 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for Transformer Models for Dark-Pattern Detection
Dec 06, 2024



The opaque nature of transformer-based models, particularly in applications susceptible to unethical practices such as dark-patterns in user interfaces, requires models that integrate uncertainty quantification to enhance trust in predictions. This study focuses on dark-pattern detection, deceptive design choices that manipulate user decisions, undermining autonomy and consent. We propose a differential fine-tuning approach implemented at the final classification head via uncertainty quantification with transformer-based pre-trained models. Employing a dense neural network (DNN) head architecture as a baseline, we examine two methods capable of quantifying uncertainty: Spectral-normalized Neural Gaussian Processes (SNGPs) and Bayesian Neural Networks (BNNs). These methods are evaluated on a set of open-source foundational models across multiple dimensions: model performance, variance in certainty of predictions and environmental impact during training and inference phases. Results demonstrate that integrating uncertainty quantification maintains performance while providing insights into challenging instances within the models. Moreover, the study reveals that the environmental impact does not uniformly increase with the incorporation of uncertainty quantification techniques. The study's findings demonstrate that uncertainty quantification enhances transparency and provides measurable confidence in predictions, improving the explainability and clarity of black-box models. This facilitates informed decision-making and mitigates the influence of dark-patterns on user interfaces. These results highlight the importance of incorporating uncertainty quantification techniques in developing machine learning models, particularly in domains where interpretability and trustworthiness are critical.
DisTrack: a new Tool for Semi-automatic Misinformation Tracking in Online Social Networks
Aug 01, 2024Introduction: This article introduces DisTrack, a methodology and a tool developed for tracking and analyzing misinformation within Online Social Networks (OSNs). DisTrack is designed to combat the spread of misinformation through a combination of Natural Language Processing (NLP) Social Network Analysis (SNA) and graph visualization. The primary goal is to detect misinformation, track its propagation, identify its sources, and assess the influence of various actors within the network. Methods: DisTrack's architecture incorporates a variety of methodologies including keyword search, semantic similarity assessments, and graph generation techniques. These methods collectively facilitate the monitoring of misinformation, the categorization of content based on alignment with known false claims, and the visualization of dissemination cascades through detailed graphs. The tool is tailored to capture and analyze the dynamic nature of misinformation spread in digital environments. Results: The effectiveness of DisTrack is demonstrated through three case studies focused on different themes: discredit/hate speech, anti-vaccine misinformation, and false narratives about the Russia-Ukraine conflict. These studies show DisTrack's capabilities in distinguishing posts that propagate falsehoods from those that counteract them, and tracing the evolution of misinformation from its inception. Conclusions: The research confirms that DisTrack is a valuable tool in the field of misinformation analysis. It effectively distinguishes between different types of misinformation and traces their development over time. By providing a comprehensive approach to understanding and combating misinformation in digital spaces, DisTrack proves to be an essential asset for researchers and practitioners working to mitigate the impact of false information in online social environments.
DETECTA 2.0: Research into non-intrusive methodologies supported by Industry 4.0 enabling technologies for predictive and cyber-secure maintenance in SMEs
May 24, 2024

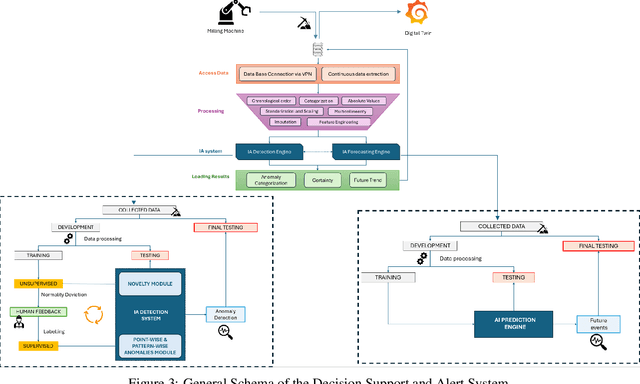
The integration of predictive maintenance and cybersecurity represents a transformative advancement for small and medium-sized enterprises (SMEs) operating within the Industry 4.0 paradigm. Despite their economic importance, SMEs often face significant challenges in adopting advanced technologies due to resource constraints and knowledge gaps. The DETECTA 2.0 project addresses these hurdles by developing an innovative system that harmonizes real-time anomaly detection, sophisticated analytics, and predictive forecasting capabilities. The system employs a semi-supervised methodology, combining unsupervised anomaly detection with supervised learning techniques. This approach enables more agile and cost-effective development of AI detection systems, significantly reducing the time required for manual case review. At the core lies a Digital Twin interface, providing intuitive real-time visualizations of machine states and detected anomalies. Leveraging cutting-edge AI engines, the system intelligently categorizes anomalies based on observed patterns, differentiating between technical errors and potential cybersecurity incidents. This discernment is fortified by detailed analytics, including certainty levels that enhance alert reliability and minimize false positives. The predictive engine uses advanced time series algorithms like N-HiTS to forecast future machine utilization trends. This proactive approach optimizes maintenance planning, enhances cybersecurity measures, and minimizes unplanned downtimes despite variable production processes. With its modular architecture enabling seamless integration across industrial setups and low implementation costs, DETECTA 2.0 presents an attractive solution for SMEs to strengthen their predictive maintenance and cybersecurity strategies.
