 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexList-Hate: A Checklist-Based Framework for Interpretable and Generalizable Hate Speech Detection
Feb 05, 2026Hate speech detection is commonly framed as a direct binary classification problem despite being a composite concept defined through multiple interacting factors that vary across legal frameworks, platform policies, and annotation guidelines. As a result, supervised models often overfit dataset-specific definitions and exhibit limited robustness under domain shift and annotation noise. We introduce xList-Hate, a diagnostic framework that decomposes hate speech detection into a checklist of explicit, concept-level questions grounded in widely shared normative criteria. Each question is independently answered by a large language model (LLM), producing a binary diagnostic representation that captures hateful content features without directly predicting the final label. These diagnostic signals are then aggregated by a lightweight, fully interpretable decision tree, yielding transparent and auditable predictions. We evaluate it across multiple hate speech benchmarks and model families, comparing it against zero-shot LLM classification and in-domain supervised fine-tuning. While supervised methods typically maximize in-domain performance, we consistently improves cross-dataset robustness and relative performance under domain shift. In addition, qualitative analysis of disagreement cases provides evidence that the framework can be less sensitive to certain forms of annotation inconsistency and contextual ambiguity. Crucially, the approach enables fine-grained interpretability through explicit decision paths and factor-level analysis. Our results suggest that reframing hate speech detection as a diagnostic reasoning task, rather than a monolithic classification problem, provides a robust, explainable, and extensible alternative for content moderation.
Decoding Latent Spaces: Assessing the Interpretability of Time Series Foundation Models for Visual Analytics
Apr 26, 2025The present study explores the interpretability of latent spaces produced by time series foundation models, focusing on their potential for visual analysis tasks. Specifically, we evaluate the MOMENT family of models, a set of transformer-based, pre-trained architectures for multivariate time series tasks such as: imputation, prediction, classification, and anomaly detection. We evaluate the capacity of these models on five datasets to capture the underlying structures in time series data within their latent space projection and validate whether fine tuning improves the clarity of the resulting embedding spaces. Notable performance improvements in terms of loss reduction were observed after fine tuning. Visual analysis shows limited improvement in the interpretability of the embeddings, requiring further work. Results suggest that, although Time Series Foundation Models such as MOMENT are robust, their latent spaces may require additional methodological refinements to be adequately interpreted, such as alternative projection techniques, loss functions, or data preprocessing strategies. Despite the limitations of MOMENT, foundation models supose a big reduction in execution time and so a great advance for interactive visual analytics.
Pushing the boundary on Natural Language Inference
Apr 25, 2025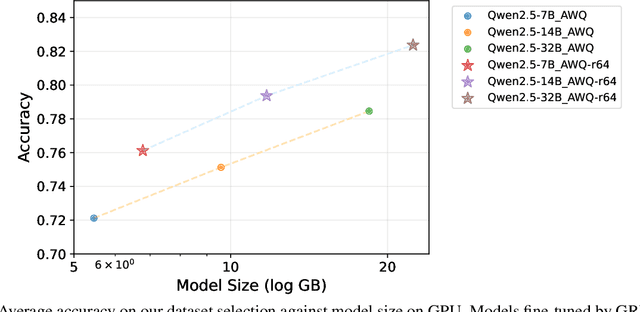
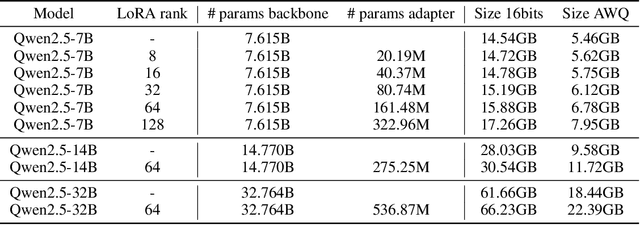
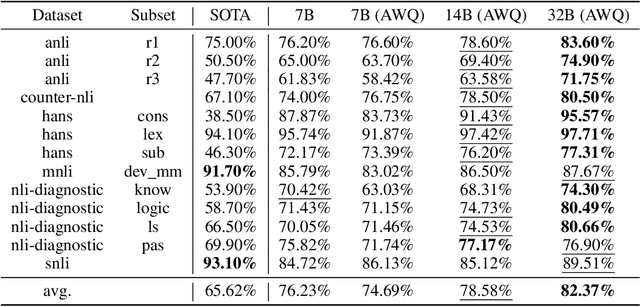
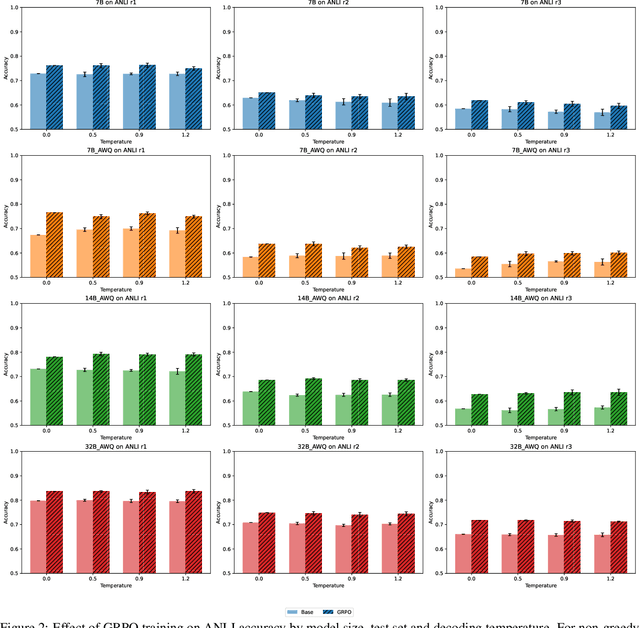
Natural Language Inference (NLI) is a central task in natural language understanding with applications in fact-checking, question answering, and information retrieval. Despite its importance, current NLI systems heavily rely on supervised learning with datasets that often contain annotation artifacts and biases, limiting generalization and real-world applicability. In this work, we apply a reinforcement learning-based approach using Group Relative Policy Optimization (GRPO) for Chain-of-Thought (CoT) learning in NLI, eliminating the need for labeled rationales and enabling this type of training on more challenging datasets such as ANLI. We fine-tune 7B, 14B, and 32B language models using parameter-efficient techniques (LoRA and QLoRA), demonstrating strong performance across standard and adversarial NLI benchmarks. Our 32B AWQ-quantized model surpasses state-of-the-art results on 7 out of 11 adversarial sets$\unicode{x2013}$or on all of them considering our replication$\unicode{x2013}$within a 22GB memory footprint, showing that robust reasoning can be retained under aggressive quantization. This work provides a scalable and practical framework for building robust NLI systems without sacrificing inference quality.
