 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Optimal Scoring Mechanisms in Causal Strategic Prediction
Feb 21, 2023



Faced with data-driven policies, individuals will manipulate their features to obtain favorable decisions. While earlier works cast these manipulations as undesirable gaming, recent works have adopted a more nuanced causal framing in which manipulations can improve outcomes of interest, and setting coherent mechanisms requires accounting for both predictive accuracy and improvement of the outcome. Typically, these works focus on known causal graphs, consisting only of an outcome and its parents. In this paper, we introduce a general framework in which an outcome and n observed features are related by an arbitrary unknown graph and manipulations are restricted by a fixed budget and cost structure. We develop algorithms that leverage strategic responses to discover the causal graph in a finite number of steps. Given this graph structure, we can then derive mechanisms that trade off between accuracy and improvement. Altogether, our work deepens links between causal discovery and incentive design and provides a more nuanced view of learning under causal strategic prediction.
Active Fairness Auditing
Jun 16, 2022

The fast spreading adoption of machine learning (ML) by companies across industries poses significant regulatory challenges. One such challenge is scalability: how can regulatory bodies efficiently audit these ML models, ensuring that they are fair? In this paper, we initiate the study of query-based auditing algorithms that can estimate the demographic parity of ML models in a query-efficient manner. We propose an optimal deterministic algorithm, as well as a practical randomized, oracle-efficient algorithm with comparable guarantees. Furthermore, we make inroads into understanding the optimal query complexity of randomized active fairness estimation algorithms. Our first exploration of active fairness estimation aims to put AI governance on firmer theoretical foundations.
Margin-distancing for safe model explanation
Feb 23, 2022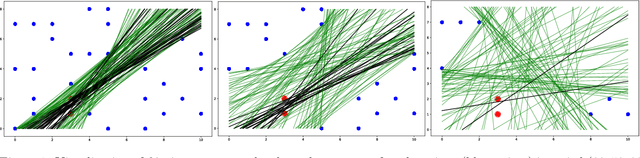
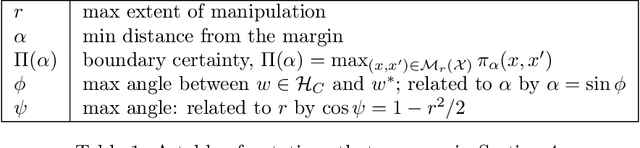

The growing use of machine learning models in consequential settings has highlighted an important and seemingly irreconcilable tension between transparency and vulnerability to gaming. While this has sparked sizable debate in legal literature, there has been comparatively less technical study of this contention. In this work, we propose a clean-cut formulation of this tension and a way to make the tradeoff between transparency and gaming. We identify the source of gaming as being points close to the \emph{decision boundary} of the model. And we initiate an investigation on how to provide example-based explanations that are expansive and yet consistent with a version space that is sufficiently uncertain with respect to the boundary points' labels. Finally, we furnish our theoretical results with empirical investigations of this tradeoff on real-world datasets.
Evaluating and Rewarding Teamwork Using Cooperative Game Abstractions
Jun 16, 2020

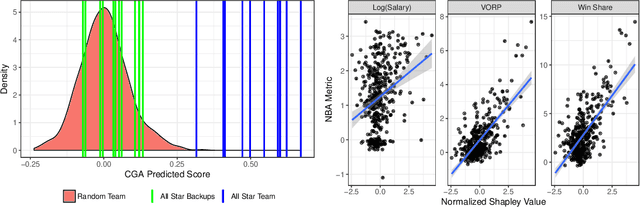

Can we predict how well a team of individuals will perform together? How should individuals be rewarded for their contributions to the team performance? Cooperative game theory gives us a powerful set of tools for answering these questions: the Characteristic Function (CF) and solution concepts like the Shapley Value (SV). There are two major difficulties in applying these techniques to real world problems: first, the CF is rarely given to us and needs to be learned from data. Second, the SV is combinatorial in nature. We introduce a parametric model called cooperative game abstractions (CGAs) for estimating CFs from data. CGAs are easy to learn, readily interpretable, and crucially allow linear-time computation of the SV. We provide identification results and sample complexity bounds for CGA models as well as error bounds in the estimation of the SV using CGAs. We apply our methods to study teams of artificial RL agents as well as real world teams from professional sports.
Moments in Time Dataset: one million videos for event understanding
Jan 09, 2018
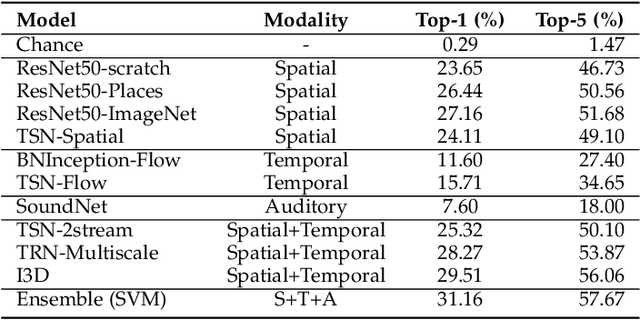

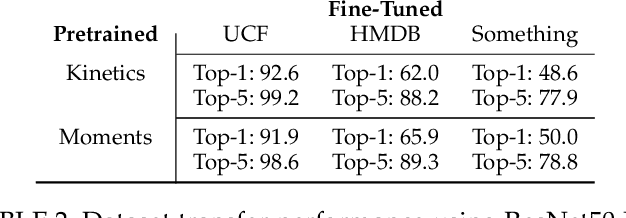
We present the Moments in Time Dataset, a large-scale human-annotated collection of one million short videos corresponding to dynamic events unfolding within three seconds. Modeling the spatial-audio-temporal dynamics even for actions occurring in 3 second videos poses many challenges: meaningful events do not include only people, but also objects, animals, and natural phenomena; visual and auditory events can be symmetrical or not in time ("opening" means "closing" in reverse order), and transient or sustained. We describe the annotation process of our dataset (each video is tagged with one action or activity label among 339 different classes), analyze its scale and diversity in comparison to other large-scale video datasets for action recognition, and report results of several baseline models addressing separately and jointly three modalities: spatial, temporal and auditory. The Moments in Time dataset designed to have a large coverage and diversity of events in both visual and auditory modalities, can serve as a new challenge to develop models that scale to the level of complexity and abstract reasoning that a human processes on a daily basis.