 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference for Heterogeneous Treatment Effects Discovered by Generic Machine Learning in Randomized Experiments
Paper and Code
Mar 28, 2022
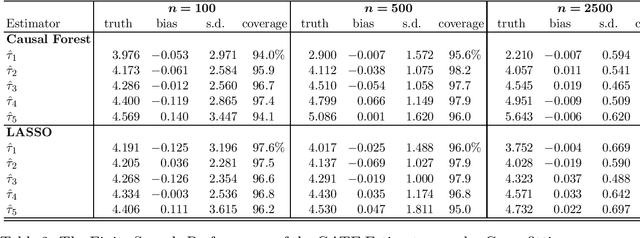

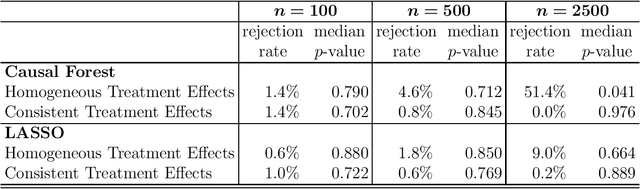
Researchers are increasingly turning to machine learning (ML) algorithms to investigate causal heterogeneity in randomized experiments. Despite their promise, ML algorithms may fail to accurately ascertain heterogeneous treatment effects under practical settings with many covariates and small sample size. In addition, the quantification of estimation uncertainty remains a challenge. We develop a general approach to statistical inference for heterogeneous treatment effects discovered by a generic ML algorithm. We apply the Neyman's repeated sampling framework to a common setting, in which researchers use an ML algorithm to estimate the conditional average treatment effect and then divide the sample into several groups based on the magnitude of the estimated effects. We show how to estimate the average treatment effect within each of these groups, and construct a valid confidence interval. In addition, we develop nonparametric tests of treatment effect homogeneity across groups, and rank-consistency of within-group average treatment effects. The validity of our methodology does not rely on the properties of ML algorithms because it is solely based on the randomization of treatment assignment and random sampling of units. Finally, we generalize our methodology to the cross-fitting procedure by accounting for the additional uncertainty induced by the random splitting of data.