 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Warning Index for Patient Deteriorations in Hospitals
Dec 16, 2025

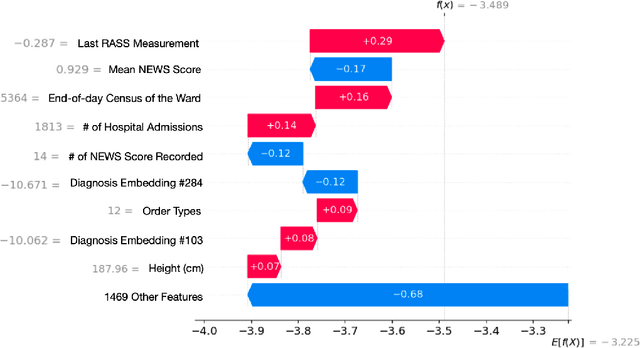

Hospitals lack automated systems to harness the growing volume of heterogeneous clinical and operational data to effectively forecast critical events. Early identification of patients at risk for deterioration is essential not only for patient care quality monitoring but also for physician care management. However, translating varied data streams into accurate and interpretable risk assessments poses significant challenges due to inconsistent data formats. We develop a multimodal machine learning framework, the Early Warning Index (EWI), to predict the aggregate risk of ICU admission, emergency response team dispatch, and mortality. Key to EWI's design is a human-in-the-loop process: clinicians help determine alert thresholds and interpret model outputs, which are enhanced by explainable outputs using Shapley Additive exPlanations (SHAP) to highlight clinical and operational factors (e.g., scheduled surgeries, ward census) driving each patient's risk. We deploy EWI in a hospital dashboard that stratifies patients into three risk tiers. Using a dataset of 18,633 unique patients at a large U.S. hospital, our approach automatically extracts features from both structured and unstructured electronic health record (EHR) data and achieves C-statistics of 0.796. It is currently used as a triage tool for proactively managing at-risk patients. The proposed approach saves physicians valuable time by automatically sorting patients of varying risk levels, allowing them to concentrate on patient care rather than sifting through complex EHR data. By further pinpointing specific risk drivers, the proposed model provides data-informed adjustments to caregiver scheduling and allocation of critical resources. As a result, clinicians and administrators can avert downstream complications, including costly procedures or high readmission rates and improve overall patient flow.
Prescribe-then-Select: Adaptive Policy Selection for Contextual Stochastic Optimization
Sep 09, 2025We address the problem of policy selection in contextual stochastic optimization (CSO), where covariates are available as contextual information and decisions must satisfy hard feasibility constraints. In many CSO settings, multiple candidate policies--arising from different modeling paradigms--exhibit heterogeneous performance across the covariate space, with no single policy uniformly dominating. We propose Prescribe-then-Select (PS), a modular framework that first constructs a library of feasible candidate policies and then learns a meta-policy to select the best policy for the observed covariates. We implement the meta-policy using ensembles of Optimal Policy Trees trained via cross-validation on the training set, making policy choice entirely data-driven. Across two benchmark CSO problems--single-stage newsvendor and two-stage shipment planning--PS consistently outperforms the best single policy in heterogeneous regimes of the covariate space and converges to the dominant policy when such heterogeneity is absent. All the code to reproduce the results can be found at https://anonymous.4open.science/r/Prescribe-then-Select-TMLR.
Patient Outcome Predictions Improve Operations at a Large Hospital Network
May 25, 2023



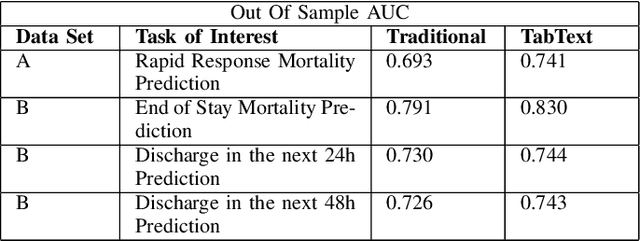
Problem definition: Access to accurate predictions of patients' outcomes can enhance medical staff's decision-making, which ultimately benefits all stakeholders in the hospitals. A large hospital network in the US has been collaborating with academics and consultants to predict short-term and long-term outcomes for all inpatients across their seven hospitals. Methodology/results: We develop machine learning models that predict the probabilities of next 24-hr/48-hr discharge and intensive care unit transfers, end-of-stay mortality and discharge dispositions. All models achieve high out-of-sample AUC (75.7%-92.5%) and are well calibrated. In addition, combining 48-hr discharge predictions with doctors' predictions simultaneously enables more patient discharges (10%-28.7%) and fewer 7-day/30-day readmissions ($p$-value $<0.001$). We implement an automated pipeline that extracts data and updates predictions every morning, as well as user-friendly software and a color-coded alert system to communicate these patient-level predictions (alongside explanations) to clinical teams. Managerial implications: Since we have been gradually deploying the tool, and training medical staff, over 200 doctors, nurses, and case managers across seven hospitals use it in their daily patient review process. We observe a significant reduction in the average length of stay (0.67 days per patient) following its adoption and anticipate substantial financial benefits (between \$55 and \$72 million annually) for the healthcare system.
