 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Machine Translation using Interlinear Glosses
Paper and Code
Nov 07, 2019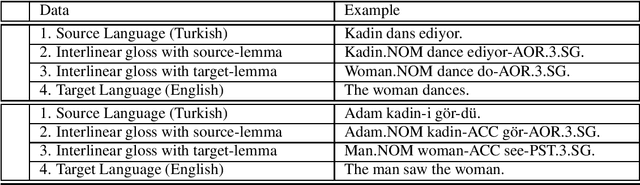

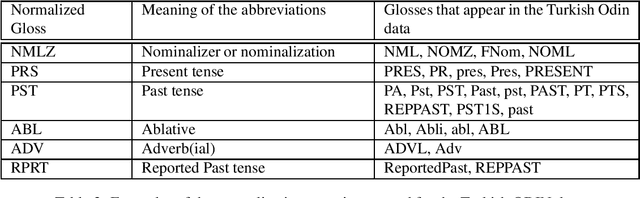
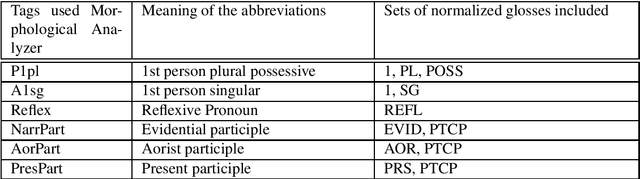
Neural Machine Translation (NMT) does not handle low-resource translation well because NMT is data-hungry and low-resource languages, by their nature, have limited parallel data. Many low-resource languages are morphologically rich, which complicates matters further by increasing data sparsity. However, a good linguist is capable of building a morphological analyzer in far fewer hours than it would take to collect and translate the amount of parallel data needed for conventional NMT. We combine the benefits of both NMT and linguistic information in our work. We use morphological analyzer to automatically generate interlinear glosses with dictionary or parallel data, and translate the source text to interlinear gloss as an interlingua representation, and finally translate into the target text using NMT trained on the ODIN dataset that includes a large collection of interlinear glosses and their corresponding target translations. Our result for translating from the interlinear gloss to the target text using the entire ODIN dataset achieves a BLEU score of 35.07. And our qualitative results show positive findings in a low-resource scenario of Turkish-English translation using 865 lines of training data. Our translation system yield better results than training NMT directly from the source language to the target language in a constrained-data setting, and is helpful to produce translation with sufficiently good content and fluency when data is scarce.