution, Summarization Factuality, and Beyond
Paper and Code



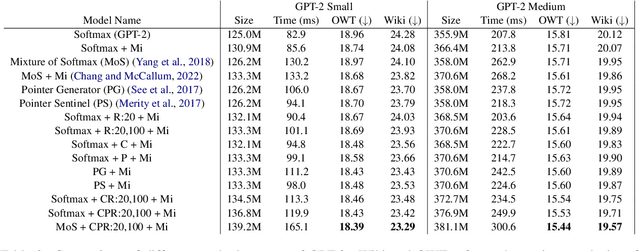
Is the output softmax layer, which is adopted by most language models (LMs), always the best way to compute the next word probability? Given so many attention layers in a modern transformer-based LM, are the pointer networks redundant nowadays? In this study, we discover that the answers to both questions are no. This is because the softmax bottleneck sometimes prevents the LMs from predicting the desired distribution and the pointer networks can be used to break the bottleneck efficiently. Based on the finding, we propose several softmax alternatives by simplifying the pointer networks and accelerating the word-by-word rerankers. In GPT-2, our proposals are significantly better and more efficient than mixture of softmax, a state-of-the-art softmax alternative. In summarization experiments, without significantly decreasing its training/testing speed, our best method based on T5-Small improves factCC score by 2 points in CNN/DM and XSUM dataset, and improves MAUVE scores by 30% in BookSum paragraph-level dataset.