Multistage Stochastic Optimization via Kernels
Mar 11, 2023We develop a non-parametric, data-driven, tractable approach for solving multistage stochastic optimization problems in which decisions do not affect the uncertainty. The proposed framework represents the decision variables as elements of a reproducing kernel Hilbert space and performs functional stochastic gradient descent to minimize the empirical regularized loss. By incorporating sparsification techniques based on function subspace projections we are able to overcome the computational complexity that standard kernel methods introduce as the data size increases. We prove that the proposed approach is asymptotically optimal for multistage stochastic optimization with side information. Across various computational experiments on stochastic inventory management problems, {our method performs well in multidimensional settings} and remains tractable when the data size is large. Lastly, by computing lower bounds for the optimal loss of the inventory control problem, we show that the proposed method produces decision rules with near-optimal average performance.
TabText: a Systematic Approach to Aggregate Knowledge Across Tabular Data Structures
Jun 21, 2022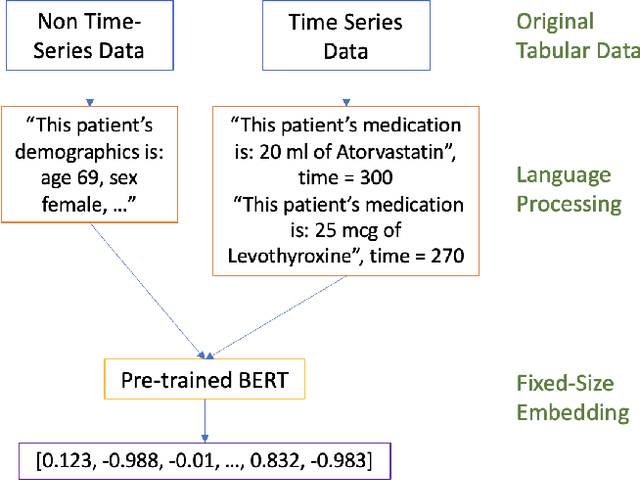
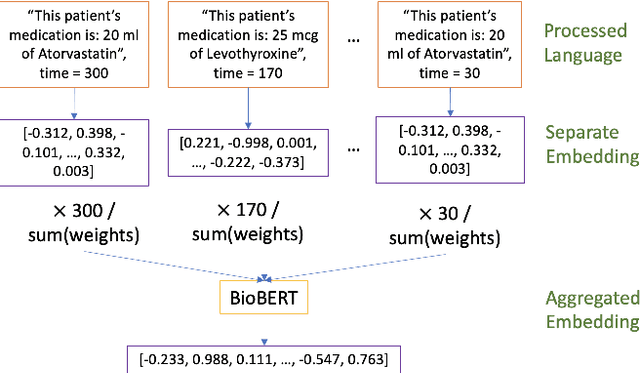
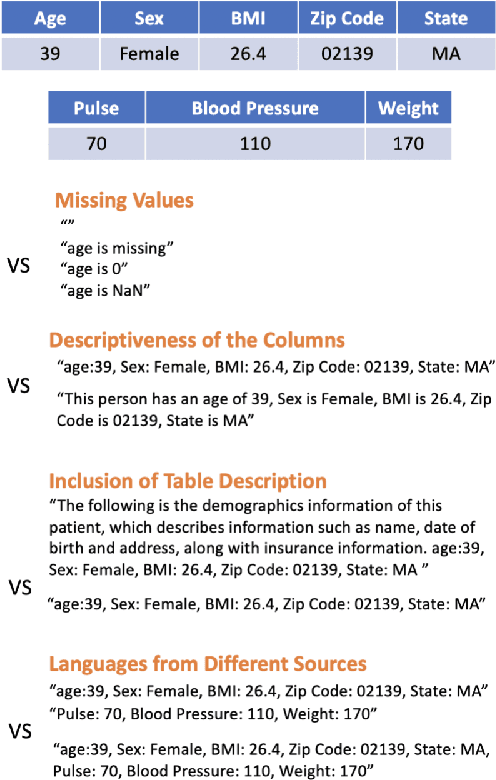
Processing and analyzing tabular data in a productive and efficient way is essential for building successful applications of machine learning in fields such as healthcare. However, the lack of a unified framework for representing and standardizing tabular information poses a significant challenge to researchers and professionals alike. In this work, we present TabText, a methodology that leverages the unstructured data format of language to encode tabular data from different table structures and time periods efficiently and accurately. We show using two healthcare datasets and four prediction tasks that features extracted via TabText outperform those extracted with traditional processing methods by 2-5%. Furthermore, we analyze the sensitivity of our framework against different choices for sentence representations of missing values, meta information and language descriptiveness, and provide insights into winning strategies that improve performance.
