 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up ridge regression for brain encoding in a massive individual fMRI dataset
Mar 28, 2024



Brain encoding with neuroimaging data is an established analysis aimed at predicting human brain activity directly from complex stimuli features such as movie frames. Typically, these features are the latent space representation from an artificial neural network, and the stimuli are image, audio, or text inputs. Ridge regression is a popular prediction model for brain encoding due to its good out-of-sample generalization performance. However, training a ridge regression model can be highly time-consuming when dealing with large-scale deep functional magnetic resonance imaging (fMRI) datasets that include many space-time samples of brain activity. This paper evaluates different parallelization techniques to reduce the training time of brain encoding with ridge regression on the CNeuroMod Friends dataset, one of the largest deep fMRI resource currently available. With multi-threading, our results show that the Intel Math Kernel Library (MKL) significantly outperforms the OpenBLAS library, being 1.9 times faster using 32 threads on a single machine. We then evaluated the Dask multi-CPU implementation of ridge regression readily available in scikit-learn (MultiOutput), and we proposed a new "batch" version of Dask parallelization, motivated by a time complexity analysis. In line with our theoretical analysis, MultiOutput parallelization was found to be impractical, i.e., slower than multi-threading on a single machine. In contrast, the Batch-MultiOutput regression scaled well across compute nodes and threads, providing speed-ups of up to 33 times with 8 compute nodes and 32 threads compared to a single-threaded scikit-learn execution. Batch parallelization using Dask thus emerges as a scalable approach for brain encoding with ridge regression on high-performance computing systems using scikit-learn and large fMRI datasets.
Corrected generalized cross-validation for finite ensembles of penalized estimators
Oct 02, 2023


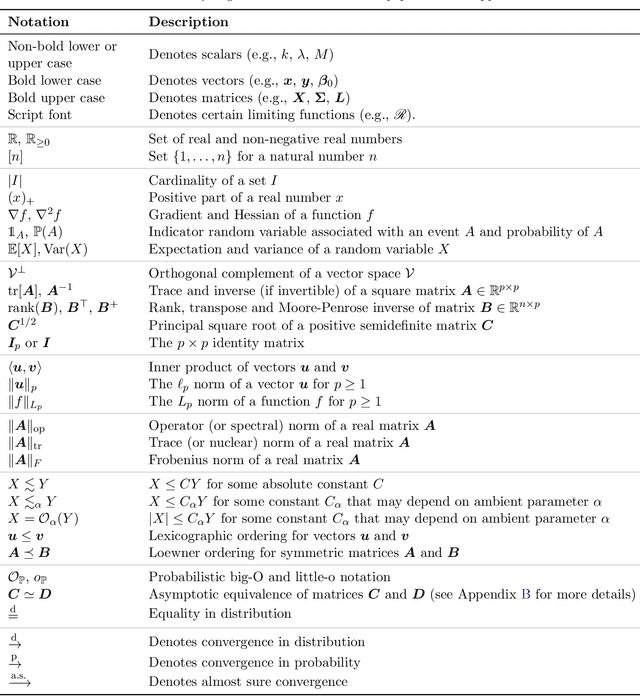
Generalized cross-validation (GCV) is a widely-used method for estimating the squared out-of-sample prediction risk that employs a scalar degrees of freedom adjustment (in a multiplicative sense) to the squared training error. In this paper, we examine the consistency of GCV for estimating the prediction risk of arbitrary ensembles of penalized least squares estimators. We show that GCV is inconsistent for any finite ensemble of size greater than one. Towards repairing this shortcoming, we identify a correction that involves an additional scalar correction (in an additive sense) based on degrees of freedom adjusted training errors from each ensemble component. The proposed estimator (termed CGCV) maintains the computational advantages of GCV and requires neither sample splitting, model refitting, or out-of-bag risk estimation. The estimator stems from a finer inspection of ensemble risk decomposition and two intermediate risk estimators for the components in this decomposition. We provide a non-asymptotic analysis of the CGCV and the two intermediate risk estimators for ensembles of convex penalized estimators under Gaussian features and a linear response model. In the special case of ridge regression, we extend the analysis to general feature and response distributions using random matrix theory, which establishes model-free uniform consistency of CGCV.
