 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Cache Model for Few-Shot Vision-Language Model Adaptation
Oct 11, 2024
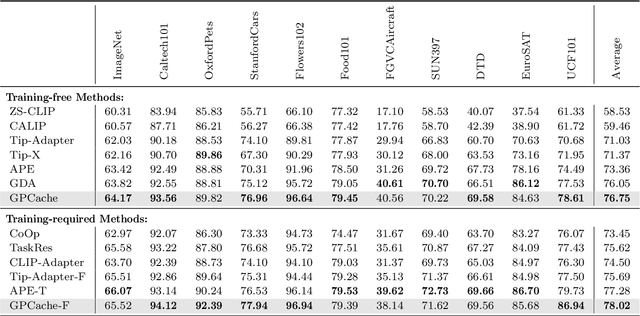
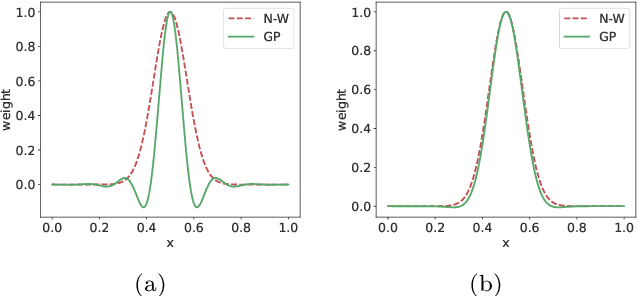
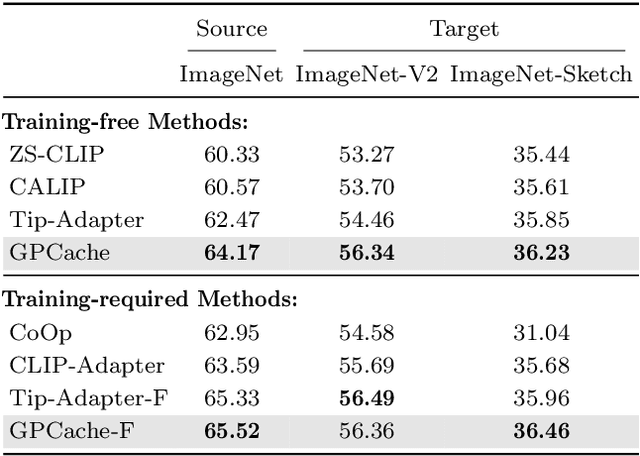
Cache-based approaches stand out as both effective and efficient for adapting vision-language models (VLMs). Nonetheless, the existing cache model overlooks three crucial aspects. 1) Pre-trained VLMs are mainly optimized for image-text similarity, neglecting the importance of image-image similarity, leading to a gap between pre-training and adaptation. 2) The current cache model is based on the Nadaraya-Watson (N-W) estimator, which disregards the intricate relationships among training samples while constructing weight function. 3) Under the condition of limited samples, the logits generated by cache model are of high uncertainty, directly using these logits without accounting for the confidence could be problematic. This work presents three calibration modules aimed at addressing the above challenges. Similarity Calibration refines the image-image similarity by using unlabeled images. We add a learnable projection layer with residual connection on top of the pre-trained image encoder of CLIP and optimize the parameters by minimizing self-supervised contrastive loss. Weight Calibration introduces a precision matrix into the weight function to adequately model the relation between training samples, transforming the existing cache model to a Gaussian Process (GP) regressor, which could be more accurate than N-W estimator. Confidence Calibration leverages the predictive variances computed by GP Regression to dynamically re-scale the logits of cache model, ensuring that the cache model's outputs are appropriately adjusted based on their confidence levels. Besides, to reduce the high complexity of GPs, we further propose a group-based learning strategy. Integrating the above designs, we propose both training-free and training-required variants. Extensive experiments on 11 few-shot classification datasets validate that the proposed methods can achieve state-of-the-art performance.