Integrated multimodal artificial intelligence framework for healthcare applications
Feb 25, 2022
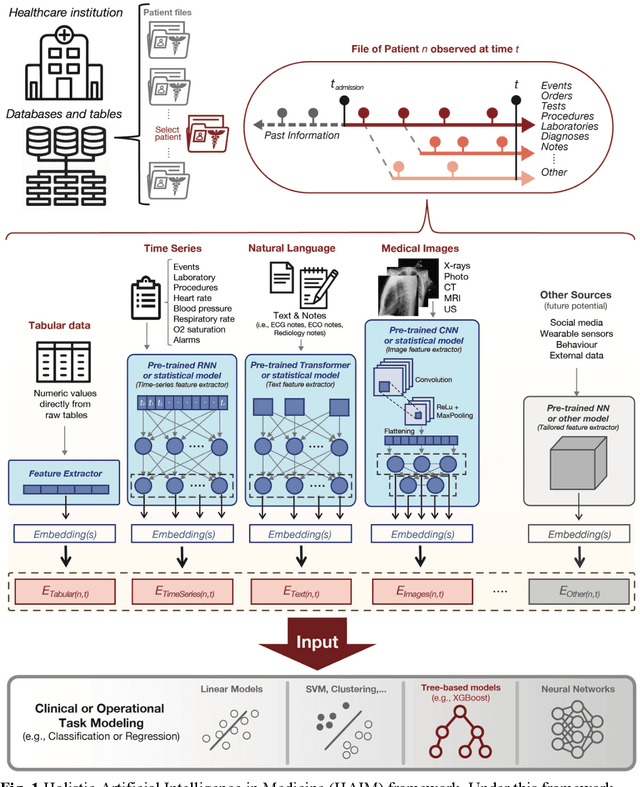
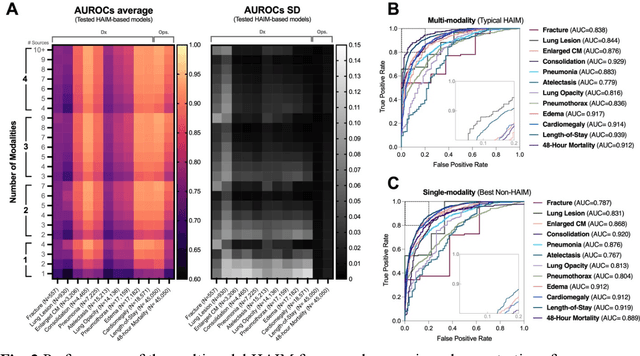
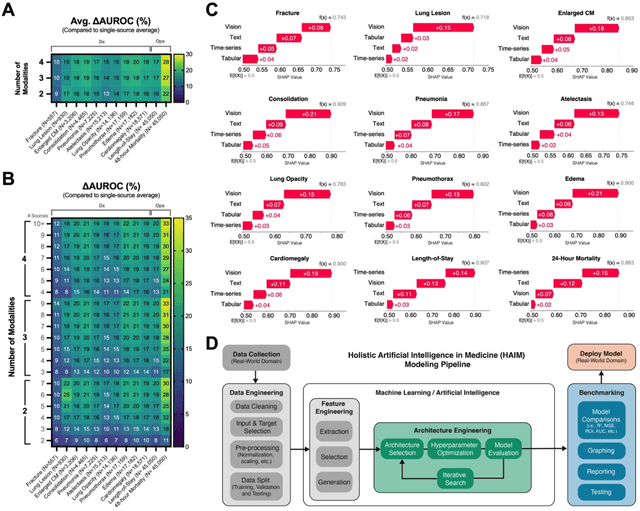
Artificial intelligence (AI) systems hold great promise to improve healthcare over the next decades. Specifically, AI systems leveraging multiple data sources and input modalities are poised to become a viable method to deliver more accurate results and deployable pipelines across a wide range of applications. In this work, we propose and evaluate a unified Holistic AI in Medicine (HAIM) framework to facilitate the generation and testing of AI systems that leverage multimodal inputs. Our approach uses generalizable data pre-processing and machine learning modeling stages that can be readily adapted for research and deployment in healthcare environments. We evaluate our HAIM framework by training and characterizing 14,324 independent models based on MIMIC-IV-MM, a multimodal clinical database (N=34,537 samples) containing 7,279 unique hospitalizations and 6,485 patients, spanning all possible input combinations of 4 data modalities (i.e., tabular, time-series, text and images), 11 unique data sources and 12 predictive tasks. We show that this framework can consistently and robustly produce models that outperform similar single-source approaches across various healthcare demonstrations (by 6-33%), including 10 distinct chest pathology diagnoses, along with length-of-stay and 48-hour mortality predictions. We also quantify the contribution of each modality and data source using Shapley values, which demonstrates the heterogeneity in data type importance and the necessity of multimodal inputs across different healthcare-relevant tasks. The generalizable properties and flexibility of our Holistic AI in Medicine (HAIM) framework could offer a promising pathway for future multimodal predictive systems in clinical and operational healthcare settings.
