 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasar: Datasets for Question Answering by Search and Reading
Paper and Code



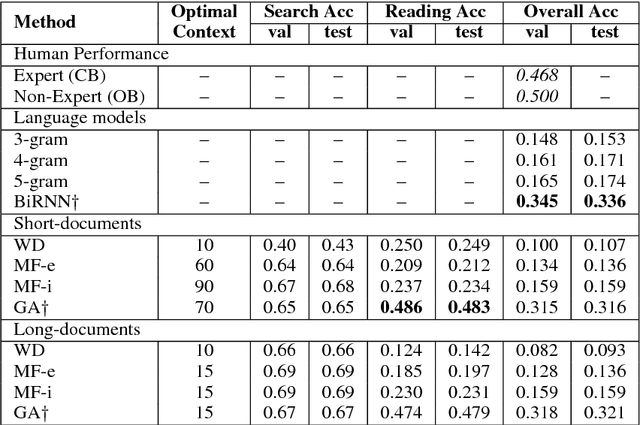
We present two new large-scale datasets aimed at evaluating systems designed to comprehend a natural language query and extract its answer from a large corpus of text. The Quasar-S dataset consists of 37000 cloze-style (fill-in-the-gap) queries constructed from definitions of software entity tags on the popular website Stack Overflow. The posts and comments on the website serve as the background corpus for answering the cloze questions. The Quasar-T dataset consists of 43000 open-domain trivia questions and their answers obtained from various internet sources. ClueWeb09 serves as the background corpus for extracting these answers. We pose these datasets as a challenge for two related subtasks of factoid Question Answering: (1) searching for relevant pieces of text that include the correct answer to a query, and (2) reading the retrieved text to answer the query. We also describe a retrieval system for extracting relevant sentences and documents from the corpus given a query, and include these in the release for researchers wishing to only focus on (2). We evaluate several baselines on both datasets, ranging from simple heuristics to powerful neural models, and show that these lag behind human performance by 16.4% and 32.1% for Quasar-S and -T respectively. The datasets are available at https://github.com/bdhingra/quasar .