Camouflage is all you need: Evaluating and Enhancing Language Model Robustness Against Camouflage Adversarial Attacks
Feb 15, 2024



Adversarial attacks represent a substantial challenge in Natural Language Processing (NLP). This study undertakes a systematic exploration of this challenge in two distinct phases: vulnerability evaluation and resilience enhancement of Transformer-based models under adversarial attacks. In the evaluation phase, we assess the susceptibility of three Transformer configurations, encoder-decoder, encoder-only, and decoder-only setups, to adversarial attacks of escalating complexity across datasets containing offensive language and misinformation. Encoder-only models manifest a 14% and 21% performance drop in offensive language detection and misinformation detection tasks, respectively. Decoder-only models register a 16% decrease in both tasks, while encoder-decoder models exhibit a maximum performance drop of 14% and 26% in the respective tasks. The resilience-enhancement phase employs adversarial training, integrating pre-camouflaged and dynamically altered data. This approach effectively reduces the performance drop in encoder-only models to an average of 5% in offensive language detection and 2% in misinformation detection tasks. Decoder-only models, occasionally exceeding original performance, limit the performance drop to 7% and 2% in the respective tasks. Although not surpassing the original performance, Encoder-decoder models can reduce the drop to an average of 6% and 2% respectively. Results suggest a trade-off between performance and robustness, with some models maintaining similar performance while gaining robustness. Our study and adversarial training techniques have been incorporated into an open-source tool for generating camouflaged datasets. However, methodology effectiveness depends on the specific camouflage technique and data encountered, emphasizing the need for continued exploration.
