 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Apr 08, 2025Recent advancements in large language models (LLMs) have revolutionized their ability to handle single-turn tasks, yet real-world applications demand sophisticated multi-turn interactions. This survey provides a comprehensive review of recent advancements in evaluating and enhancing multi-turn interactions in LLMs. Focusing on task-specific scenarios, from instruction following in diverse domains such as math and coding to complex conversational engagements in roleplay, healthcare, education, and even adversarial jailbreak settings, we systematically examine the challenges of maintaining context, coherence, fairness, and responsiveness over prolonged dialogues. The paper organizes current benchmarks and datasets into coherent categories that reflect the evolving landscape of multi-turn dialogue evaluation. In addition, we review a range of enhancement methodologies under multi-turn settings, including model-centric strategies (contextual learning, supervised fine-tuning, reinforcement learning, and new architectures), external integration approaches (memory-augmented, retrieval-based methods, and knowledge graph), and agent-based techniques for collaborative interactions. Finally, we discuss open challenges and propose future directions for research to further advance the robustness and effectiveness of multi-turn interactions in LLMs. Related resources and papers are available at https://github.com/yubol-cmu/Awesome-Multi-Turn-LLMs.
Firm or Fickle? Evaluating Large Language Models Consistency in Sequential Interactions
Mar 28, 2025


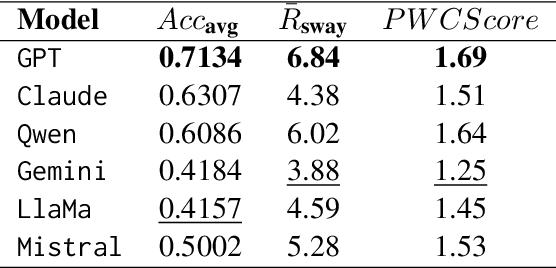
Large Language Models (LLMs) have shown remarkable capabilities across various tasks, but their deployment in high-stake domains requires consistent performance across multiple interaction rounds. This paper introduces a comprehensive framework for evaluating and improving LLM response consistency, making three key contributions. First, we propose a novel Position-Weighted Consistency (PWC) score that captures both the importance of early-stage stability and recovery patterns in multi-turn interactions. Second, we present a carefully curated benchmark dataset spanning diverse domains and difficulty levels, specifically designed to evaluate LLM consistency under various challenging follow-up scenarios. Third, we introduce Confidence-Aware Response Generation (CARG), a framework that significantly improves response stability by incorporating model confidence signals into the generation process. Empirical results demonstrate that CARG significantly improves response stability without sacrificing accuracy, underscoring its potential for reliable LLM deployment in critical applications.