 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the boundary on Natural Language Inference
Apr 25, 2025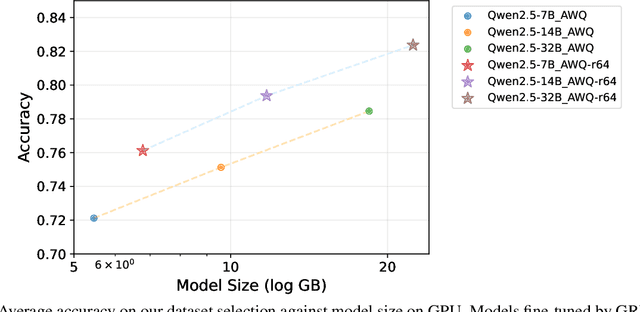
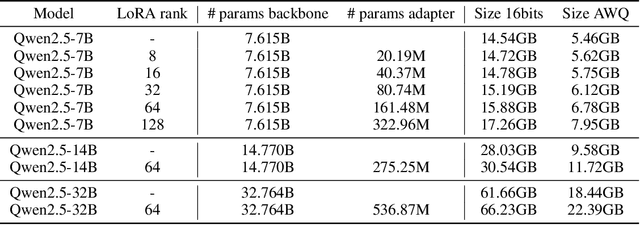
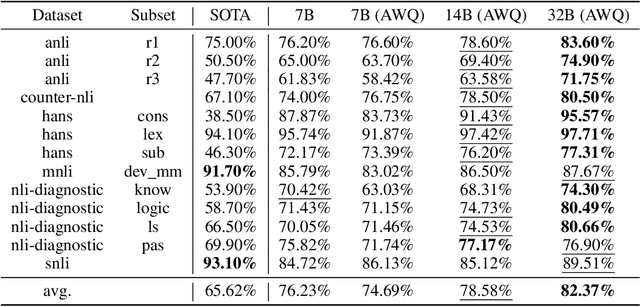
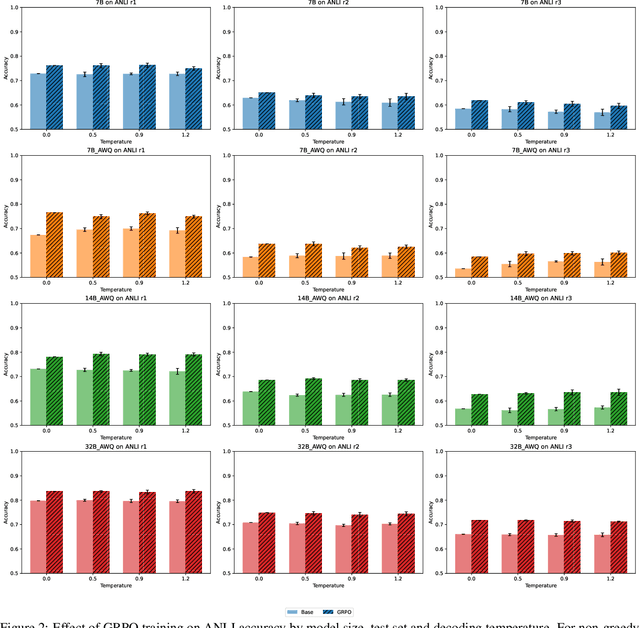
Natural Language Inference (NLI) is a central task in natural language understanding with applications in fact-checking, question answering, and information retrieval. Despite its importance, current NLI systems heavily rely on supervised learning with datasets that often contain annotation artifacts and biases, limiting generalization and real-world applicability. In this work, we apply a reinforcement learning-based approach using Group Relative Policy Optimization (GRPO) for Chain-of-Thought (CoT) learning in NLI, eliminating the need for labeled rationales and enabling this type of training on more challenging datasets such as ANLI. We fine-tune 7B, 14B, and 32B language models using parameter-efficient techniques (LoRA and QLoRA), demonstrating strong performance across standard and adversarial NLI benchmarks. Our 32B AWQ-quantized model surpasses state-of-the-art results on 7 out of 11 adversarial sets$\unicode{x2013}$or on all of them considering our replication$\unicode{x2013}$within a 22GB memory footprint, showing that robust reasoning can be retained under aggressive quantization. This work provides a scalable and practical framework for building robust NLI systems without sacrificing inference quality.
On the locality bias and results in the Long Range Arena
Jan 24, 2025The Long Range Arena (LRA) benchmark was designed to evaluate the performance of Transformer improvements and alternatives in long-range dependency modeling tasks. The Transformer and its main variants performed poorly on this benchmark, and a new series of architectures such as State Space Models (SSMs) gained some traction, greatly outperforming Transformers in the LRA. Recent work has shown that with a denoising pre-training phase, Transformers can achieve competitive results in the LRA with these new architectures. In this work, we discuss and explain the superiority of architectures such as MEGA and SSMs in the Long Range Arena, as well as the recent improvement in the results of Transformers, pointing to the positional and local nature of the tasks. We show that while the LRA is a benchmark for long-range dependency modeling, in reality most of the performance comes from short-range dependencies. Using training techniques to mitigate data inefficiency, Transformers are able to reach state-of-the-art performance with proper positional encoding. In addition, with the same techniques, we were able to remove all restrictions from SSM convolutional kernels and learn fully parameterized convolutions without decreasing performance, suggesting that the design choices behind SSMs simply added inductive biases and learning efficiency for these particular tasks. Our insights indicate that LRA results should be interpreted with caution and call for a redesign of the benchmark.
Not all tokens are created equal: Perplexity Attention Weighted Networks for AI generated text detection
Jan 07, 2025



The rapid advancement in large language models (LLMs) has significantly enhanced their ability to generate coherent and contextually relevant text, raising concerns about the misuse of AI-generated content and making it critical to detect it. However, the task remains challenging, particularly in unseen domains or with unfamiliar LLMs. Leveraging LLM next-token distribution outputs offers a theoretically appealing approach for detection, as they encapsulate insights from the models' extensive pre-training on diverse corpora. Despite its promise, zero-shot methods that attempt to operationalize these outputs have met with limited success. We hypothesize that one of the problems is that they use the mean to aggregate next-token distribution metrics across tokens, when some tokens are naturally easier or harder to predict and should be weighted differently. Based on this idea, we propose the Perplexity Attention Weighted Network (PAWN), which uses the last hidden states of the LLM and positions to weight the sum of a series of features based on metrics from the next-token distribution across the sequence length. Although not zero-shot, our method allows us to cache the last hidden states and next-token distribution metrics on disk, greatly reducing the training resource requirements. PAWN shows competitive and even better performance in-distribution than the strongest baselines (fine-tuned LMs) with a fraction of their trainable parameters. Our model also generalizes better to unseen domains and source models, with smaller variability in the decision boundary across distribution shifts. It is also more robust to adversarial attacks, and if the backbone has multilingual capabilities, it presents decent generalization to languages not seen during supervised training, with LLaMA3-1B reaching a mean macro-averaged F1 score of 81.46% in cross-validation with nine languages.