A Comparative Study of Machine Learning Algorithms for Anomaly Detection in Industrial Environments: Performance and Environmental Impact
Jul 01, 2023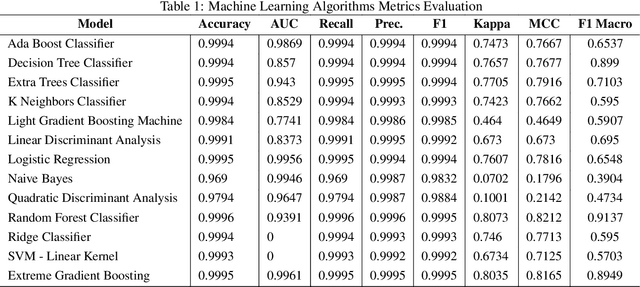
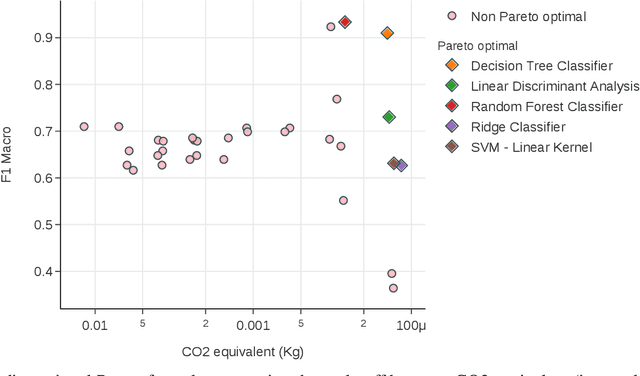
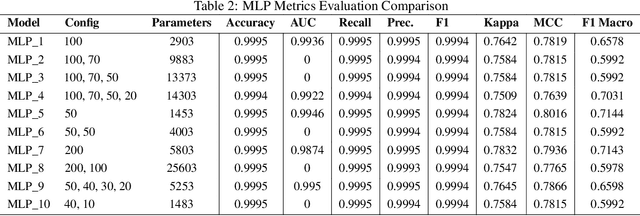
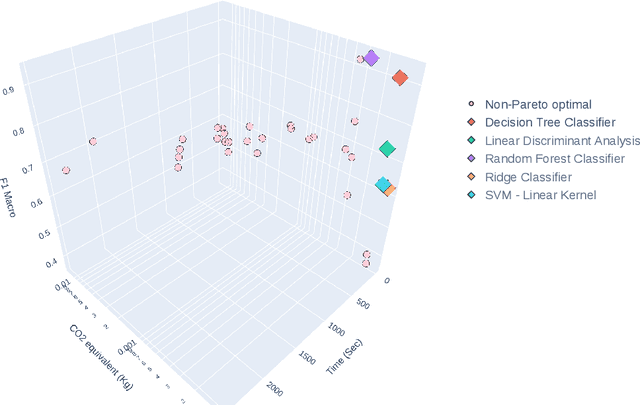
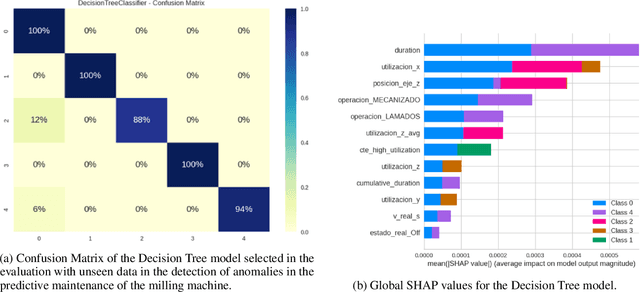
In the context of Industry 4.0, the use of artificial intelligence (AI) and machine learning for anomaly detection is being hampered by high computational requirements and associated environmental effects. This study seeks to address the demands of high-performance machine learning models with environmental sustainability, contributing to the emerging discourse on 'Green AI.' An extensive variety of machine learning algorithms, coupled with various Multilayer Perceptron (MLP) configurations, were meticulously evaluated. Our investigation encapsulated a comprehensive suite of evaluation metrics, comprising Accuracy, Area Under the Curve (AUC), Recall, Precision, F1 Score, Kappa Statistic, Matthews Correlation Coefficient (MCC), and F1 Macro. Simultaneously, the environmental footprint of these models was gauged through considerations of time duration, CO2 equivalent, and energy consumption during the training, cross-validation, and inference phases. Traditional machine learning algorithms, such as Decision Trees and Random Forests, demonstrate robust efficiency and performance. However, superior outcomes were obtained with optimised MLP configurations, albeit with a commensurate increase in resource consumption. The study incorporated a multi-objective optimisation approach, invoking Pareto optimality principles, to highlight the trade-offs between a model's performance and its environmental impact. The insights derived underscore the imperative of striking a balance between model performance, complexity, and environmental implications, thus offering valuable directions for future work in the development of environmentally conscious machine learning models for industrial applications.
