 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMargin-distancing for safe model explanation
Paper and Code
Feb 23, 2022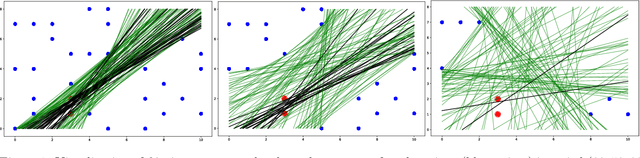

The growing use of machine learning models in consequential settings has highlighted an important and seemingly irreconcilable tension between transparency and vulnerability to gaming. While this has sparked sizable debate in legal literature, there has been comparatively less technical study of this contention. In this work, we propose a clean-cut formulation of this tension and a way to make the tradeoff between transparency and gaming. We identify the source of gaming as being points close to the \emph{decision boundary} of the model. And we initiate an investigation on how to provide example-based explanations that are expansive and yet consistent with a version space that is sufficiently uncertain with respect to the boundary points' labels. Finally, we furnish our theoretical results with empirical investigations of this tradeoff on real-world datasets.