 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction for Long-Tailed Classification
Jul 09, 2025Many real-world classification problems, such as plant identification, have extremely long-tailed class distributions. In order for prediction sets to be useful in such settings, they should (i) provide good class-conditional coverage, ensuring that rare classes are not systematically omitted from the prediction sets, and (ii) be a reasonable size, allowing users to easily verify candidate labels. Unfortunately, existing conformal prediction methods, when applied to the long-tailed setting, force practitioners to make a binary choice between small sets with poor class-conditional coverage or sets with very good class-conditional coverage but that are extremely large. We propose methods with guaranteed marginal coverage that smoothly trade off between set size and class-conditional coverage. First, we propose a conformal score function, prevalence-adjusted softmax, that targets a relaxed notion of class-conditional coverage called macro-coverage. Second, we propose a label-weighted conformal prediction method that allows us to interpolate between marginal and class-conditional conformal prediction. We demonstrate our methods on Pl@ntNet and iNaturalist, two long-tailed image datasets with 1,081 and 8,142 classes, respectively.
Transductive Conformal Inference for Ranking
Jan 20, 2025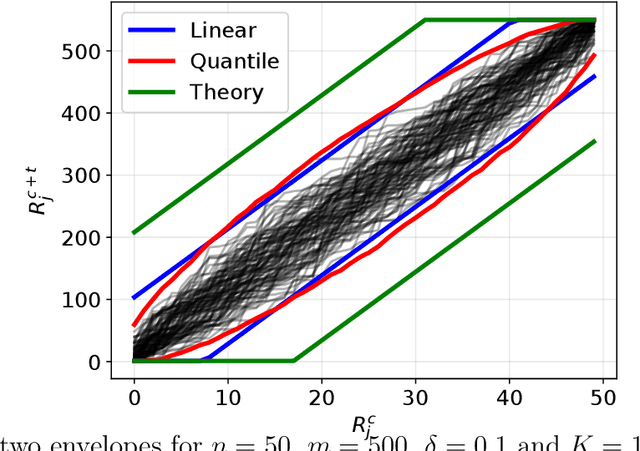


We introduce a method based on Conformal Prediction (CP) to quantify the uncertainty of full ranking algorithms. We focus on a specific scenario where $n + m$ items are to be ranked by some ''black box'' algorithm. It is assumed that the relative (ground truth) ranking of n of them is known. The objective is then to quantify the error made by the algorithm on the ranks of the m new items among the total $(n + m)$. In such a setting, the true ranks of the n original items in the total $(n + m)$ depend on the (unknown) true ranks of the m new ones. Consequently, we have no direct access to a calibration set to apply a classical CP method. To address this challenge, we propose to construct distribution-free bounds of the unknown conformity scores using recent results on the distribution of conformal p-values. Using these scores upper bounds, we provide valid prediction sets for the rank of any item. We also control the false coverage proportion, a crucial quantity when dealing with multiple prediction sets. Finally, we empirically show on both synthetic and real data the efficiency of our CP method.
Estimation of multiple mean vectors in high dimension
Mar 22, 2024

