 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Pass Low Latency End-to-End Spoken Language Understanding
Jul 14, 2022



End-to-end (E2E) models are becoming increasingly popular for spoken language understanding (SLU) systems and are beginning to achieve competitive performance to pipeline-based approaches. However, recent work has shown that these models struggle to generalize to new phrasings for the same intent indicating that models cannot understand the semantic content of the given utterance. In this work, we incorporated language models pre-trained on unlabeled text data inside E2E-SLU frameworks to build strong semantic representations. Incorporating both semantic and acoustic information can increase the inference time, leading to high latency when deployed for applications like voice assistants. We developed a 2-pass SLU system that makes low latency prediction using acoustic information from the few seconds of the audio in the first pass and makes higher quality prediction in the second pass by combining semantic and acoustic representations. We take inspiration from prior work on 2-pass end-to-end speech recognition systems that attends on both audio and first-pass hypothesis using a deliberation network. The proposed 2-pass SLU system outperforms the acoustic-based SLU model on the Fluent Speech Commands Challenge Set and SLURP dataset and reduces latency, thus improving user experience. Our code and models are publicly available as part of the ESPnet-SLU toolkit.
DialoGraph: Incorporating Interpretable Strategy-Graph Networks into Negotiation Dialogues
Jun 02, 2021


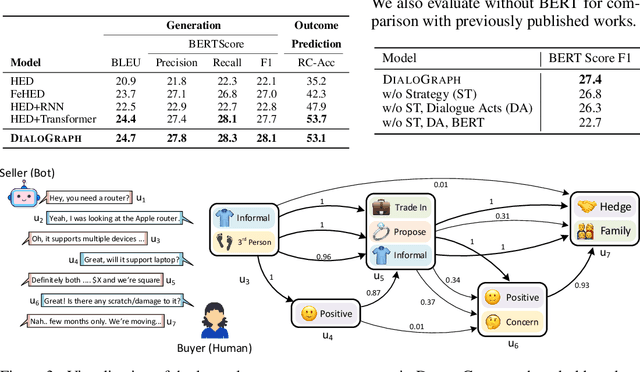
To successfully negotiate a deal, it is not enough to communicate fluently: pragmatic planning of persuasive negotiation strategies is essential. While modern dialogue agents excel at generating fluent sentences, they still lack pragmatic grounding and cannot reason strategically. We present DialoGraph, a negotiation system that incorporates pragmatic strategies in a negotiation dialogue using graph neural networks. DialoGraph explicitly incorporates dependencies between sequences of strategies to enable improved and interpretable prediction of next optimal strategies, given the dialogue context. Our graph-based method outperforms prior state-of-the-art negotiation models both in the accuracy of strategy/dialogue act prediction and in the quality of downstream dialogue response generation. We qualitatively show further benefits of learned strategy-graphs in providing explicit associations between effective negotiation strategies over the course of the dialogue, leading to interpretable and strategic dialogues.
Task-Specific Pre-Training and Cross Lingual Transfer for Code-Switched Data
Feb 24, 2021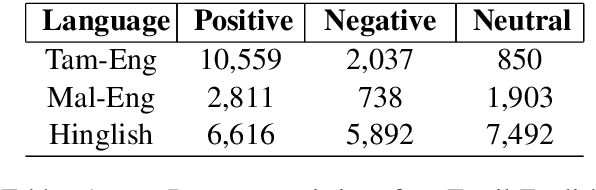
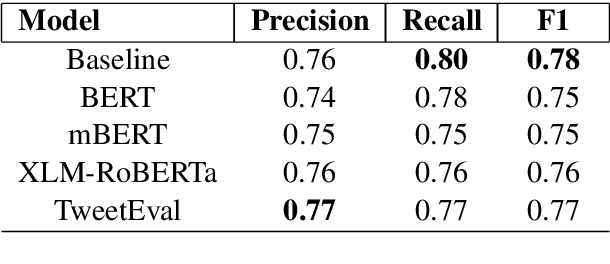
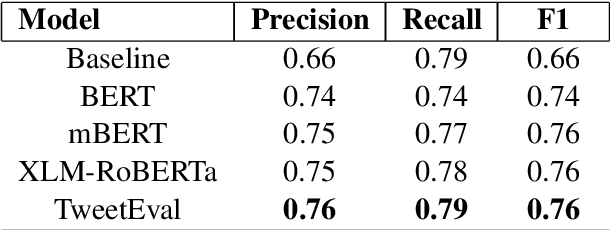
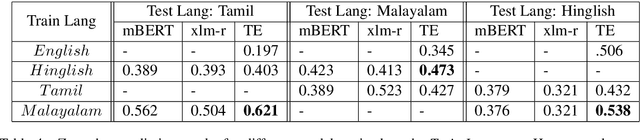
Using task-specific pre-training and leveraging cross-lingual transfer are two of the most popular ways to handle code-switched data. In this paper, we aim to compare the effects of both for the task of sentiment analysis. We work with two Dravidian Code-Switched languages - Tamil-Engish and Malayalam-English and four different BERT based models. We compare the effects of task-specific pre-training and cross-lingual transfer and find that task-specific pre-training results in superior zero-shot and supervised performance when compared to performance achieved by leveraging cross-lingual transfer from multilingual BERT models.
Reading Between the Lines: Exploring Infilling in Visual Narratives
Oct 26, 2020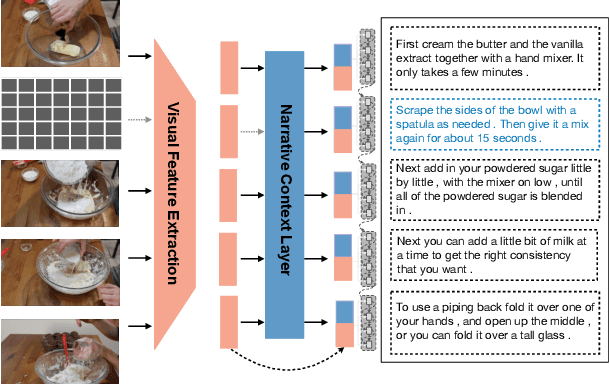