Countering Malicious Content Moderation Evasion in Online Social Networks: Simulation and Detection of Word Camouflage
Dec 27, 2022
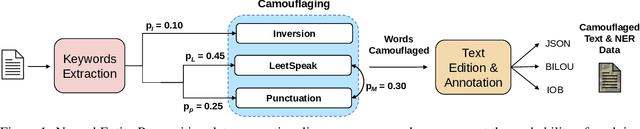
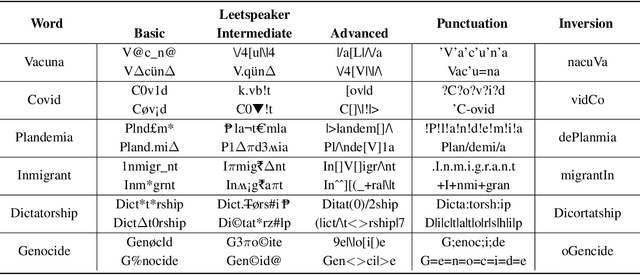
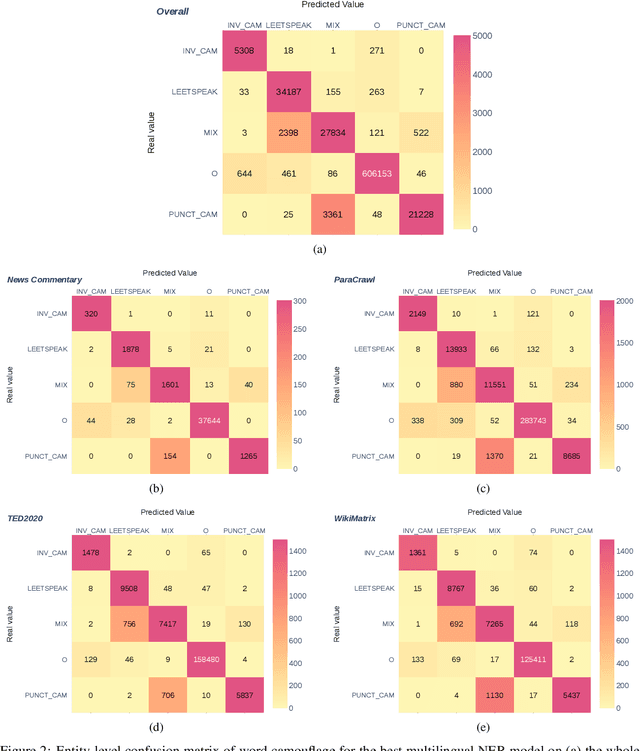
Content moderation is the process of screening and monitoring user-generated content online. It plays a crucial role in stopping content resulting from unacceptable behaviors such as hate speech, harassment, violence against specific groups, terrorism, racism, xenophobia, homophobia, or misogyny, to mention some few, in Online Social Platforms. These platforms make use of a plethora of tools to detect and manage malicious information; however, malicious actors also improve their skills, developing strategies to surpass these barriers and continuing to spread misleading information. Twisting and camouflaging keywords are among the most used techniques to evade platform content moderation systems. In response to this recent ongoing issue, this paper presents an innovative approach to address this linguistic trend in social networks through the simulation of different content evasion techniques and a multilingual Transformer model for content evasion detection. In this way, we share with the rest of the scientific community a multilingual public tool, named "pyleetspeak" to generate/simulate in a customizable way the phenomenon of content evasion through automatic word camouflage and a multilingual Named-Entity Recognition (NER) Transformer-based model tuned for its recognition and detection. The multilingual NER model is evaluated in different textual scenarios, detecting different types and mixtures of camouflage techniques, achieving an overall weighted F1 score of 0.8795. This article contributes significantly to countering malicious information by developing multilingual tools to simulate and detect new methods of evasion of content on social networks, making the fight against information disorders more effective.
