 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning
Nov 10, 2021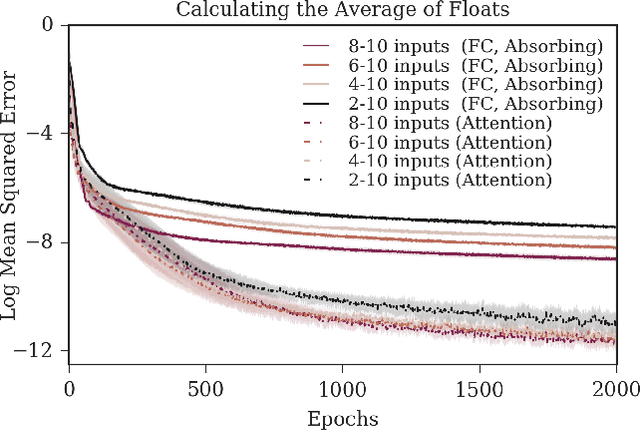
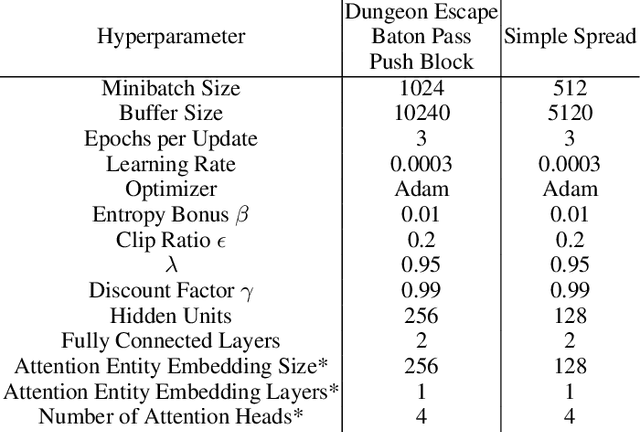

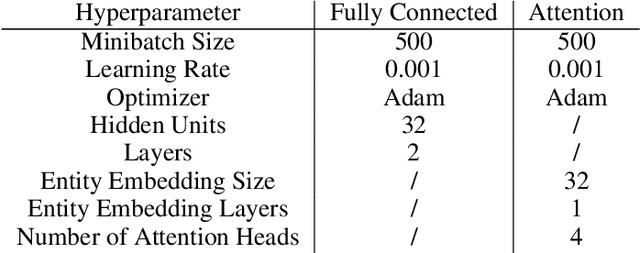
The creation and destruction of agents in cooperative multi-agent reinforcement learning (MARL) is a critically under-explored area of research. Current MARL algorithms often assume that the number of agents within a group remains fixed throughout an experiment. However, in many practical problems, an agent may terminate before their teammates. This early termination issue presents a challenge: the terminated agent must learn from the group's success or failure which occurs beyond its own existence. We refer to propagating value from rewards earned by remaining teammates to terminated agents as the Posthumous Credit Assignment problem. Current MARL methods handle this problem by placing these agents in an absorbing state until the entire group of agents reaches a termination condition. Although absorbing states enable existing algorithms and APIs to handle terminated agents without modification, practical training efficiency and resource use problems exist. In this work, we first demonstrate that sample complexity increases with the quantity of absorbing states in a toy supervised learning task for a fully connected network, while attention is more robust to variable size input. Then, we present a novel architecture for an existing state-of-the-art MARL algorithm which uses attention instead of a fully connected layer with absorbing states. Finally, we demonstrate that this novel architecture significantly outperforms the standard architecture on tasks in which agents are created or destroyed within episodes as well as standard multi-agent coordination tasks.
