 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Mean Discrepancy Meets Neural Networks: The Radon-Kolmogorov-Smirnov Test
Sep 13, 2023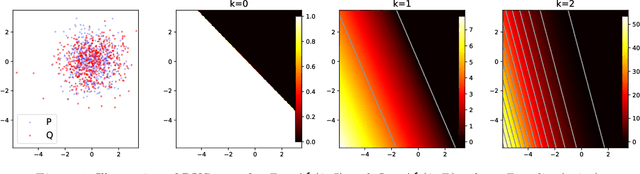

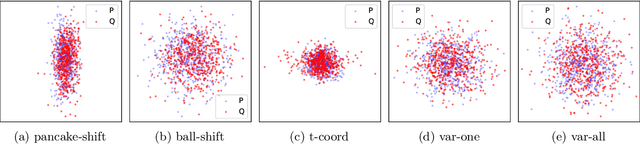
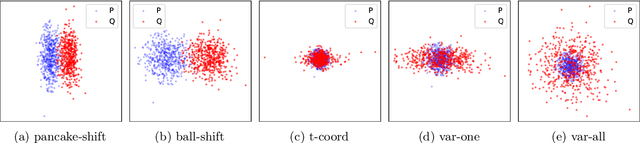
Maximum mean discrepancy (MMD) refers to a general class of nonparametric two-sample tests that are based on maximizing the mean difference over samples from one distribution $P$ versus another $Q$, over all choices of data transformations $f$ living in some function space $\mathcal{F}$. Inspired by recent work that connects what are known as functions of $\textit{Radon bounded variation}$ (RBV) and neural networks (Parhi and Nowak, 2021, 2023), we study the MMD defined by taking $\mathcal{F}$ to be the unit ball in the RBV space of a given smoothness order $k \geq 0$. This test, which we refer to as the $\textit{Radon-Kolmogorov-Smirnov}$ (RKS) test, can be viewed as a generalization of the well-known and classical Kolmogorov-Smirnov (KS) test to multiple dimensions and higher orders of smoothness. It is also intimately connected to neural networks: we prove that the witness in the RKS test -- the function $f$ achieving the maximum mean difference -- is always a ridge spline of degree $k$, i.e., a single neuron in a neural network. This allows us to leverage the power of modern deep learning toolkits to (approximately) optimize the criterion that underlies the RKS test. We prove that the RKS test has asymptotically full power at distinguishing any distinct pair $P \not= Q$ of distributions, derive its asymptotic null distribution, and carry out extensive experiments to elucidate the strengths and weakenesses of the RKS test versus the more traditional kernel MMD test.
The Voronoigram: Minimax Estimation of Bounded Variation Functions From Scattered Data
Dec 30, 2022