Exploring Dimensionality Reduction Techniques in Multilingual Transformers
Apr 18, 2022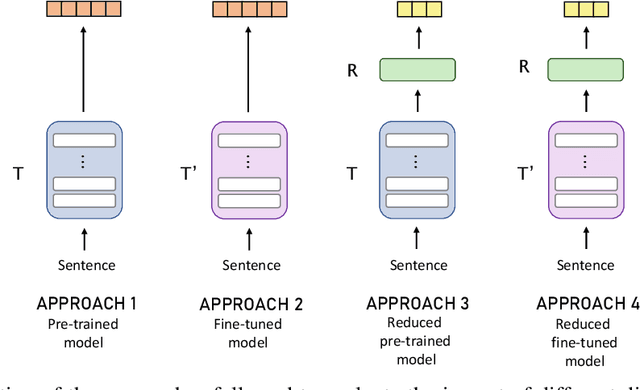
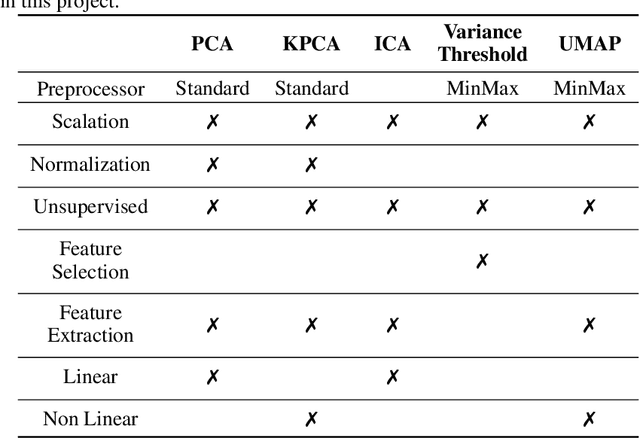
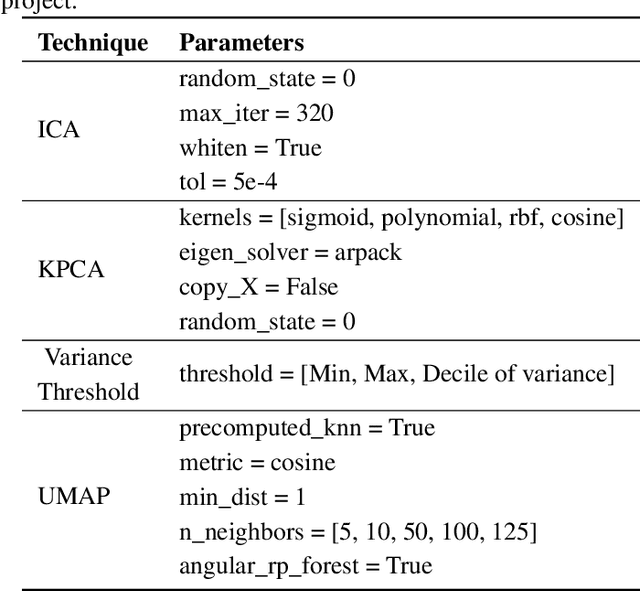
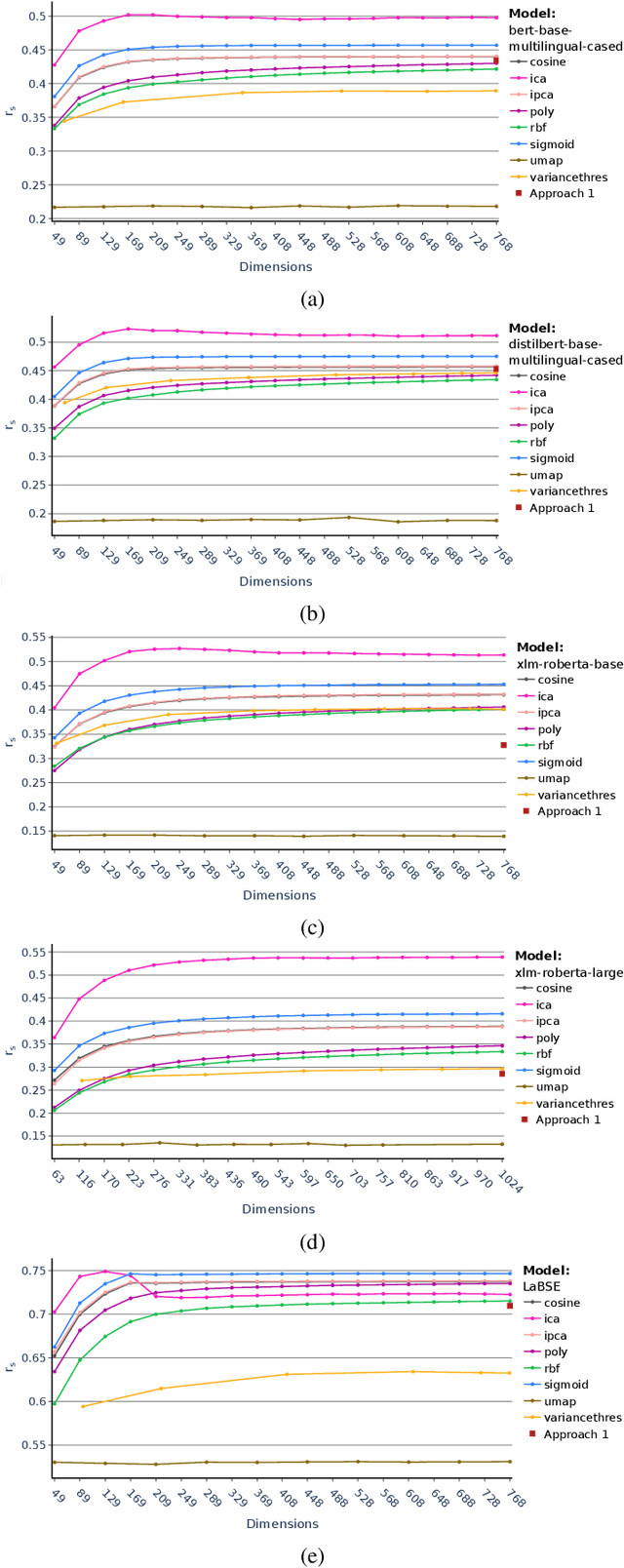
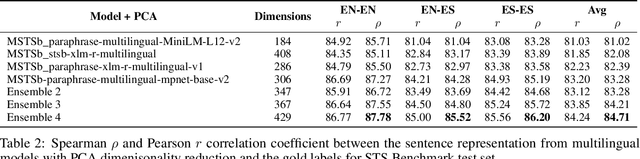
Both in scientific literature and in industry,, Semantic and context-aware Natural Language Processing-based solutions have been gaining importance in recent years. The possibilities and performance shown by these models when dealing with complex Language Understanding tasks is unquestionable, from conversational agents to the fight against disinformation in social networks. In addition, considerable attention is also being paid to developing multilingual models to tackle the language bottleneck. The growing need to provide more complex models implementing all these features has been accompanied by an increase in their size, without being conservative in the number of dimensions required. This paper aims to give a comprehensive account of the impact of a wide variety of dimensional reduction techniques on the performance of different state-of-the-art multilingual Siamese Transformers, including unsupervised dimensional reduction techniques such as linear and nonlinear feature extraction, feature selection, and manifold techniques. In order to evaluate the effects of these techniques, we considered the multilingual extended version of Semantic Textual Similarity Benchmark (mSTSb) and two different baseline approaches, one using the pre-trained version of several models and another using their fine-tuned STS version. The results evidence that it is possible to achieve an average reduction in the number of dimensions of $91.58\% \pm 2.59\%$ and $54.65\% \pm 32.20\%$, respectively. This work has also considered the consequences of dimensionality reduction for visualization purposes. The results of this study will significantly contribute to the understanding of how different tuning approaches affect performance on semantic-aware tasks and how dimensional reduction techniques deal with the high-dimensional embeddings computed for the STS task and their potential for highly demanding NLP tasks