Generating long form narratives such as stories and procedures from multiple modalities has been a long standing dream for artificial intelligence. In this regard, there is often crucial subtext that is derived from the surrounding contexts. The general seq2seq training methods render the models shorthanded while attempting to bridge the gap between these neighbouring contexts. In this paper, we tackle this problem by using \textit{infilling} techniques involving prediction of missing steps in a narrative while generating textual descriptions from a sequence of images. We also present a new large scale \textit{visual procedure telling} (ViPT) dataset with a total of 46,200 procedures and around 340k pairwise images and textual descriptions that is rich in such contextual dependencies. Generating steps using infilling technique demonstrates the effectiveness in visual procedures with more coherent texts. We conclusively show a METEOR score of 27.51 on procedures which is higher than the state-of-the-art on visual storytelling. We also demonstrate the effects of interposing new text with missing images during inference. The code and the dataset will be publicly available at https://visual-narratives.github.io/Visual-Narratives/.
Disentangling Speech and Non-Speech Components for Building Robust Acoustic Models from Found Data
Sep 25, 2019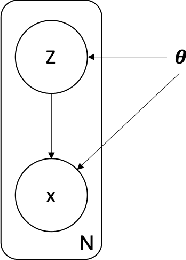
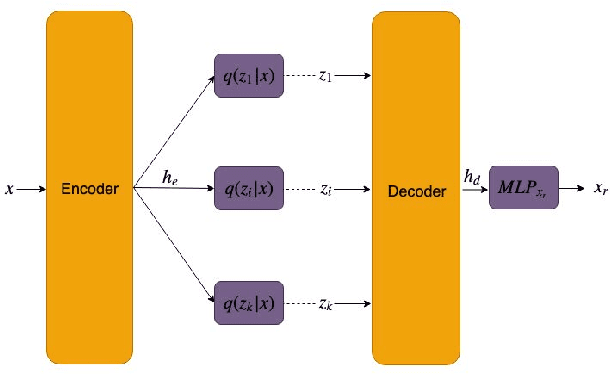
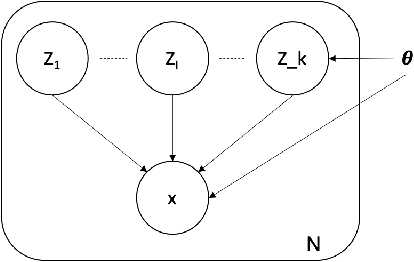
In order to build language technologies for majority of the languages, it is important to leverage the resources available in public domain on the internet - commonly referred to as `Found Data'. However, such data is characterized by the presence of non-standard, non-trivial variations. For instance, speech resources found on the internet have non-speech content, such as music. Therefore, speech recognition and speech synthesis models need to be robust to such variations. In this work, we present an analysis to show that it is important to disentangle the latent causal factors of variation in the original data to accomplish these tasks. Based on this, we present approaches to disentangle such variations from the data using Latent Stochastic Models. Specifically, we present a method to split the latent prior space into continuous representations of dominant speech modes present in the magnitude spectra of audio signals. We propose a completely unsupervised approach using multinode latent space variational autoencoders (VAE). We show that the constraints on the latent space of a VAE can be in-fact used to separate speech and music, independent of the language of the speech. This paper also analytically presents the requirement on the number of latent variables for the task based on distribution of the speech data.
Linguistic unit discovery from multi-modal inputs in unwritten languages: Summary of the "Speaking Rosetta" JSALT 2017 Workshop
Feb 14, 2018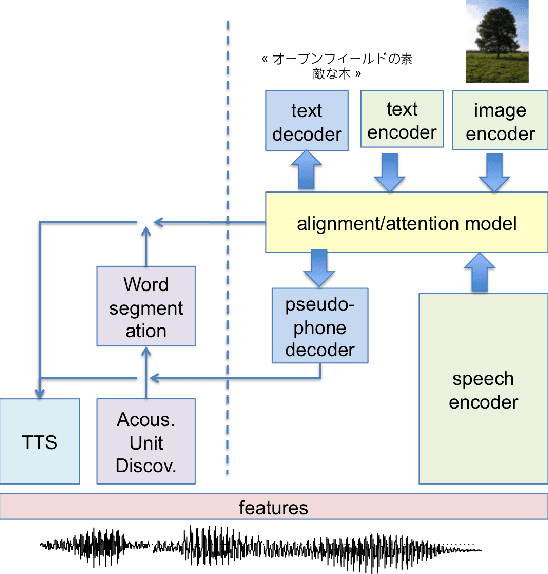

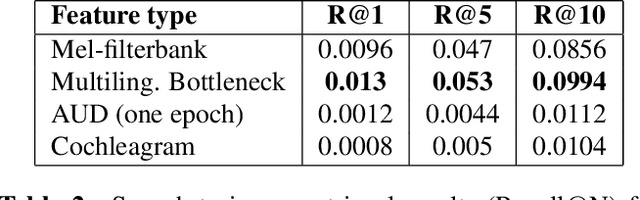
We summarize the accomplishments of a multi-disciplinary workshop exploring the computational and scientific issues surrounding the discovery of linguistic units (subwords and words) in a language without orthography. We study the replacement of orthographic transcriptions by images and/or translated text in a well-resourced language to help unsupervised discovery from raw speech.