 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning Algorithms for Graphical Model Selection
Paper and Code
Apr 07, 2016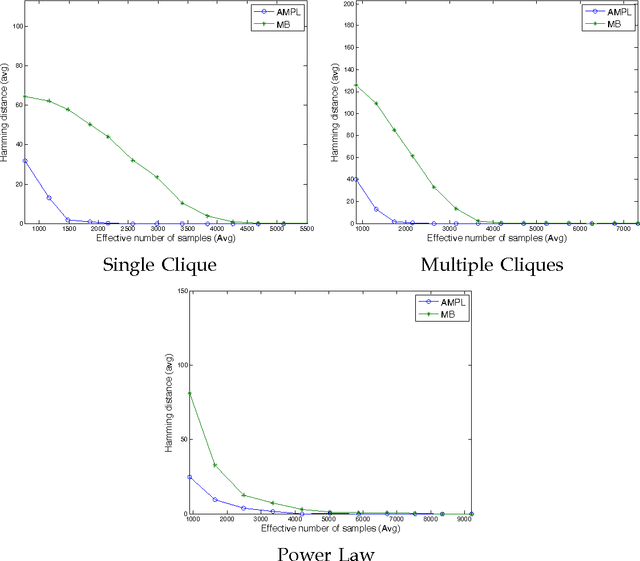
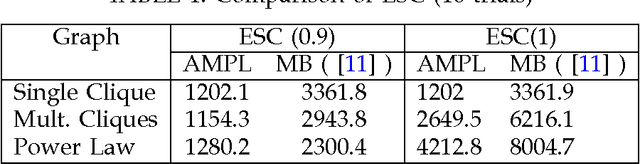
The problem of learning the structure of a high dimensional graphical model from data has received considerable attention in recent years. In many applications such as sensor networks and proteomics it is often expensive to obtain samples from all the variables involved simultaneously. For instance, this might involve the synchronization of a large number of sensors or the tagging of a large number of proteins. To address this important issue, we initiate the study of a novel graphical model selection problem, where the goal is to optimize the total number of scalar samples obtained by allowing the collection of samples from only subsets of the variables. We propose a general paradigm for graphical model selection where feedback is used to guide the sampling to high degree vertices, while obtaining only few samples from the ones with the low degrees. We instantiate this framework with two specific active learning algorithms, one of which makes mild assumptions but is computationally expensive, while the other is more computationally efficient but requires stronger (nevertheless standard) assumptions. Whereas the sample complexity of passive algorithms is typically a function of the maximum degree of the graph, we show that the sample complexity of our algorithms is provable smaller and that it depends on a novel local complexity measure that is akin to the average degree of the graph. We finally demonstrate the efficacy of our framework via simulations.