We endeavour to estimate numerous multi-dimensional means of various probability distributions on a common space based on independent samples. Our approach involves forming estimators through convex combinations of empirical means derived from these samples. We introduce two strategies to find appropriate data-dependent convex combination weights: a first one employing a testing procedure to identify neighbouring means with low variance, which results in a closed-form plug-in formula for the weights, and a second one determining weights via minimization of an upper confidence bound on the quadratic risk.Through theoretical analysis, we evaluate the improvement in quadratic risk offered by our methods compared to the empirical means. Our analysis focuses on a dimensional asymptotics perspective, showing that our methods asymptotically approach an oracle (minimax) improvement as the effective dimension of the data increases.We demonstrate the efficacy of our methods in estimating multiple kernel mean embeddings through experiments on both simulated and real-world datasets.
Nonasymptotic one-and two-sample tests in high dimension with unknown covariance structure
Sep 01, 2021Let $\mathbf{X} = (X_i)_{1\leq i \leq n}$ be an i.i.d. sample of square-integrable variables in $\mathbb{R}^d$, with common expectation $\mu$ and covariance matrix $\Sigma$, both unknown. We consider the problem of testing if $\mu$ is $\eta$-close to zero, i.e. $\|\mu\| \leq \eta $ against $\|\mu\| \geq (\eta + \delta)$; we also tackle the more general two-sample mean closeness testing problem. The aim of this paper is to obtain nonasymptotic upper and lower bounds on the minimal separation distance $\delta$ such that we can control both the Type I and Type II errors at a given level. The main technical tools are concentration inequalities, first for a suitable estimator of $\|\mu\|^2$ used a test statistic, and secondly for estimating the operator and Frobenius norms of $\Sigma$ coming into the quantiles of said test statistic. These properties are obtained for Gaussian and bounded distributions. A particular attention is given to the dependence in the pseudo-dimension $d_*$ of the distribution, defined as $d_* := \|\Sigma\|_2^2/\|\Sigma\|_\infty^2$. In particular, for $\eta=0$, the minimum separation distance is ${\Theta}(d_*^{\frac{1}{4}}\sqrt{\|\Sigma\|_\infty/n})$, in contrast with the minimax estimation distance for $\mu$, which is ${\Theta}(d_e^{\frac{1}{2}}\sqrt{\|\Sigma\|_\infty/n})$ (where $d_e:=\|\Sigma\|_1/\|\Sigma\|_\infty$). This generalizes a phenomenon spelled out in particular by Baraud (2002).
High-Dimensional Multi-Task Averaging and Application to Kernel Mean Embedding
Nov 13, 2020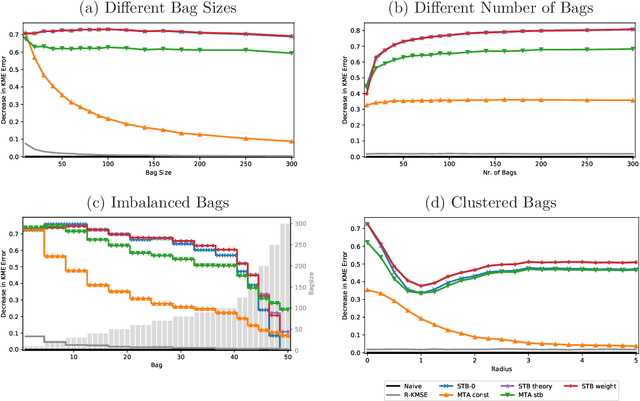


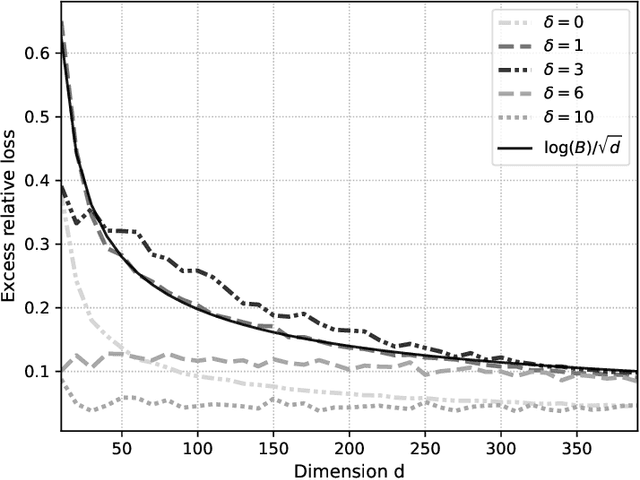
We propose an improved estimator for the multi-task averaging problem, whose goal is the joint estimation of the means of multiple distributions using separate, independent data sets. The naive approach is to take the empirical mean of each data set individually, whereas the proposed method exploits similarities between tasks, without any related information being known in advance. First, for each data set, similar or neighboring means are determined from the data by multiple testing. Then each naive estimator is shrunk towards the local average of its neighbors. We prove theoretically that this approach provides a reduction in mean squared error. This improvement can be significant when the dimension of the input space is large, demonstrating a "blessing of dimensionality" phenomenon. An application of this approach is the estimation of multiple kernel mean embeddings, which plays an important role in many modern applications. The theoretical results are verified on artificial and real world data.