Neuroevolution of Recurrent Architectures on Control Tasks
Apr 03, 2023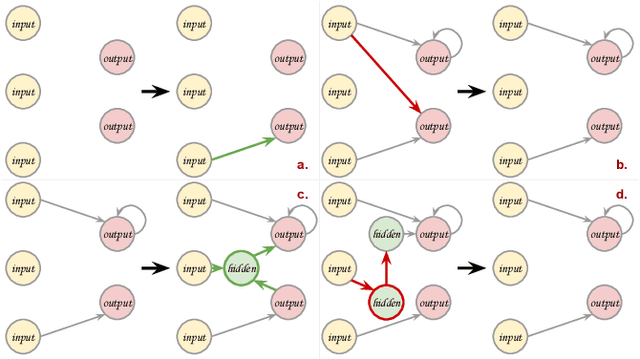
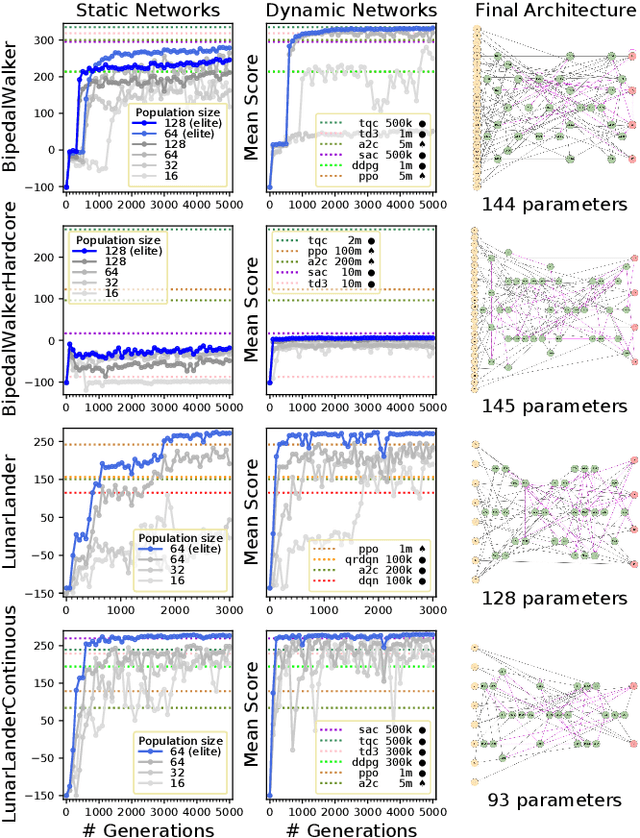
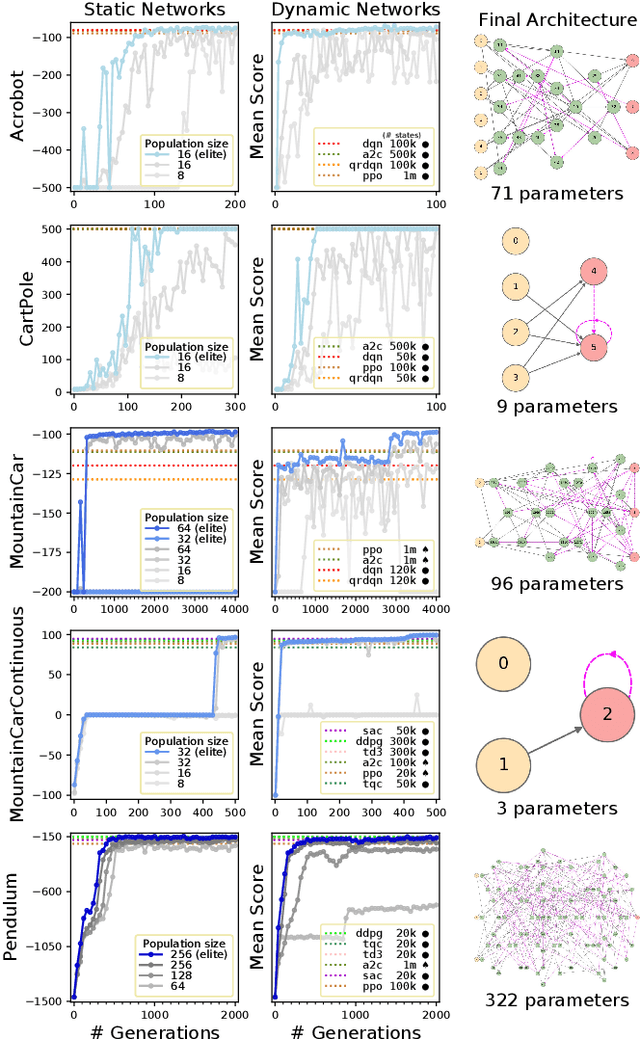
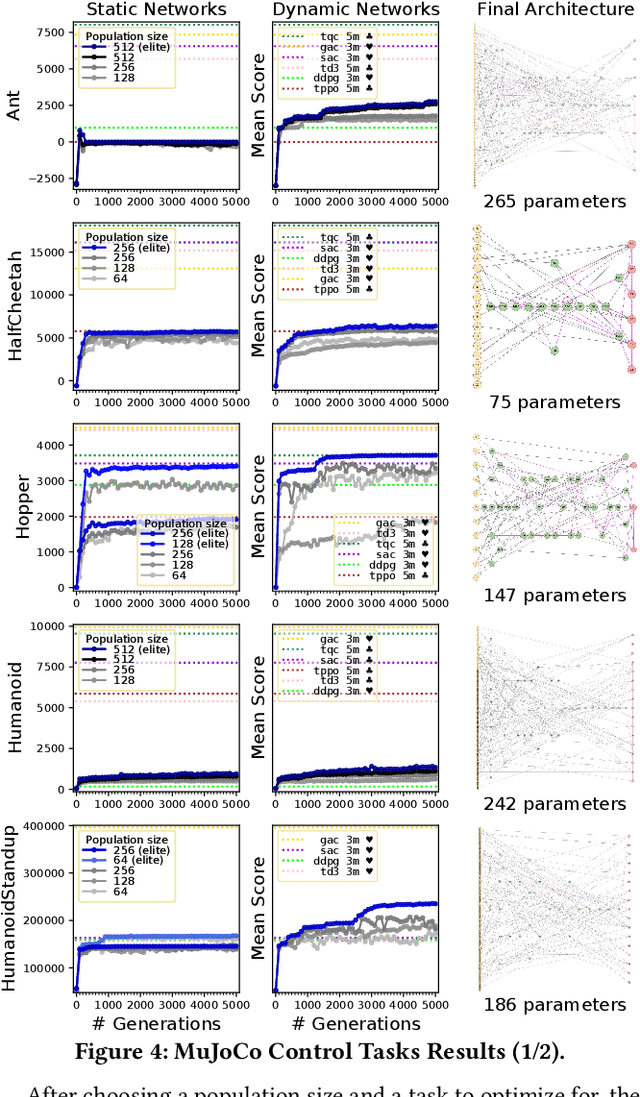
Modern artificial intelligence works typically train the parameters of fixed-sized deep neural networks using gradient-based optimization techniques. Simple evolutionary algorithms have recently been shown to also be capable of optimizing deep neural network parameters, at times matching the performance of gradient-based techniques, e.g. in reinforcement learning settings. In addition to optimizing network parameters, many evolutionary computation techniques are also capable of progressively constructing network architectures. However, constructing network architectures from elementary evolution rules has not yet been shown to scale to modern reinforcement learning benchmarks. In this paper we therefore propose a new approach in which the architectures of recurrent neural networks dynamically evolve according to a small set of mutation rules. We implement a massively parallel evolutionary algorithm and run experiments on all 19 OpenAI Gym state-based reinforcement learning control tasks. We find that in most cases, dynamic agents match or exceed the performance of gradient-based agents while utilizing orders of magnitude fewer parameters. We believe our work to open avenues for real-life applications where network compactness and autonomous design are of critical importance. We provide our source code, final model checkpoints and full results at github.com/MaximilienLC/nra.