Reading Between the Lines: Exploring Infilling in Visual Narratives
Oct 26, 2020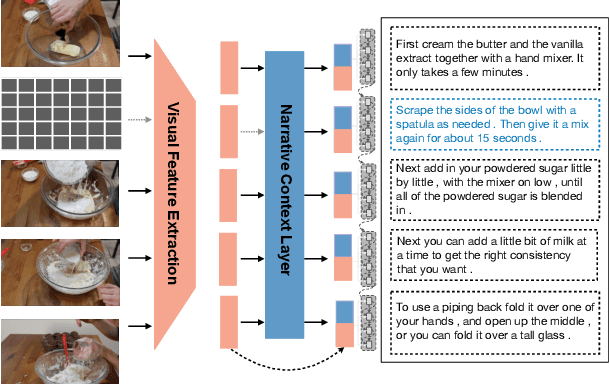


Generating long form narratives such as stories and procedures from multiple modalities has been a long standing dream for artificial intelligence. In this regard, there is often crucial subtext that is derived from the surrounding contexts. The general seq2seq training methods render the models shorthanded while attempting to bridge the gap between these neighbouring contexts. In this paper, we tackle this problem by using \textit{infilling} techniques involving prediction of missing steps in a narrative while generating textual descriptions from a sequence of images. We also present a new large scale \textit{visual procedure telling} (ViPT) dataset with a total of 46,200 procedures and around 340k pairwise images and textual descriptions that is rich in such contextual dependencies. Generating steps using infilling technique demonstrates the effectiveness in visual procedures with more coherent texts. We conclusively show a METEOR score of 27.51 on procedures which is higher than the state-of-the-art on visual storytelling. We also demonstrate the effects of interposing new text with missing images during inference. The code and the dataset will be publicly available at https://visual-narratives.github.io/Visual-Narratives/.
Induction and Reference of Entities in a Visual Story
Sep 15, 2019
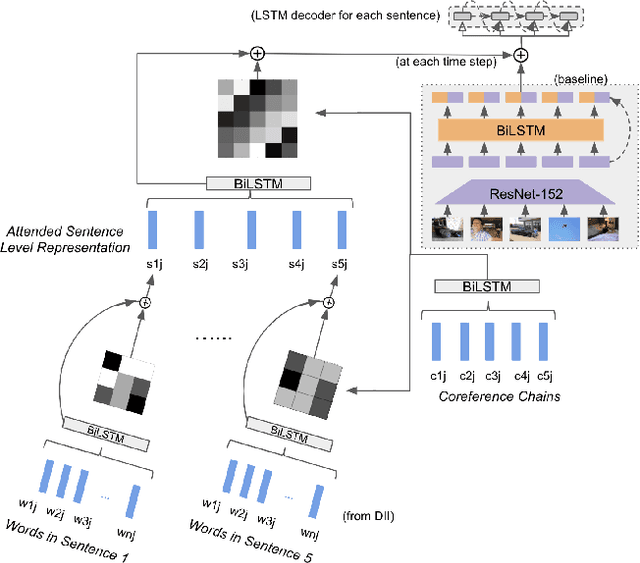
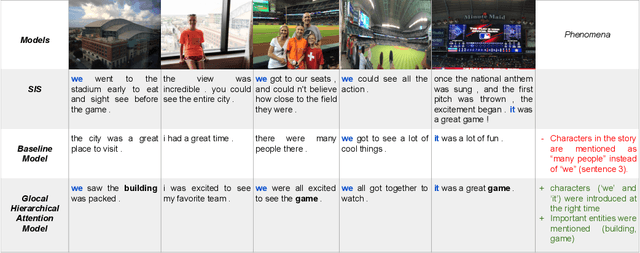
We are enveloped by stories of visual interpretations in our everyday lives. The way we narrate a story often comprises of two stages, which are, forming a central mind map of entities and then weaving a story around them. A contributing factor to coherence is not just basing the story on these entities but also, referring to them using appropriate terms to avoid repetition. In this paper, we address these two stages of introducing the right entities at seemingly reasonable junctures and also referring them coherently in the context of visual storytelling. The building blocks of the central mind map, also known as entity skeleton are entity chains including nominal and coreference expressions. This entity skeleton is also represented in different levels of abstractions to compose a generalized frame to weave the story. We build upon an encoder-decoder framework to penalize the model when the decoded story does not adhere to this entity skeleton. We establish a strong baseline for skeleton informed generation and then extend this to have the capability of multitasking by predicting the skeleton in addition to generating the story. Finally, we build upon this model and propose a glocal hierarchical attention model that attends to the skeleton both at the sentence (local) and the story (global) levels. We observe that our proposed models outperform the baseline in terms of automatic evaluation metric, METEOR. We perform various analysis targeted to evaluate the performance of our task of enforcing the entity skeleton such as the number and diversity of the entities generated. We also conduct human evaluation from which it is concluded that the visual stories generated by our model are preferred 82% of the times. In addition, we show that our glocal hierarchical attention model improves coherence by introducing more pronouns as required by the presence of nouns.