 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Speech and Non-Speech Components for Building Robust Acoustic Models from Found Data
Paper and Code
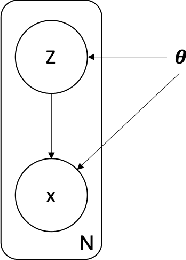
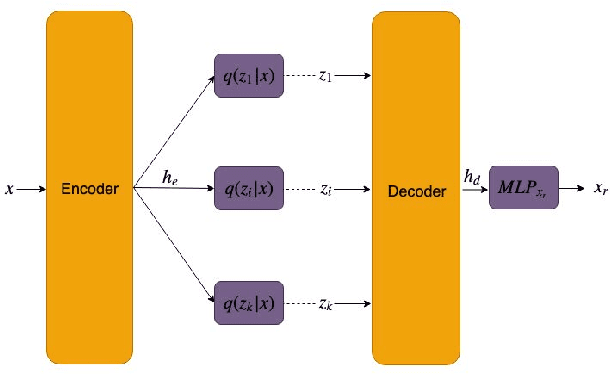
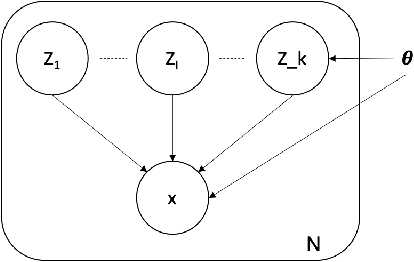
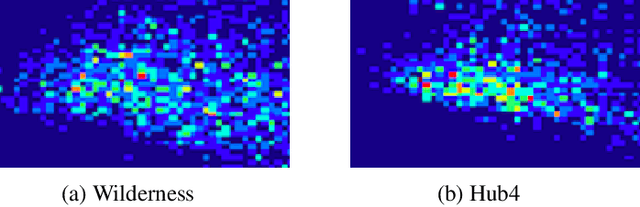
In order to build language technologies for majority of the languages, it is important to leverage the resources available in public domain on the internet - commonly referred to as `Found Data'. However, such data is characterized by the presence of non-standard, non-trivial variations. For instance, speech resources found on the internet have non-speech content, such as music. Therefore, speech recognition and speech synthesis models need to be robust to such variations. In this work, we present an analysis to show that it is important to disentangle the latent causal factors of variation in the original data to accomplish these tasks. Based on this, we present approaches to disentangle such variations from the data using Latent Stochastic Models. Specifically, we present a method to split the latent prior space into continuous representations of dominant speech modes present in the magnitude spectra of audio signals. We propose a completely unsupervised approach using multinode latent space variational autoencoders (VAE). We show that the constraints on the latent space of a VAE can be in-fact used to separate speech and music, independent of the language of the speech. This paper also analytically presents the requirement on the number of latent variables for the task based on distribution of the speech data.