Generative Adversarial Neuroevolution for Control Behaviour Imitation
Apr 03, 2023

There is a recent surge in interest for imitation learning, with large human video-game and robotic manipulation datasets being used to train agents on very complex tasks. While deep neuroevolution has recently been shown to match the performance of gradient-based techniques on various reinforcement learning problems, the application of deep neuroevolution techniques to imitation learning remains relatively unexplored. In this work, we propose to explore whether deep neuroevolution can be used for behaviour imitation on popular simulation environments. We introduce a simple co-evolutionary adversarial generation framework, and evaluate its capabilities by evolving standard deep recurrent networks to imitate state-of-the-art pre-trained agents on 8 OpenAI Gym state-based control tasks. Across all tasks, we find the final elite actor agents capable of achieving scores as high as those obtained by the pre-trained agents, all the while closely following their score trajectories. Our results suggest that neuroevolution could be a valuable addition to deep learning techniques to produce accurate emulation of behavioural agents. We believe that the generality and simplicity of our approach opens avenues for imitating increasingly complex behaviours in increasingly complex settings, e.g. human behaviour in real-world settings. We provide our source code, model checkpoints and results at github.com/MaximilienLC/gane.
A brain signature highly predictive of future progression to Alzheimer's dementia
Mar 02, 2018
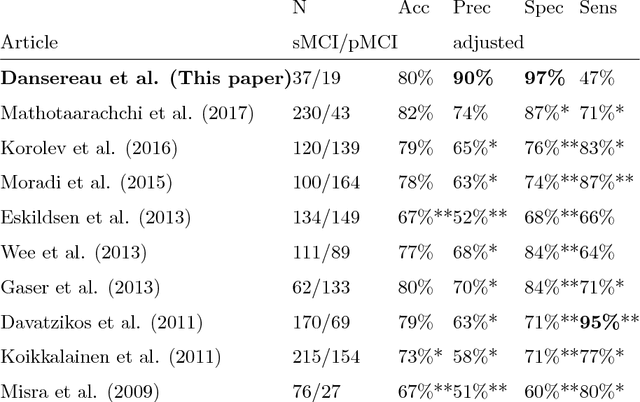
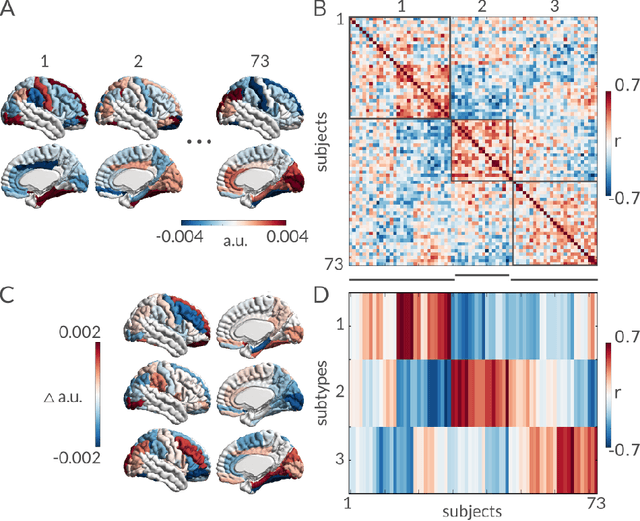
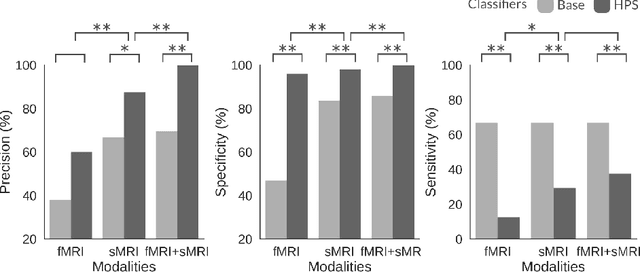
Early prognosis of Alzheimer's dementia is hard. Mild cognitive impairment (MCI) typically precedes Alzheimer's dementia, yet only a fraction of MCI individuals will progress to dementia, even when screened using biomarkers. We propose here to identify a subset of individuals who share a common brain signature highly predictive of oncoming dementia. This signature was composed of brain atrophy and functional dysconnectivity and discovered using a machine learning model in patients suffering from dementia. The model recognized the same brain signature in MCI individuals, 90% of which progressed to dementia within three years. This result is a marked improvement on the state-of-the-art in prognostic precision, while the brain signature still identified 47% of all MCI progressors. We thus discovered a sizable MCI subpopulation which represents an excellent recruitment target for clinical trials at the prodromal stage of Alzheimer's disease.