FacTeR-Check: Semi-automated fact-checking through Semantic Similarity and Natural Language Inference
Oct 27, 2021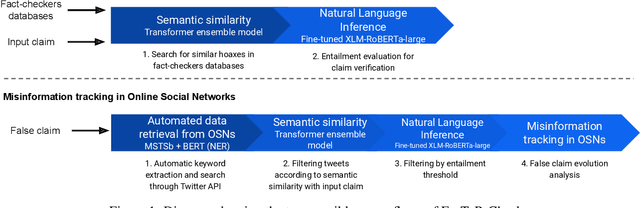
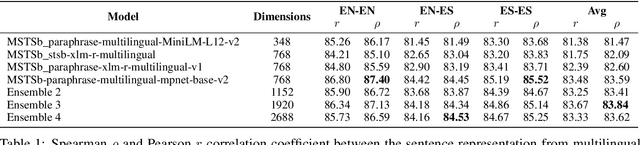
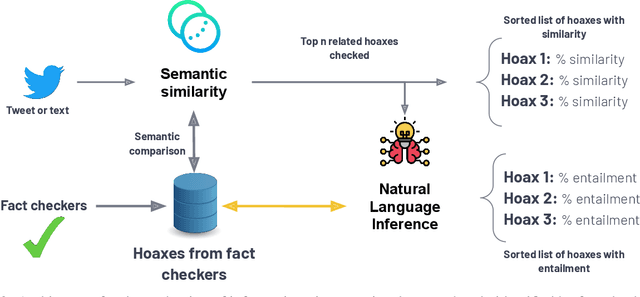
Our society produces and shares overwhelming amounts of information through the Online Social Networks (OSNs). Within this environment, misinformation and disinformation have proliferated, becoming a public safety concern on every country. Allowing the public and professionals to efficiently find reliable evidence about the factual veracity of a claim is crucial to mitigate this harmful spread. To this end, we propose FacTeR-Check, a multilingual architecture for semi-automated fact-checking that can be used for either the general public but also useful for fact-checking organisations. FacTeR-Check enables retrieving fact-checked information, unchecked claims verification and tracking dangerous information over social media. This architectures involves several modules developed to evaluate semantic similarity, to calculate natural language inference and to retrieve information from Online Social Networks. The union of all these modules builds a semi-automated fact-checking tool able of verifying new claims, to extract related evidence, and to track the evolution of a hoax on a OSN. While individual modules are validated on related benchmarks (mainly MSTS and SICK), the complete architecture is validated using a new dataset called NLI19-SP that is publicly released with COVID-19 related hoaxes and tweets from Spanish social media. Our results show state-of-the-art performance on the individual benchmarks, as well as producing useful analysis of the evolution over time of 61 different hoaxes.