A Robust Optimization Approach to Deep Learning
Dec 17, 2021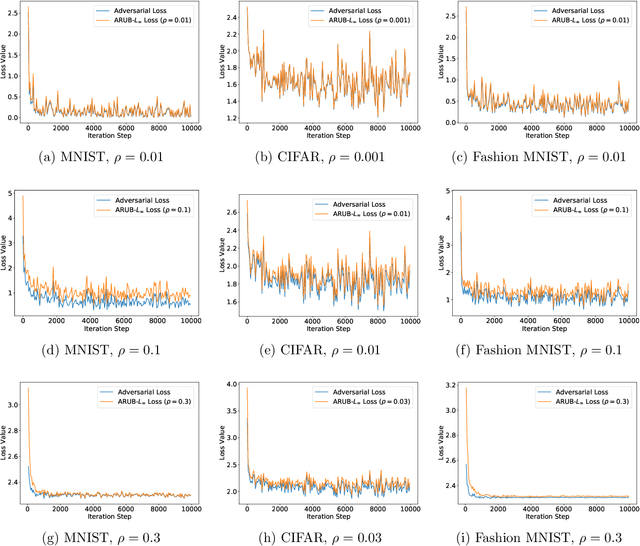

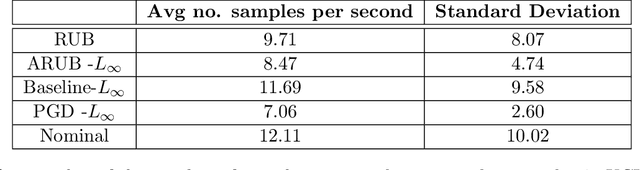
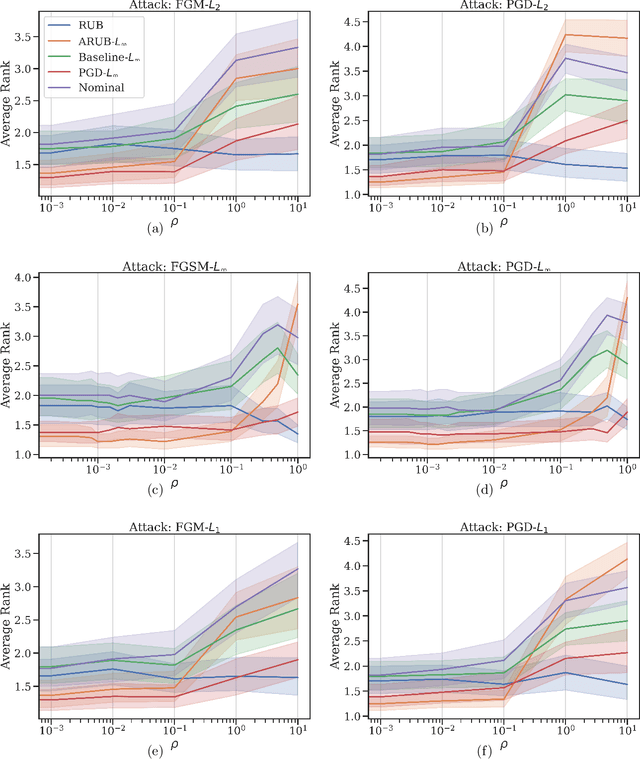
Many state-of-the-art adversarial training methods leverage upper bounds of the adversarial loss to provide security guarantees. Yet, these methods require computations at each training step that can not be incorporated in the gradient for backpropagation. We introduce a new, more principled approach to adversarial training based on a closed form solution of an upper bound of the adversarial loss, which can be effectively trained with backpropagation. This bound is facilitated by state-of-the-art tools from robust optimization. We derive two new methods with our approach. The first method (Approximated Robust Upper Bound or aRUB) uses the first order approximation of the network as well as basic tools from linear robust optimization to obtain an approximate upper bound of the adversarial loss that can be easily implemented. The second method (Robust Upper Bound or RUB), computes an exact upper bound of the adversarial loss. Across a variety of tabular and vision data sets we demonstrate the effectiveness of our more principled approach -- RUB is substantially more robust than state-of-the-art methods for larger perturbations, while aRUB matches the performance of state-of-the-art methods for small perturbations. Also, both RUB and aRUB run faster than standard adversarial training (at the expense of an increase in memory). All the code to reproduce the results can be found at https://github.com/kimvc7/Robustness.
