 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Multiple Instance Learning for Weakly Supervised Person ReID
Feb 12, 2024



The acquisition of large-scale, precisely labeled datasets for person re-identification (ReID) poses a significant challenge. Weakly supervised ReID has begun to address this issue, although its performance lags behind fully supervised methods. In response, we introduce Contrastive Multiple Instance Learning (CMIL), a novel framework tailored for more effective weakly supervised ReID. CMIL distinguishes itself by requiring only a single model and no pseudo labels while leveraging contrastive losses -- a technique that has significantly enhanced traditional ReID performance yet is absent in all prior MIL-based approaches. Through extensive experiments and analysis across three datasets, CMIL not only matches state-of-the-art performance on the large-scale SYSU-30k dataset with fewer assumptions but also consistently outperforms all baselines on the WL-market1501 and Weakly Labeled MUddy racer re-iDentification dataset (WL-MUDD) datasets. We introduce and release the WL-MUDD dataset, an extension of the MUDD dataset featuring naturally occurring weak labels from the real-world application at PerformancePhoto.co. All our code and data are accessible at https://drive.google.com/file/d/1rjMbWB6m-apHF3Wg_cfqc8QqKgQ21AsT/view?usp=drive_link.
Beyond the Mud: Datasets and Benchmarks for Computer Vision in Off-Road Racing
Feb 12, 2024



Despite significant progress in optical character recognition (OCR) and computer vision systems, robustly recognizing text and identifying people in images taken in unconstrained \emph{in-the-wild} environments remain an ongoing challenge. However, such obstacles must be overcome in practical applications of vision systems, such as identifying racers in photos taken during off-road racing events. To this end, we introduce two new challenging real-world datasets - the off-road motorcycle Racer Number Dataset (RND) and the Muddy Racer re-iDentification Dataset (MUDD) - to highlight the shortcomings of current methods and drive advances in OCR and person re-identification (ReID) under extreme conditions. These two datasets feature over 6,300 images taken during off-road competitions which exhibit a variety of factors that undermine even modern vision systems, namely mud, complex poses, and motion blur. We establish benchmark performance on both datasets using state-of-the-art models. Off-the-shelf models transfer poorly, reaching only 15% end-to-end (E2E) F1 score on text spotting, and 33% rank-1 accuracy on ReID. Fine-tuning yields major improvements, bringing model performance to 53% F1 score for E2E text spotting and 79% rank-1 accuracy on ReID, but still falls short of good performance. Our analysis exposes open problems in real-world OCR and ReID that necessitate domain-targeted techniques. With these datasets and analysis of model limitations, we aim to foster innovations in handling real-world conditions like mud and complex poses to drive progress in robust computer vision. All data was sourced from PerformancePhoto.co, a website used by professional motorsports photographers, racers, and fans. The top-performing text spotting and ReID models are deployed on this platform to power real-time race photo search.
MUDD: A New Re-Identification Dataset with Efficient Annotation for Off-Road Racers in Extreme Conditions
Nov 14, 2023



Re-identifying individuals in unconstrained environments remains an open challenge in computer vision. We introduce the Muddy Racer re-IDentification Dataset (MUDD), the first large-scale benchmark for matching identities of motorcycle racers during off-road competitions. MUDD exhibits heavy mud occlusion, motion blurring, complex poses, and extreme lighting conditions previously unseen in existing re-id datasets. We present an annotation methodology incorporating auxiliary information that reduced labeling time by over 65%. We establish benchmark performance using state-of-the-art re-id models including OSNet and ResNet-50. Without fine-tuning, the best models achieve only 33% Rank-1 accuracy. Fine-tuning on MUDD boosts results to 79% Rank-1, but significant room for improvement remains. We analyze the impact of real-world factors including mud, pose, lighting, and more. Our work exposes open problems in re-identifying individuals under extreme conditions. We hope MUDD serves as a diverse and challenging benchmark to spur progress in robust re-id, especially for computer vision applications in emerging sports analytics. All code and data can be found at https://github.com/JacobTyo/MUDD.
Reading Between the Mud: A Challenging Motorcycle Racer Number Dataset
Nov 14, 2023
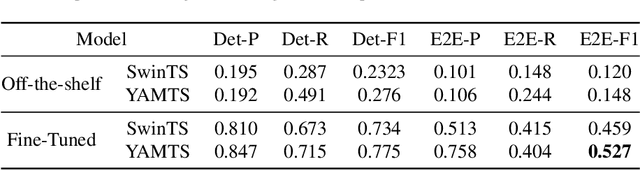