On the locality bias and results in the Long Range Arena
Jan 24, 2025The Long Range Arena (LRA) benchmark was designed to evaluate the performance of Transformer improvements and alternatives in long-range dependency modeling tasks. The Transformer and its main variants performed poorly on this benchmark, and a new series of architectures such as State Space Models (SSMs) gained some traction, greatly outperforming Transformers in the LRA. Recent work has shown that with a denoising pre-training phase, Transformers can achieve competitive results in the LRA with these new architectures. In this work, we discuss and explain the superiority of architectures such as MEGA and SSMs in the Long Range Arena, as well as the recent improvement in the results of Transformers, pointing to the positional and local nature of the tasks. We show that while the LRA is a benchmark for long-range dependency modeling, in reality most of the performance comes from short-range dependencies. Using training techniques to mitigate data inefficiency, Transformers are able to reach state-of-the-art performance with proper positional encoding. In addition, with the same techniques, we were able to remove all restrictions from SSM convolutional kernels and learn fully parameterized convolutions without decreasing performance, suggesting that the design choices behind SSMs simply added inductive biases and learning efficiency for these particular tasks. Our insights indicate that LRA results should be interpreted with caution and call for a redesign of the benchmark.
Not all tokens are created equal: Perplexity Attention Weighted Networks for AI generated text detection
Jan 07, 2025



The rapid advancement in large language models (LLMs) has significantly enhanced their ability to generate coherent and contextually relevant text, raising concerns about the misuse of AI-generated content and making it critical to detect it. However, the task remains challenging, particularly in unseen domains or with unfamiliar LLMs. Leveraging LLM next-token distribution outputs offers a theoretically appealing approach for detection, as they encapsulate insights from the models' extensive pre-training on diverse corpora. Despite its promise, zero-shot methods that attempt to operationalize these outputs have met with limited success. We hypothesize that one of the problems is that they use the mean to aggregate next-token distribution metrics across tokens, when some tokens are naturally easier or harder to predict and should be weighted differently. Based on this idea, we propose the Perplexity Attention Weighted Network (PAWN), which uses the last hidden states of the LLM and positions to weight the sum of a series of features based on metrics from the next-token distribution across the sequence length. Although not zero-shot, our method allows us to cache the last hidden states and next-token distribution metrics on disk, greatly reducing the training resource requirements. PAWN shows competitive and even better performance in-distribution than the strongest baselines (fine-tuned LMs) with a fraction of their trainable parameters. Our model also generalizes better to unseen domains and source models, with smaller variability in the decision boundary across distribution shifts. It is also more robust to adversarial attacks, and if the backbone has multilingual capabilities, it presents decent generalization to languages not seen during supervised training, with LLaMA3-1B reaching a mean macro-averaged F1 score of 81.46% in cross-validation with nine languages.
