 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
Discovering Optimal Scoring Mechanisms in Causal Strategic Prediction
Feb 21, 2023



Faced with data-driven policies, individuals will manipulate their features to obtain favorable decisions. While earlier works cast these manipulations as undesirable gaming, recent works have adopted a more nuanced causal framing in which manipulations can improve outcomes of interest, and setting coherent mechanisms requires accounting for both predictive accuracy and improvement of the outcome. Typically, these works focus on known causal graphs, consisting only of an outcome and its parents. In this paper, we introduce a general framework in which an outcome and n observed features are related by an arbitrary unknown graph and manipulations are restricted by a fixed budget and cost structure. We develop algorithms that leverage strategic responses to discover the causal graph in a finite number of steps. Given this graph structure, we can then derive mechanisms that trade off between accuracy and improvement. Altogether, our work deepens links between causal discovery and incentive design and provides a more nuanced view of learning under causal strategic prediction.
The Impact of Algorithmic Risk Assessments on Human Predictions and its Analysis via Crowdsourcing Studies
Sep 03, 2021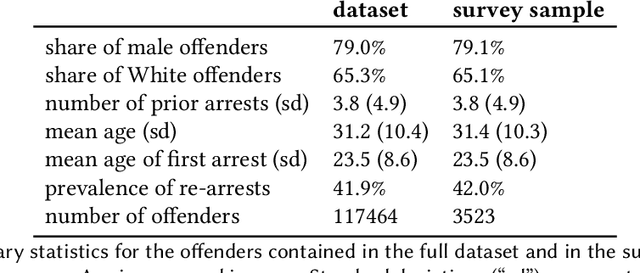

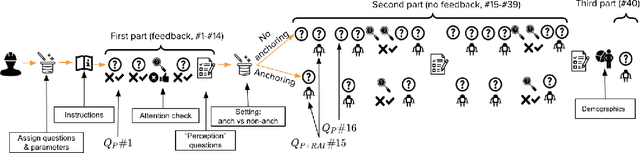
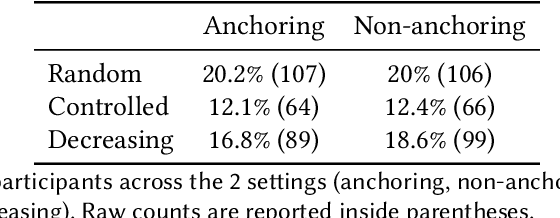
As algorithmic risk assessment instruments (RAIs) are increasingly adopted to assist decision makers, their predictive performance and potential to promote inequity have come under scrutiny. However, while most studies examine these tools in isolation, researchers have come to recognize that assessing their impact requires understanding the behavior of their human interactants. In this paper, building off of several recent crowdsourcing works focused on criminal justice, we conduct a vignette study in which laypersons are tasked with predicting future re-arrests. Our key findings are as follows: (1) Participants often predict that an offender will be rearrested even when they deem the likelihood of re-arrest to be well below 50%; (2) Participants do not anchor on the RAI's predictions; (3) The time spent on the survey varies widely across participants and most cases are assessed in less than 10 seconds; (4) Judicial decisions, unlike participants' predictions, depend in part on factors that are orthogonal to the likelihood of re-arrest. These results highlight the influence of several crucial but often overlooked design decisions and concerns around generalizability when constructing crowdsourcing studies to analyze the impacts of RAIs.
How Transferable are the Representations Learned by Deep Q Agents?