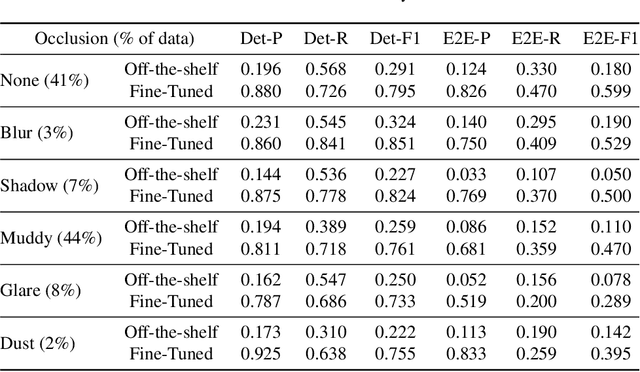
This paper introduces the off-road motorcycle Racer number Dataset (RnD), a new challenging dataset for optical character recognition (OCR) research. RnD contains 2,411 images from professional motorsports photographers that depict motorcycle racers in off-road competitions. The images exhibit a wide variety of factors that make OCR difficult, including mud occlusions, motion blur, non-standard fonts, glare, complex backgrounds, etc. The dataset has 5,578 manually annotated bounding boxes around visible motorcycle numbers, along with transcribed digits and letters. Our experiments benchmark leading OCR algorithms and reveal an end-to-end F1 score of only 0.527 on RnD, even after fine-tuning. Analysis of performance on different occlusion types shows mud as the primary challenge, degrading accuracy substantially compared to normal conditions. But the models struggle with other factors including glare, blur, shadows, and dust. Analysis exposes substantial room for improvement and highlights failure cases of existing models. RnD represents a valuable new benchmark to drive innovation in real-world OCR capabilities. The authors hope the community will build upon this dataset and baseline experiments to make progress on the open problem of robustly recognizing text in unconstrained natural environments. The dataset is available at https://github.com/JacobTyo/SwinTextSpotter.
Meta-Learning Mini-Batch Risk Functionals
Jan 27, 2023Supervised learning typically optimizes the expected value risk functional of the loss, but in many cases, we want to optimize for other risk functionals. In full-batch gradient descent, this is done by taking gradients of a risk functional of interest, such as the Conditional Value at Risk (CVaR) which ignores some quantile of extreme losses. However, deep learning must almost always use mini-batch gradient descent, and lack of unbiased estimators of various risk functionals make the right optimization procedure unclear. In this work, we introduce a meta-learning-based method of learning an interpretable mini-batch risk functional during model training, in a single shot. When optimizing for various risk functionals, the learned mini-batch risk functions lead to risk reduction of up to 10% over hand-engineered mini-batch risk functionals. Then in a setting where the right risk functional is unknown a priori, our method improves over baseline by 14% relative (~9% absolute). We analyze the learned mini-batch risk functionals at different points through training, and find that they learn a curriculum (including warm-up periods), and that their final form can be surprisingly different from the underlying risk functional that they optimize for.
On the State of the Art in Authorship Attribution and Authorship Verification
Sep 14, 2022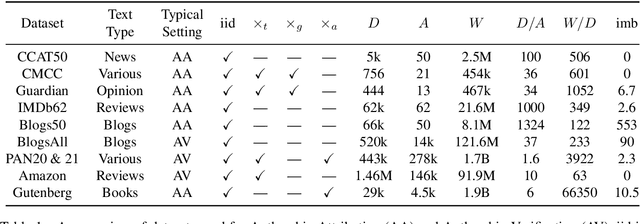