Holistic Deep Learning
Oct 29, 2021
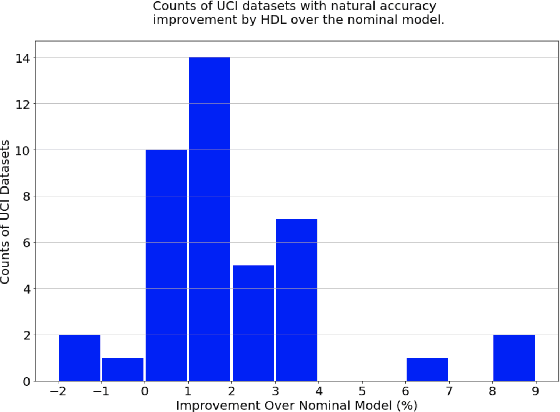
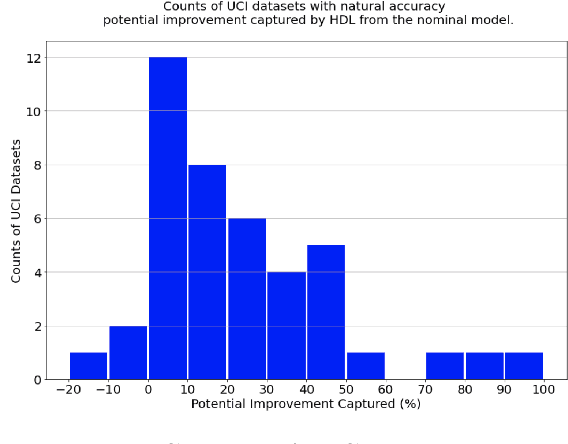

There is much interest in deep learning to solve challenges that arise in applying neural network models in real-world environments. In particular, three areas have received considerable attention: adversarial robustness, parameter sparsity, and output stability. Despite numerous attempts on solving these problems independently, there is very little work addressing the challenges simultaneously. In this paper, we address this problem of constructing holistic deep learning models by proposing a novel formulation that solves these issues in combination. Real-world experiments on both tabular and MNIST dataset show that our formulation is able to simultaneously improve the accuracy, robustness, stability, and sparsity over traditional deep learning models among many others.
From predictions to prescriptions: A data-driven response to COVID-19
Jun 30, 2020The COVID-19 pandemic has created unprecedented challenges worldwide. Strained healthcare providers make difficult decisions on patient triage, treatment and care management on a daily basis. Policy makers have imposed social distancing measures to slow the disease, at a steep economic price. We design analytical tools to support these decisions and combat the pandemic. Specifically, we propose a comprehensive data-driven approach to understand the clinical characteristics of COVID-19, predict its mortality, forecast its evolution, and ultimately alleviate its impact. By leveraging cohort-level clinical data, patient-level hospital data, and census-level epidemiological data, we develop an integrated four-step approach, combining descriptive, predictive and prescriptive analytics. First, we aggregate hundreds of clinical studies into the most comprehensive database on COVID-19 to paint a new macroscopic picture of the disease. Second, we build personalized calculators to predict the risk of infection and mortality as a function of demographics, symptoms, comorbidities, and lab values. Third, we develop a novel epidemiological model to project the pandemic's spread and inform social distancing policies. Fourth, we propose an optimization model to re-allocate ventilators and alleviate shortages. Our results have been used at the clinical level by several hospitals to triage patients, guide care management, plan ICU capacity, and re-distribute ventilators. At the policy level, they are currently supporting safe back-to-work policies at a major institution and equitable vaccine distribution planning at a major pharmaceutical company, and have been integrated into the US Center for Disease Control's pandemic forecast.