 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Threat Reports to Continuous Threat Intelligence: A Comparison of Attack Technique Extraction Methods from Textual Artifacts
Paper and Code
Oct 05, 2022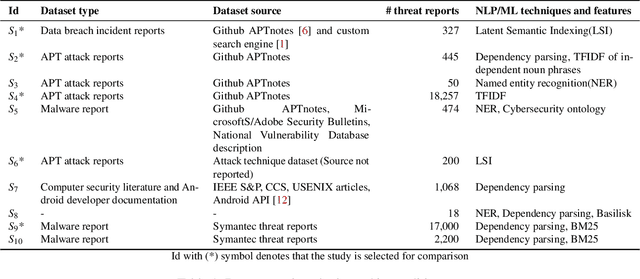
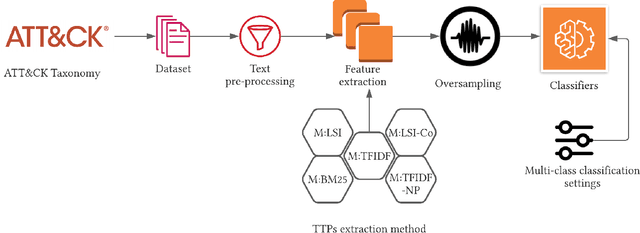
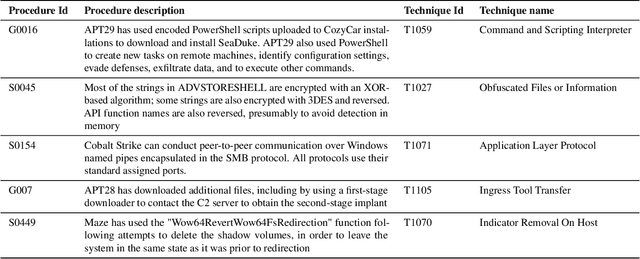
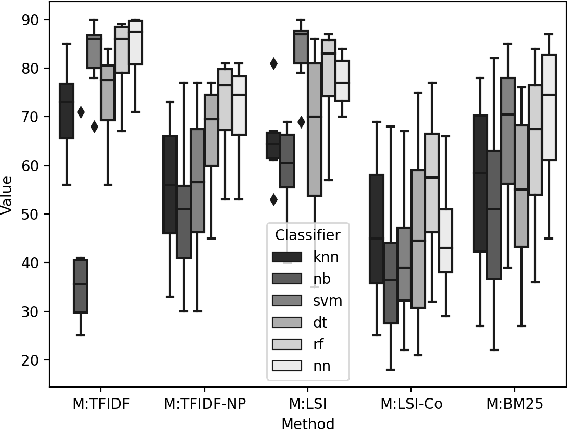
The cyberthreat landscape is continuously evolving. Hence, continuous monitoring and sharing of threat intelligence have become a priority for organizations. Threat reports, published by cybersecurity vendors, contain detailed descriptions of attack Tactics, Techniques, and Procedures (TTP) written in an unstructured text format. Extracting TTP from these reports aids cybersecurity practitioners and researchers learn and adapt to evolving attacks and in planning threat mitigation. Researchers have proposed TTP extraction methods in the literature, however, not all of these proposed methods are compared to one another or to a baseline. \textit{The goal of this study is to aid cybersecurity researchers and practitioners choose attack technique extraction methods for monitoring and sharing threat intelligence by comparing the underlying methods from the TTP extraction studies in the literature.} In this work, we identify ten existing TTP extraction studies from the literature and implement five methods from the ten studies. We find two methods, based on Term Frequency-Inverse Document Frequency(TFIDF) and Latent Semantic Indexing (LSI), outperform the other three methods with a F1 score of 84\% and 83\%, respectively. We observe the performance of all methods in F1 score drops in the case of increasing the class labels exponentially. We also implement and evaluate an oversampling strategy to mitigate class imbalance issues. Furthermore, oversampling improves the classification performance of TTP extraction. We provide recommendations from our findings for future cybersecurity researchers, such as the construction of a benchmark dataset from a large corpus; and the selection of textual features of TTP. Our work, along with the dataset and implementation source code, can work as a baseline for cybersecurity researchers to test and compare the performance of future TTP extraction methods.