 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Flow Matching for Heterogeneous Tabular Data with Mixed-Type Features
Jan 30, 2026Advances in generative modeling have recently been adapted to tabular data containing discrete and continuous features. However, generating mixed-type features that combine discrete states with an otherwise continuous distribution in a single feature remains challenging. We advance the state-of-the-art in diffusion models for tabular data with a cascaded approach. We first generate a low-resolution version of a tabular data row, that is, the collection of the purely categorical features and a coarse categorical representation of numerical features. Next, this information is leveraged in the high-resolution flow matching model via a novel guided conditional probability path and data-dependent coupling. The low-resolution representation of numerical features explicitly accounts for discrete outcomes, such as missing or inflated values, and therewith enables a more faithful generation of mixed-type features. We formally prove that this cascade tightens the transport cost bound. The results indicate that our model generates significantly more realistic samples and captures distributional details more accurately, for example, the detection score increases by 40%.
Continuous Diffusion for Mixed-Type Tabular Data
Dec 16, 2023Score-based generative models (or diffusion models for short) have proven successful across many domains in generating text and image data. However, the consideration of mixed-type tabular data with this model family has fallen short so far. Existing research mainly combines different diffusion processes without explicitly accounting for the feature heterogeneity inherent to tabular data. In this paper, we combine score matching and score interpolation to ensure a common type of continuous noise distribution that affects both continuous and categorical features alike. Further, we investigate the impact of distinct noise schedules per feature or per data type. We allow for adaptive, learnable noise schedules to ensure optimally allocated model capacity and balanced generative capability. Results show that our model consistently outperforms state-of-the-art benchmark models and that accounting for heterogeneity within the noise schedule design boosts the sample quality.
Linguistic unit discovery from multi-modal inputs in unwritten languages: Summary of the "Speaking Rosetta" JSALT 2017 Workshop
Feb 14, 2018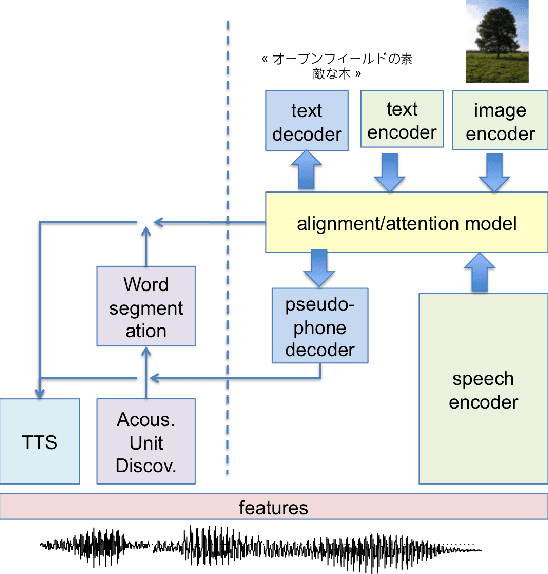

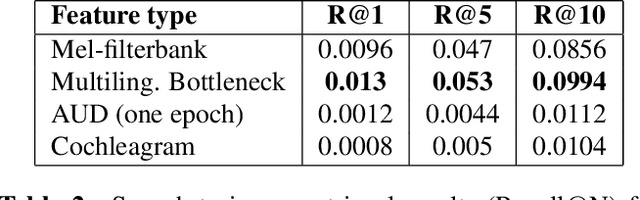
We summarize the accomplishments of a multi-disciplinary workshop exploring the computational and scientific issues surrounding the discovery of linguistic units (subwords and words) in a language without orthography. We study the replacement of orthographic transcriptions by images and/or translated text in a well-resourced language to help unsupervised discovery from raw speech.