Isolating authorship from content with semantic embeddings and contrastive learning
Nov 27, 2024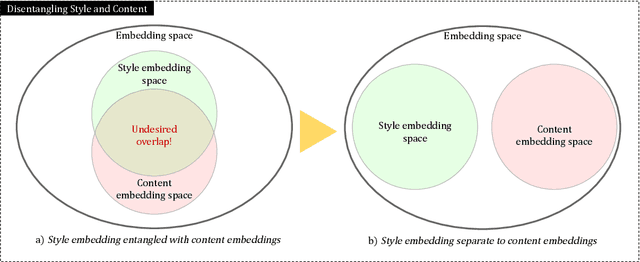

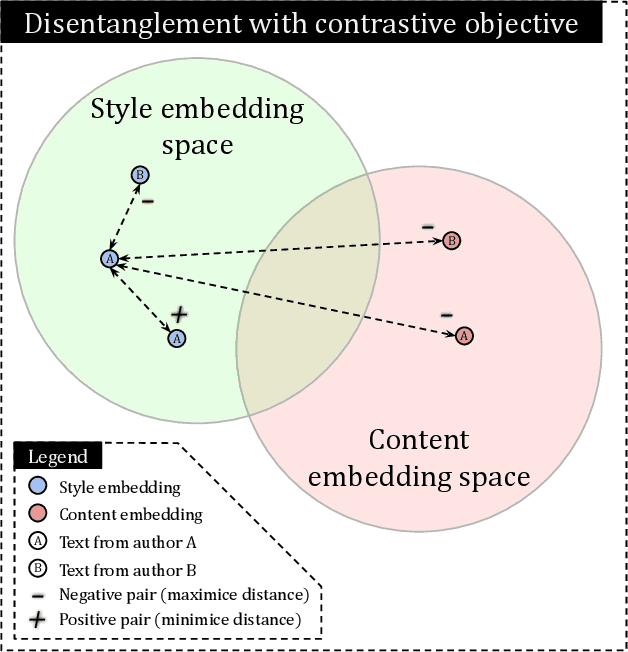
Authorship has entangled style and content inside. Authors frequently write about the same topics in the same style, so when different authors write about the exact same topic the easiest way out to distinguish them is by understanding the nuances of their style. Modern neural models for authorship can pick up these features using contrastive learning, however, some amount of content leakage is always present. Our aim is to reduce the inevitable impact and correlation between content and authorship. We present a technique to use contrastive learning (InfoNCE) with additional hard negatives synthetically created using a semantic similarity model. This disentanglement technique aims to distance the content embedding space from the style embedding space, leading to embeddings more informed by style. We demonstrate the performance with ablations on two different datasets and compare them on out-of-domain challenges. Improvements are clearly shown on challenging evaluations on prolific authors with up to a 10% increase in accuracy when the settings are particularly hard. Trials on challenges also demonstrate the preservation of zero-shot capabilities of this method as fine tuning.
DisTrack: a new Tool for Semi-automatic Misinformation Tracking in Online Social Networks
Aug 01, 2024Introduction: This article introduces DisTrack, a methodology and a tool developed for tracking and analyzing misinformation within Online Social Networks (OSNs). DisTrack is designed to combat the spread of misinformation through a combination of Natural Language Processing (NLP) Social Network Analysis (SNA) and graph visualization. The primary goal is to detect misinformation, track its propagation, identify its sources, and assess the influence of various actors within the network. Methods: DisTrack's architecture incorporates a variety of methodologies including keyword search, semantic similarity assessments, and graph generation techniques. These methods collectively facilitate the monitoring of misinformation, the categorization of content based on alignment with known false claims, and the visualization of dissemination cascades through detailed graphs. The tool is tailored to capture and analyze the dynamic nature of misinformation spread in digital environments. Results: The effectiveness of DisTrack is demonstrated through three case studies focused on different themes: discredit/hate speech, anti-vaccine misinformation, and false narratives about the Russia-Ukraine conflict. These studies show DisTrack's capabilities in distinguishing posts that propagate falsehoods from those that counteract them, and tracing the evolution of misinformation from its inception. Conclusions: The research confirms that DisTrack is a valuable tool in the field of misinformation analysis. It effectively distinguishes between different types of misinformation and traces their development over time. By providing a comprehensive approach to understanding and combating misinformation in digital spaces, DisTrack proves to be an essential asset for researchers and practitioners working to mitigate the impact of false information in online social environments.