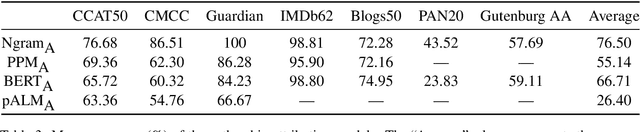
Despite decades of research on authorship attribution (AA) and authorship verification (AV), inconsistent dataset splits/filtering and mismatched evaluation methods make it difficult to assess the state of the art. In this paper, we present a survey of the fields, resolve points of confusion, introduce Valla that standardizes and benchmarks AA/AV datasets and metrics, provide a large-scale empirical evaluation, and provide apples-to-apples comparisons between existing methods. We evaluate eight promising methods on fifteen datasets (including distribution-shifted challenge sets) and introduce a new large-scale dataset based on texts archived by Project Gutenberg. Surprisingly, we find that a traditional Ngram-based model performs best on 5 (of 7) AA tasks, achieving an average macro-accuracy of $76.50\%$ (compared to $66.71\%$ for a BERT-based model). However, on the two AA datasets with the greatest number of words per author, as well as on the AV datasets, BERT-based models perform best. While AV methods are easily applied to AA, they are seldom included as baselines in AA papers. We show that through the application of hard-negative mining, AV methods are competitive alternatives to AA methods. Valla and all experiment code can be found here: https://github.com/JacobTyo/Valla
How Transferable are the Representations Learned by Deep Q Agents?
Feb 24, 2020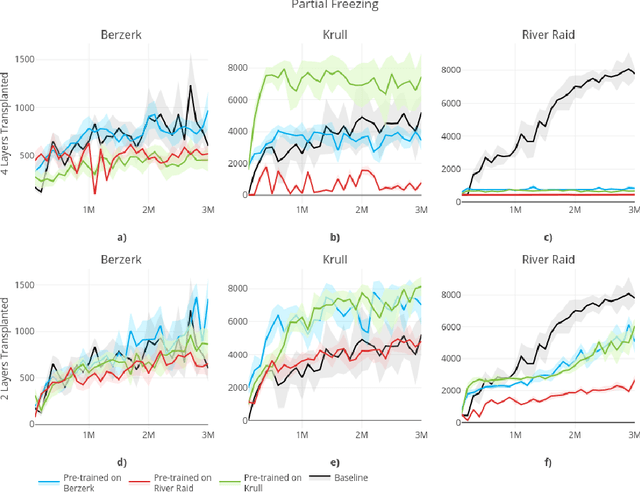
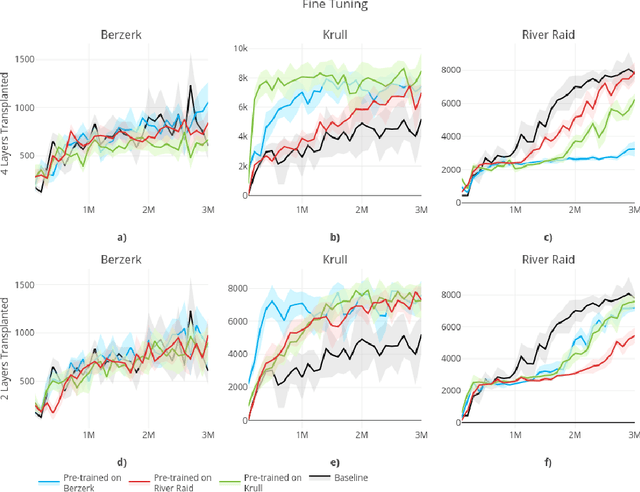
In this paper, we consider the source of Deep Reinforcement Learning (DRL)'s sample complexity, asking how much derives from the requirement of learning useful representations of environment states and how much is due to the sample complexity of learning a policy. While for DRL agents, the distinction between representation and policy may not be clear, we seek new insight through a set of transfer learning experiments. In each experiment, we retain some fraction of layers trained on either the same game or a related game, comparing the benefits of transfer learning to learning a policy from scratch. Interestingly, we find that benefits due to transfer are highly variable in general and non-symmetric across pairs of tasks. Our experiments suggest that perhaps transfer from simpler environments can boost performance on more complex downstream tasks and that the requirements of learning a useful representation can range from negligible to the majority of the sample complexity, based on the environment. Furthermore, we find that fine-tuning generally outperforms training with the transferred layers frozen, confirming an insight first noted in the classification setting.