Feb 24, 2020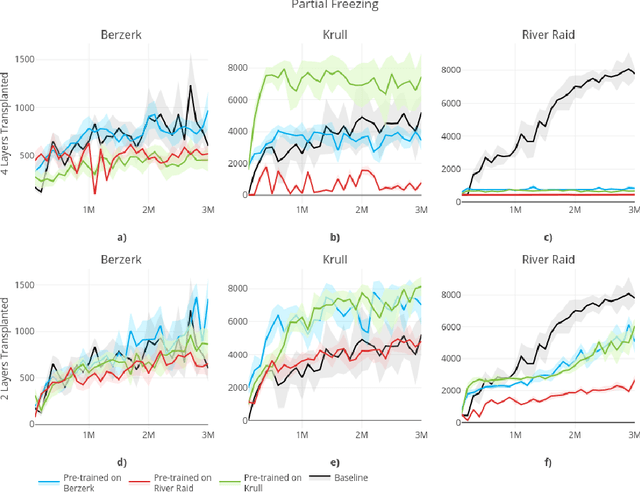
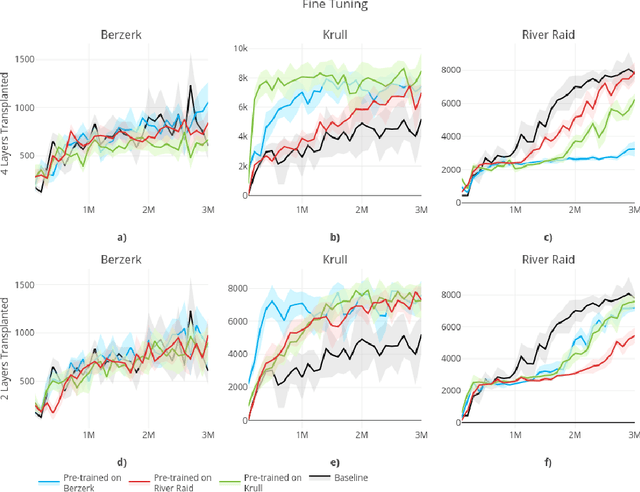
In this paper, we consider the source of Deep Reinforcement Learning (DRL)'s sample complexity, asking how much derives from the requirement of learning useful representations of environment states and how much is due to the sample complexity of learning a policy. While for DRL agents, the distinction between representation and policy may not be clear, we seek new insight through a set of transfer learning experiments. In each experiment, we retain some fraction of layers trained on either the same game or a related game, comparing the benefits of transfer learning to learning a policy from scratch. Interestingly, we find that benefits due to transfer are highly variable in general and non-symmetric across pairs of tasks. Our experiments suggest that perhaps transfer from simpler environments can boost performance on more complex downstream tasks and that the requirements of learning a useful representation can range from negligible to the majority of the sample complexity, based on the environment. Furthermore, we find that fine-tuning generally outperforms training with the transferred layers frozen, confirming an insight first noted in the classification setting.
Domain Adaptation with Asymmetrically-Relaxed Distribution Alignment
Mar 11, 2019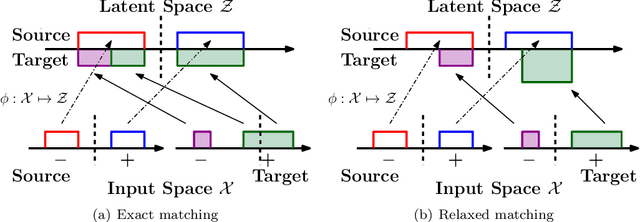
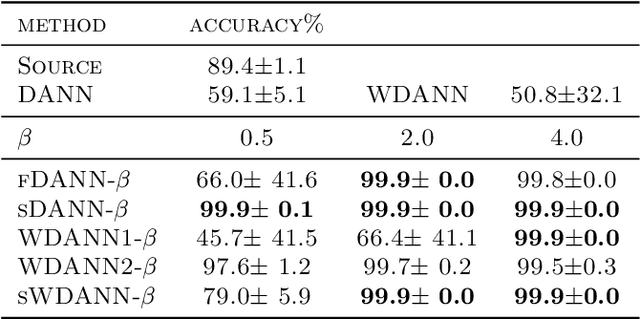
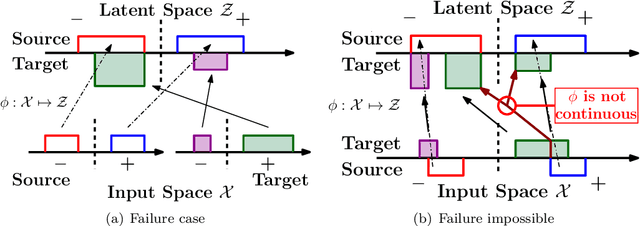
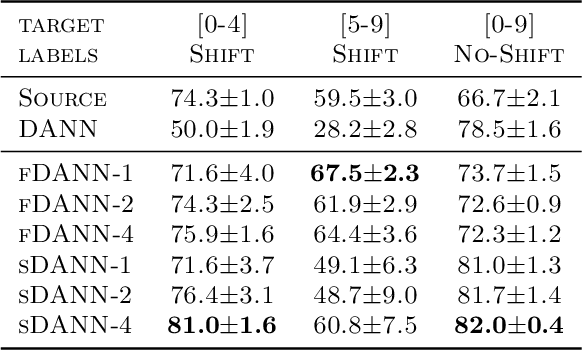
Domain adaptation addresses the common problem when the target distribution generating our test data drifts from the source (training) distribution. While absent assumptions, domain adaptation is impossible, strict conditions, e.g. covariate or label shift, enable principled algorithms. Recently-proposed domain-adversarial approaches consist of aligning source and target encodings, often motivating this approach as minimizing two (of three) terms in a theoretical bound on target error. Unfortunately, this minimization can cause arbitrary increases in the third term, e.g. they can break down under shifting label distributions. We propose asymmetrically-relaxed distribution alignment, a new approach that overcomes some limitations of standard domain-adversarial algorithms. Moreover, we characterize precise assumptions under which our algorithm is theoretically principled and demonstrate empirical benefits on both synthetic and real datasets.