We consider the problem of estimating a multivariate function $f_0$ of bounded variation (BV), from noisy observations $y_i = f_0(x_i) + z_i$ made at random design points $x_i \in \mathbb{R}^d$, $i=1,\ldots,n$. We study an estimator that forms the Voronoi diagram of the design points, and then solves an optimization problem that regularizes according to a certain discrete notion of total variation (TV): the sum of weighted absolute differences of parameters $\theta_i,\theta_j$ (which estimate the function values $f_0(x_i),f_0(x_j)$) at all neighboring cells $i,j$ in the Voronoi diagram. This is seen to be equivalent to a variational optimization problem that regularizes according to the usual continuum (measure-theoretic) notion of TV, once we restrict the domain to functions that are piecewise constant over the Voronoi diagram. The regression estimator under consideration hence performs (shrunken) local averaging over adaptively formed unions of Voronoi cells, and we refer to it as the Voronoigram, following the ideas in Koenker (2005), and drawing inspiration from Tukey's regressogram (Tukey, 1961). Our contributions in this paper span both the conceptual and theoretical frontiers: we discuss some of the unique properties of the Voronoigram in comparison to TV-regularized estimators that use other graph-based discretizations; we derive the asymptotic limit of the Voronoi TV functional; and we prove that the Voronoigram is minimax rate optimal (up to log factors) for estimating BV functions that are essentially bounded.
Minimax Optimal Regression over Sobolev Spaces via Laplacian Eigenmaps on Neighborhood Graphs
Nov 14, 2021
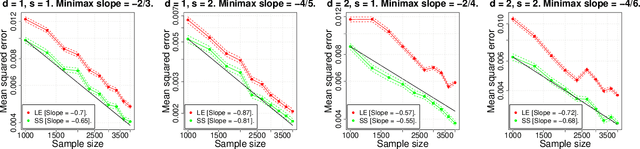
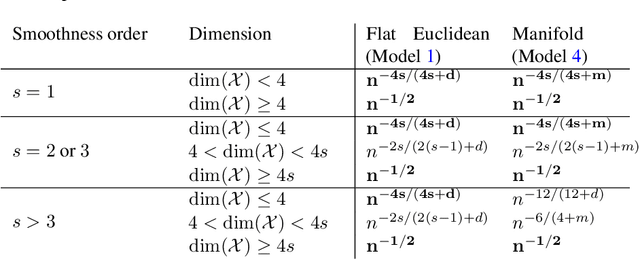
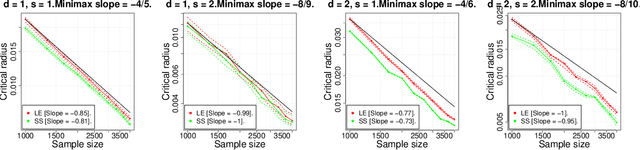
In this paper we study the statistical properties of Principal Components Regression with Laplacian Eigenmaps (PCR-LE), a method for nonparametric regression based on Laplacian Eigenmaps (LE). PCR-LE works by projecting a vector of observed responses ${\bf Y} = (Y_1,\ldots,Y_n)$ onto a subspace spanned by certain eigenvectors of a neighborhood graph Laplacian. We show that PCR-LE achieves minimax rates of convergence for random design regression over Sobolev spaces. Under sufficient smoothness conditions on the design density $p$, PCR-LE achieves the optimal rates for both estimation (where the optimal rate in squared $L^2$ norm is known to be $n^{-2s/(2s + d)}$) and goodness-of-fit testing ($n^{-4s/(4s + d)}$). We also show that PCR-LE is \emph{manifold adaptive}: that is, we consider the situation where the design is supported on a manifold of small intrinsic dimension $m$, and give upper bounds establishing that PCR-LE achieves the faster minimax estimation ($n^{-2s/(2s + m)}$) and testing ($n^{-4s/(4s + m)}$) rates of convergence. Interestingly, these rates are almost always much faster than the known rates of convergence of graph Laplacian eigenvectors to their population-level limits; in other words, for this problem regression with estimated features appears to be much easier, statistically speaking, than estimating the features itself. We support these theoretical results with empirical evidence.
Minimax Optimal Regression over Sobolev Spaces via Laplacian Regularization on Neighborhood Graphs
Jun 03, 2021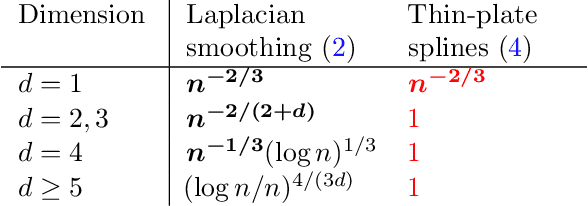
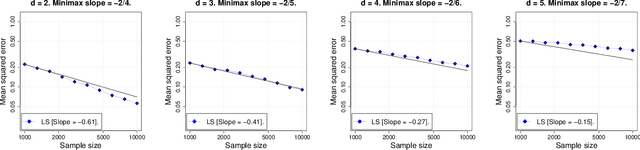

In this paper we study the statistical properties of Laplacian smoothing, a graph-based approach to nonparametric regression. Under standard regularity conditions, we establish upper bounds on the error of the Laplacian smoothing estimator $\widehat{f}$, and a goodness-of-fit test also based on $\widehat{f}$. These upper bounds match the minimax optimal estimation and testing rates of convergence over the first-order Sobolev class $H^1(\mathcal{X})$, for $\mathcal{X}\subseteq \mathbb{R}^d$ and $1 \leq d < 4$; in the estimation problem, for $d = 4$, they are optimal modulo a $\log n$ factor. Additionally, we prove that Laplacian smoothing is manifold-adaptive: if $\mathcal{X} \subseteq \mathbb{R}^d$ is an $m$-dimensional manifold with $m < d$, then the error rate of Laplacian smoothing (in either estimation or testing) depends only on $m$, in the same way it would if $\mathcal{X}$ were a full-dimensional set in $\mathbb{R}^d$.