Statistical power and prediction accuracy in multisite resting-state fMRI connectivity
Jan 27, 2017
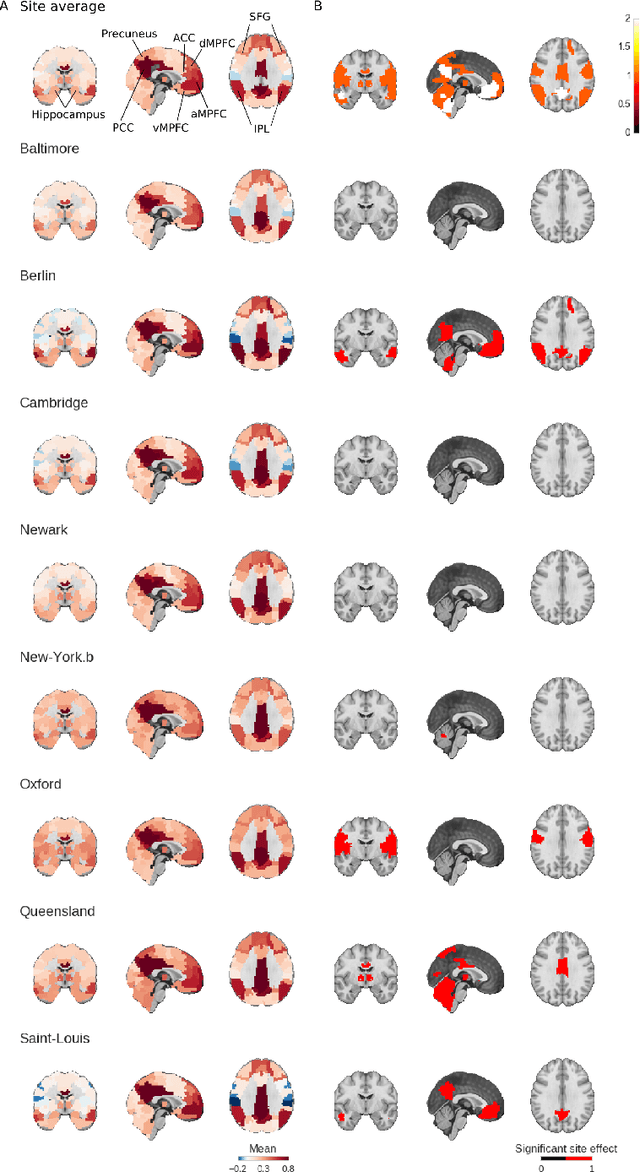
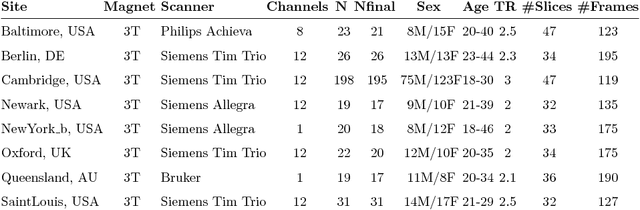
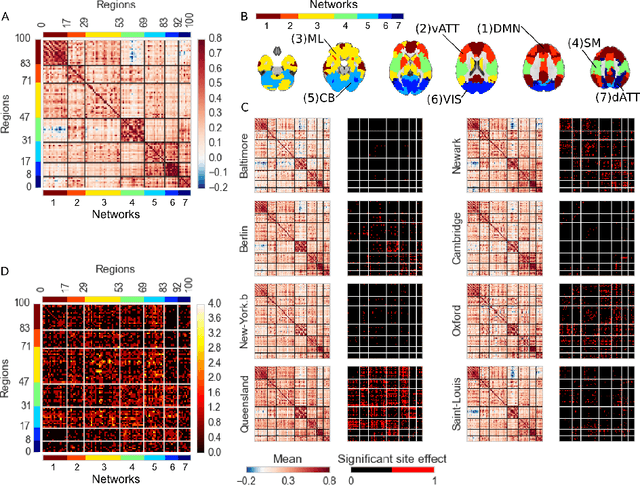
Connectivity studies using resting-state functional magnetic resonance imaging are increasingly pooling data acquired at multiple sites. While this may allow investigators to speed up recruitment or increase sample size, multisite studies also potentially introduce systematic biases in connectivity measures across sites. In this work, we measure the inter-site effect in connectivity and its impact on our ability to detect individual and group differences. Our study was based on real, as opposed to simulated, multisite fMRI datasets collected in N=345 young, healthy subjects across 8 scanning sites with 3T scanners and heterogeneous scanning protocols, drawn from the 1000 functional connectome project. We first empirically show that typical functional networks were reliably found at the group level in all sites, and that the amplitude of the inter-site effects was small to moderate, with a Cohen's effect size below 0.5 on average across brain connections. We then implemented a series of Monte-Carlo simulations, based on real data, to evaluate the impact of the multisite effects on detection power in statistical tests comparing two groups (with and without the effect) using a general linear model, as well as on the prediction of group labels with a support-vector machine. As a reference, we also implemented the same simulations with fMRI data collected at a single site using an identical sample size. Simulations revealed that using data from heterogeneous sites only slightly decreased our ability to detect changes compared to a monosite study with the GLM, and had a greater impact on prediction accuracy. Taken together, our results support the feasibility of multisite studies in rs-fMRI provided the sample size is large enough.
