 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroevolution of Recurrent Architectures on Control Tasks
Paper and Code
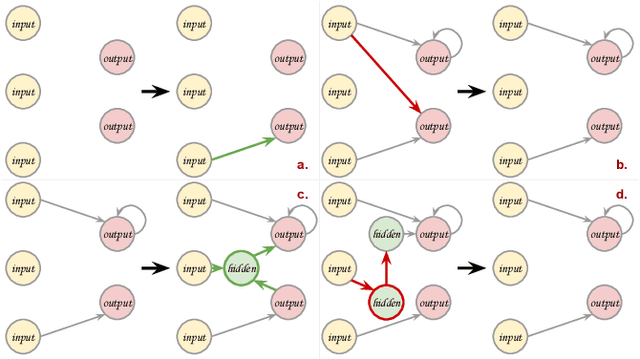
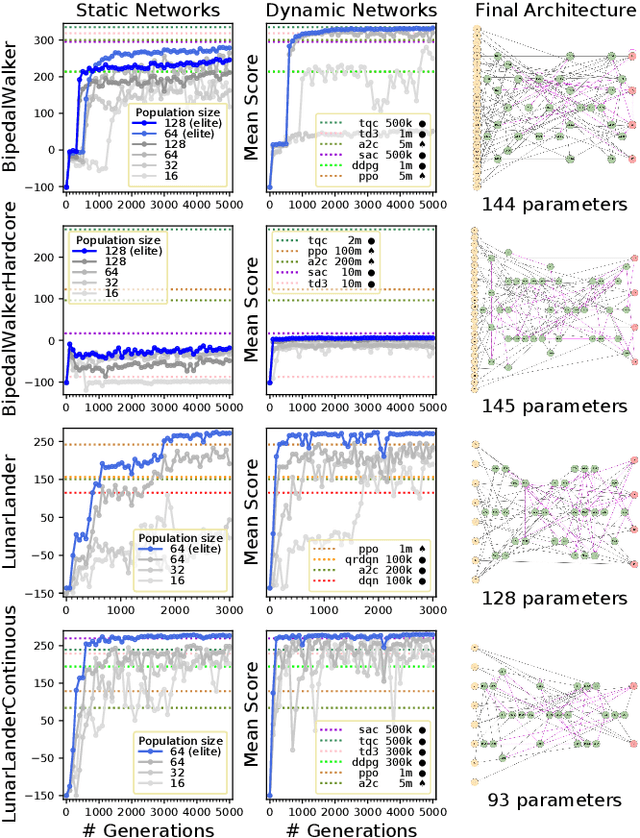
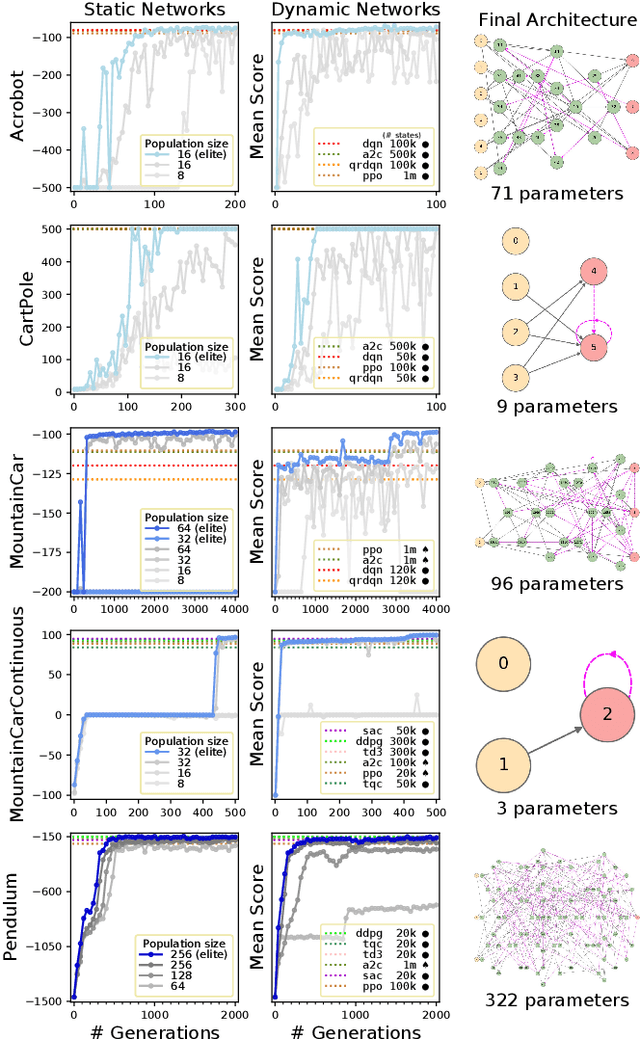
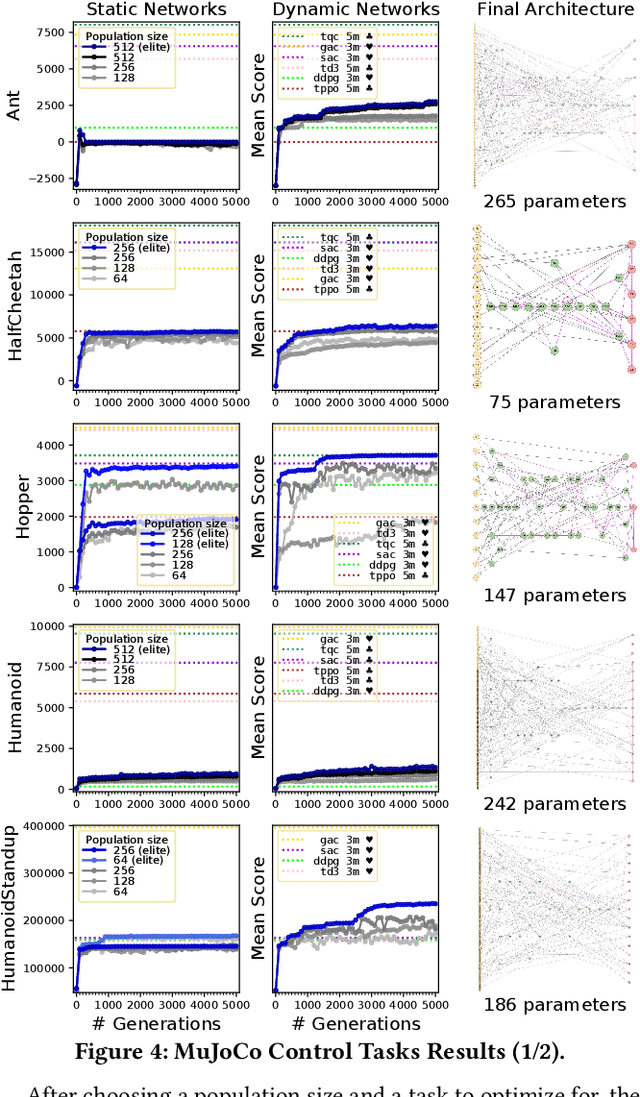
Modern artificial intelligence works typically train the parameters of fixed-sized deep neural networks using gradient-based optimization techniques. Simple evolutionary algorithms have recently been shown to also be capable of optimizing deep neural network parameters, at times matching the performance of gradient-based techniques, e.g. in reinforcement learning settings. In addition to optimizing network parameters, many evolutionary computation techniques are also capable of progressively constructing network architectures. However, constructing network architectures from elementary evolution rules has not yet been shown to scale to modern reinforcement learning benchmarks. In this paper we therefore propose a new approach in which the architectures of recurrent neural networks dynamically evolve according to a small set of mutation rules. We implement a massively parallel evolutionary algorithm and run experiments on all 19 OpenAI Gym state-based reinforcement learning control tasks. We find that in most cases, dynamic agents match or exceed the performance of gradient-based agents while utilizing orders of magnitude fewer parameters. We believe our work to open avenues for real-life applications where network compactness and autonomous design are of critical importance. We provide our source code, final model checkpoints and full results at github.com/MaximilienLC/nra.