Camouflage is all you need: Evaluating and Enhancing Language Model Robustness Against Camouflage Adversarial Attacks
Feb 15, 2024



Adversarial attacks represent a substantial challenge in Natural Language Processing (NLP). This study undertakes a systematic exploration of this challenge in two distinct phases: vulnerability evaluation and resilience enhancement of Transformer-based models under adversarial attacks. In the evaluation phase, we assess the susceptibility of three Transformer configurations, encoder-decoder, encoder-only, and decoder-only setups, to adversarial attacks of escalating complexity across datasets containing offensive language and misinformation. Encoder-only models manifest a 14% and 21% performance drop in offensive language detection and misinformation detection tasks, respectively. Decoder-only models register a 16% decrease in both tasks, while encoder-decoder models exhibit a maximum performance drop of 14% and 26% in the respective tasks. The resilience-enhancement phase employs adversarial training, integrating pre-camouflaged and dynamically altered data. This approach effectively reduces the performance drop in encoder-only models to an average of 5% in offensive language detection and 2% in misinformation detection tasks. Decoder-only models, occasionally exceeding original performance, limit the performance drop to 7% and 2% in the respective tasks. Although not surpassing the original performance, Encoder-decoder models can reduce the drop to an average of 6% and 2% respectively. Results suggest a trade-off between performance and robustness, with some models maintaining similar performance while gaining robustness. Our study and adversarial training techniques have been incorporated into an open-source tool for generating camouflaged datasets. However, methodology effectiveness depends on the specific camouflage technique and data encountered, emphasizing the need for continued exploration.
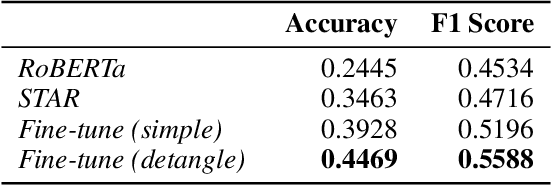
Understanding writing style in social media with a supervised contrastively pre-trained transformer
Oct 17, 2023Online Social Networks serve as fertile ground for harmful behavior, ranging from hate speech to the dissemination of disinformation. Malicious actors now have unprecedented freedom to misbehave, leading to severe societal unrest and dire consequences, as exemplified by events such as the Capitol assault during the US presidential election and the Antivaxx movement during the COVID-19 pandemic. Understanding online language has become more pressing than ever. While existing works predominantly focus on content analysis, we aim to shift the focus towards understanding harmful behaviors by relating content to their respective authors. Numerous novel approaches attempt to learn the stylistic features