A Bayesian alternative to mutual information for the hierarchical clustering of dependent random variables
Oct 19, 2015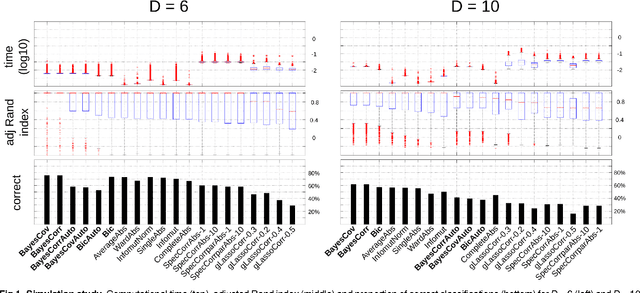
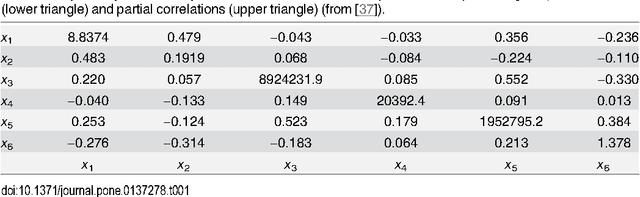
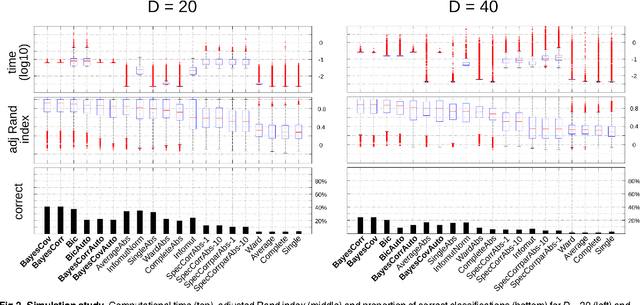

The use of mutual information as a similarity measure in agglomerative hierarchical clustering (AHC) raises an important issue: some correction needs to be applied for the dimensionality of variables. In this work, we formulate the decision of merging dependent multivariate normal variables in an AHC procedure as a Bayesian model comparison. We found that the Bayesian formulation naturally shrinks the empirical covariance matrix towards a matrix set a priori (e.g., the identity), provides an automated stopping rule, and corrects for dimensionality using a term that scales up the measure as a function of the dimensionality of the variables. Also, the resulting log Bayes factor is asymptotically proportional to the plug-in estimate of mutual information, with an additive correction for dimensionality in agreement with the Bayesian information criterion. We investigated the behavior of these Bayesian alternatives (in exact and asymptotic forms) to mutual information on simulated and real data. An encouraging result was first derived on simulations: the hierarchical clustering based on the log Bayes factor outperformed off-the-shelf clustering techniques as well as raw and normalized mutual information in terms of classification accuracy. On a toy example, we found that the Bayesian approaches led to results that were similar to those of mutual information clustering techniques, with the advantage of an automated thresholding. On real functional magnetic resonance imaging (fMRI) datasets measuring brain activity, it identified clusters consistent with the established outcome of standard procedures. On this application, normalized mutual information had a highly atypical behavior, in the sense that it systematically favored very large clusters. These initial experiments suggest that the proposed Bayesian alternatives to mutual information are a useful new tool for hierarchical clustering.