 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Transferable are the Representations Learned by Deep Q Agents?
Paper and Code
Feb 24, 2020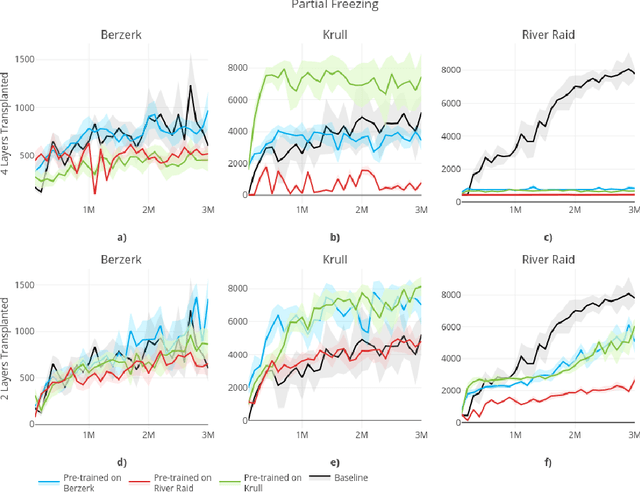
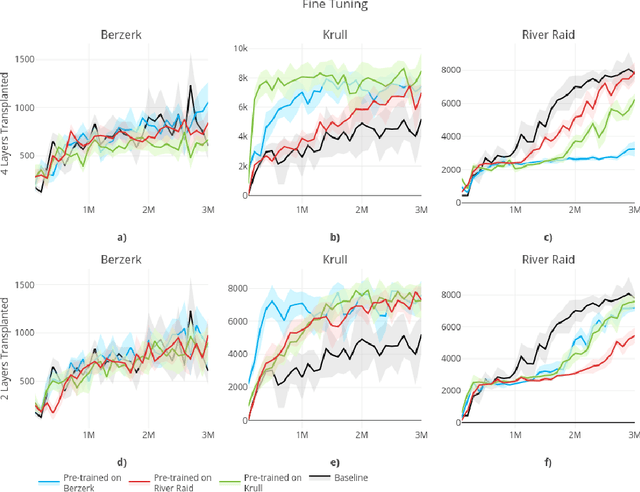
In this paper, we consider the source of Deep Reinforcement Learning (DRL)'s sample complexity, asking how much derives from the requirement of learning useful representations of environment states and how much is due to the sample complexity of learning a policy. While for DRL agents, the distinction between representation and policy may not be clear, we seek new insight through a set of transfer learning experiments. In each experiment, we retain some fraction of layers trained on either the same game or a related game, comparing the benefits of transfer learning to learning a policy from scratch. Interestingly, we find that benefits due to transfer are highly variable in general and non-symmetric across pairs of tasks. Our experiments suggest that perhaps transfer from simpler environments can boost performance on more complex downstream tasks and that the requirements of learning a useful representation can range from negligible to the majority of the sample complexity, based on the environment. Furthermore, we find that fine-tuning generally outperforms training with the transferred layers frozen, confirming an insight first noted in the classification setting.