 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Multi-Level Quantile Forecasting
Dec 29, 2025We present an online method for guaranteeing calibration of quantile forecasts at multiple quantile levels simultaneously. A sequence of $α$-level quantile forecasts is calibrated if the forecasts are larger than the target value at an $α$-fraction of time steps. We introduce a lightweight method called Multi-Level Quantile Tracker (MultiQT) that wraps around any existing point or quantile forecaster to produce corrected forecasts guaranteed to achieve calibration, even against adversarial distribution shifts, while ensuring that the forecasts are ordered -- e.g., the 0.5-level quantile forecast is never larger than the 0.6-level forecast. Furthermore, the method comes with a no-regret guarantee that implies it will not worsen the performance of an existing forecaster, asymptotically, with respect to the quantile loss. In experiments, we find that MultiQT significantly improves the calibration of real forecasters in epidemic and energy forecasting problems.
Conformal Prediction for Long-Tailed Classification
Jul 09, 2025



Many real-world classification problems, such as plant identification, have extremely long-tailed class distributions. In order for prediction sets to be useful in such settings, they should (i) provide good class-conditional coverage, ensuring that rare classes are not systematically omitted from the prediction sets, and (ii) be a reasonable size, allowing users to easily verify candidate labels. Unfortunately, existing conformal prediction methods, when applied to the long-tailed setting, force practitioners to make a binary choice between small sets with poor class-conditional coverage or sets with very good class-conditional coverage but that are extremely large. We propose methods with guaranteed marginal coverage that smoothly trade off between set size and class-conditional coverage. First, we propose a conformal score function, prevalence-adjusted softmax, that targets a relaxed notion of class-conditional coverage called macro-coverage. Second, we propose a label-weighted conformal prediction method that allows us to interpolate between marginal and class-conditional conformal prediction. We demonstrate our methods on Pl@ntNet and iNaturalist, two long-tailed image datasets with 1,081 and 8,142 classes, respectively.
Class-Conditional Conformal Prediction With Many Classes
Jun 15, 2023

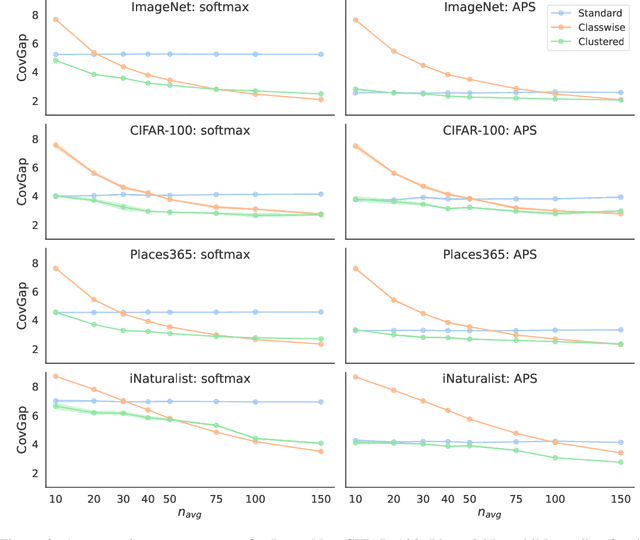
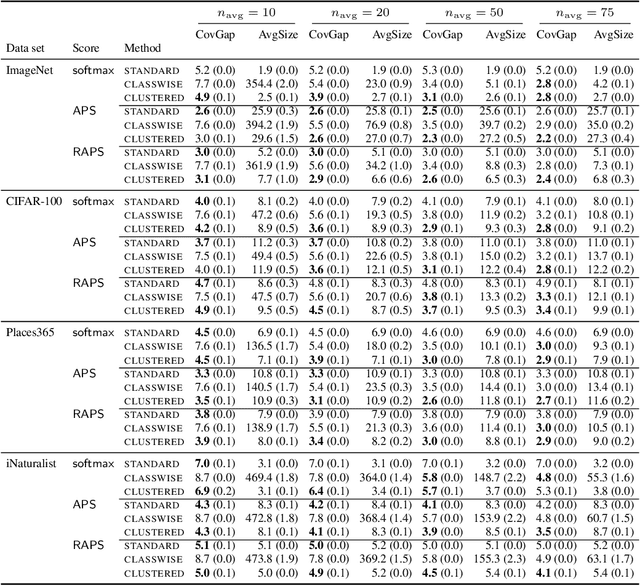
Standard conformal prediction methods provide a marginal coverage guarantee, which means that for a random test point, the conformal prediction set contains the true label with a user-chosen probability. In many classification problems, we would like to obtain a stronger guarantee -- that for test points of a specific class, the prediction set contains the true label with the same user-chosen probability. Existing conformal prediction methods do not work well when there is a limited amount of labeled data per class, as is often the case in real applications where the number of classes is large. We propose a method called clustered conformal prediction, which clusters together classes that have "similar" conformal scores and then performs conformal prediction at the cluster level. Based on empirical evaluation across four image data sets with many (up to 1000) classes, we find that clustered conformal typically outperforms existing methods in terms of class-conditional coverage and set size metrics.
Learning from Multiple Noisy Partial Labelers
Jun 08, 2021


Programmatic weak supervision creates models without hand-labeled training data by combining the outputs of noisy, user-written rules and other heuristic labelers. Existing frameworks make the restrictive assumption that labelers output a single class label. Enabling users to create partial labelers that output subsets of possible class labels would greatly expand the expressivity of programmatic weak supervision. We introduce this capability by defining a probabilistic generative model that can estimate the underlying accuracies of multiple noisy partial labelers without ground truth labels. We prove that this class of models is generically identifiable up to label swapping under mild conditions. We also show how to scale up learning to 100k examples in one minute, a 300X speed up compared to a naive implementation. We evaluate our framework on three text classification and six object classification tasks. On text tasks, adding partial labels increases average accuracy by 9.6 percentage points. On image tasks, we show that partial labels allow us to approach some zero-shot object classification problems with programmatic weak supervision by using class attributes as partial labelers. Our framework is able to achieve accuracy comparable to recent embedding-based zero-shot learning methods using only pre-trained attribute detectors