Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Specific Pre-Training and Cross Lingual Transfer for Code-Switched Data
Paper and Code
Feb 24, 2021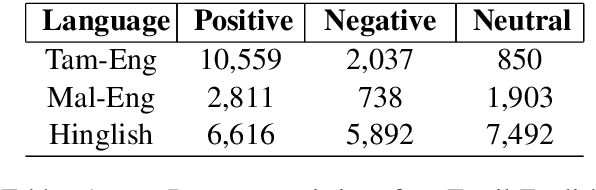
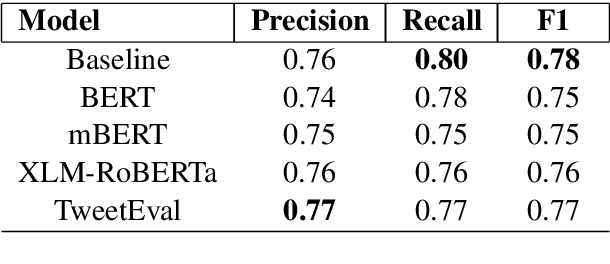
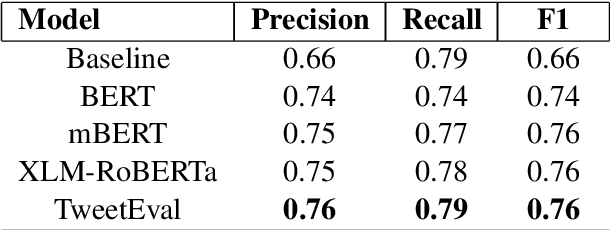
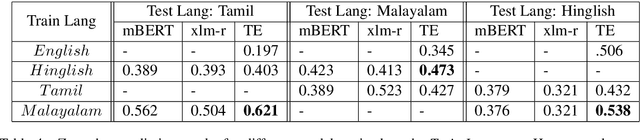
Using task-specific pre-training and leveraging cross-lingual transfer are two of the most popular ways to handle code-switched data. In this paper, we aim to compare the effects of both for the task of sentiment analysis. We work with two Dravidian Code-Switched languages - Tamil-Engish and Malayalam-English and four different BERT based models. We compare the effects of task-specific pre-training and cross-lingual transfer and find that task-specific pre-training results in superior zero-shot and supervised performance when compared to performance achieved by leveraging cross-lingual transfer from multilingual BERT models.
View paper on