of authors in texts, but many of these approaches are constrained by small datasets or sub-optimal training losses. To overcome these limitations, we introduce the Style Transformer for Authorship Representations (STAR), trained on a large corpus derived from public sources of 4.5 x 10^6 authored texts involving 70k heterogeneous authors. Our model leverages Supervised Contrastive Loss to teach the model to minimize the distance between texts authored by the same individual. This author pretext pre-training task yields competitive performance at zero-shot with PAN challenges on attribution and clustering. Additionally, we attain promising results on PAN verification challenges using a single dense layer, with our model serving as an embedding encoder. Finally, we present results from our test partition on Reddit. Using a support base of 8 documents of 512 tokens, we can discern authors from sets of up to 1616 authors with at least 80\% accuracy. We share our pre-trained model at huggingface (https://huggingface.co/AIDA-UPM/star) and our code is available at (https://github.com/jahuerta92/star)
Spain on Fire: A novel wildfire risk assessment model based on image satellite processing and atmospheric information
Jun 08, 2023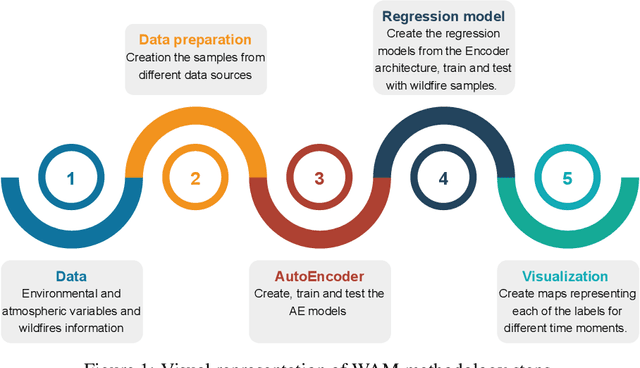
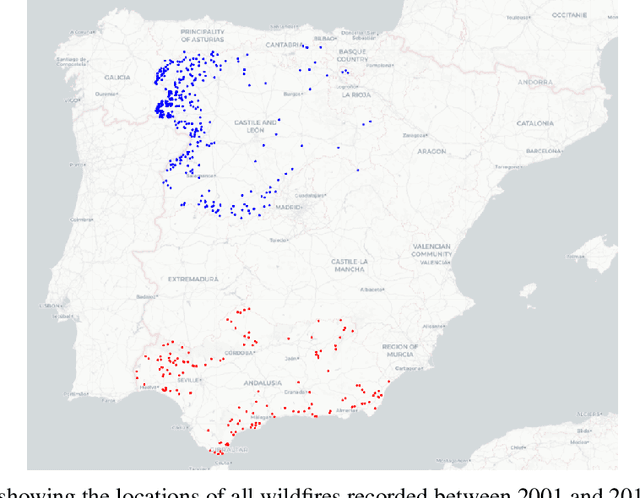
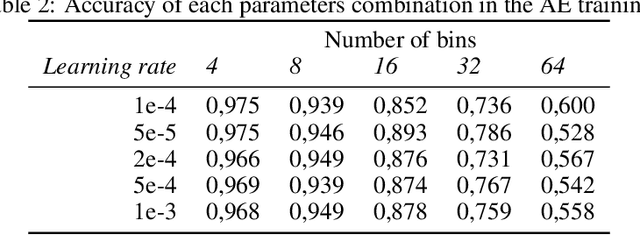
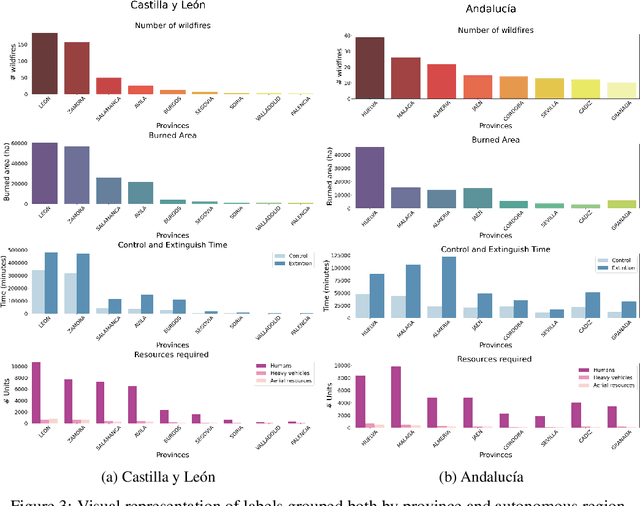
Each year, wildfires destroy larger areas of Spain, threatening numerous ecosystems. Humans cause 90% of them (negligence or provoked) and the behaviour of individuals is unpredictable. However, atmospheric and environmental variables affect the spread of wildfires, and they can be analysed by using deep learning. In order to mitigate the damage of these events we proposed the novel Wildfire Assessment Model (WAM). Our aim is to anticipate the economic and ecological impact of a wildfire, assisting managers resource allocation and decision making for dangerous regions in Spain, Castilla y Le\'on and Andaluc\'ia. The WAM uses a residual-style convolutional network architecture to perform regression over atmospheric variables and the greenness index, computing necessary resources, the control and extinction time, and the expected burnt surface area. It is first pre-trained with self-supervision over 100,000 examples of unlabelled data with a masked patch prediction objective and fine-tuned using 311 samples of wildfires. The pretraining allows the model to understand situations, outclassing baselines with a 1,4%, 3,7% and 9% improvement estimating human, heavy and aerial resources; 21% and 10,2% in expected extinction and control time; and 18,8% in expected burnt area. Using the WAM we provide an example assessment map of Castilla y Le\'on, visualizing the expected resources over an entire region.