Weak Distribution Detectors Lead to Stronger Generalizability of Vision-Language Prompt Tuning
Mar 31, 2024We propose a generalized method for boosting the generalization ability of pre-trained vision-language models (VLMs) while fine-tuning on downstream few-shot tasks. The idea is realized by exploiting out-of-distribution (OOD) detection to predict whether a sample belongs to a base distribution or a novel distribution and then using the score generated by a dedicated competition based scoring function to fuse the zero-shot and few-shot classifier. The fused classifier is dynamic, which will bias towards the zero-shot classifier if a sample is more likely from the distribution pre-trained on, leading to improved base-to-novel generalization ability. Our method is performed only in test stage, which is applicable to boost existing methods without time-consuming re-training. Extensive experiments show that even weak distribution detectors can still improve VLMs' generalization ability. Specifically, with the help of OOD detectors, the harmonic mean of CoOp and ProGrad increase by 2.6 and 1.5 percentage points over 11 recognition datasets in the base-to-novel setting.
Compositional Kronecker Context Optimization for Vision-Language Models
Mar 18, 2024Context Optimization (CoOp) has emerged as a simple yet effective technique for adapting CLIP-like vision-language models to downstream image recognition tasks. Nevertheless, learning compact context with satisfactory base-to-new, domain and cross-task generalization ability while adapting to new tasks is still a challenge. To tackle such a challenge, we propose a lightweight yet generalizable approach termed Compositional Kronecker Context Optimization (CK-CoOp). Technically, the prompt's context words in CK-CoOp are learnable vectors, which are crafted by linearly combining base vectors sourced from a dictionary. These base vectors consist of a non-learnable component obtained by quantizing the weights in the token embedding layer, and a learnable component constructed by applying Kronecker product on several learnable tiny matrices. Intuitively, the compositional structure mitigates the risk of overfitting on training data by remembering more pre-trained knowledge. Meantime, the Kronecker product breaks the non-learnable restrictions of the dictionary, thereby enhancing representation ability with minimal additional parameters. Extensive experiments confirm that CK-CoOp achieves state-of-the-art performance under base-to-new, domain and cross-task generalization evaluation, but also has the metrics of fewer learnable parameters and efficient training and inference speed.
Zero-shot Generalizable Incremental Learning for Vision-Language Object Detection
Mar 04, 2024
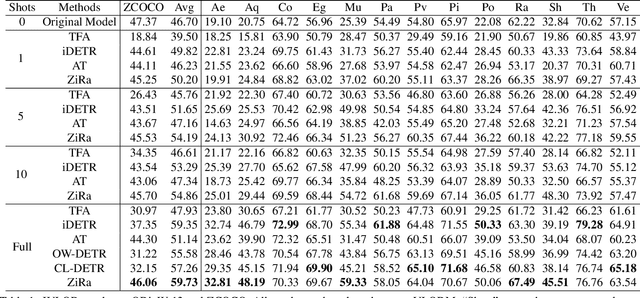
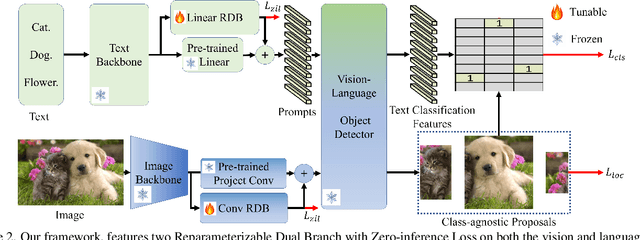

This paper presents Incremental Vision-Language Object Detection (IVLOD), a novel learning task designed to incrementally adapt pre-trained Vision-Language Object Detection Models (VLODMs) to various specialized domains, while simultaneously preserving their zero-shot generalization capabilities for the generalized domain. To address this new challenge, we present the Zero-interference Reparameterizable Adaptation (ZiRa), a novel method that introduces Zero-interference Loss and reparameterization techniques to tackle IVLOD without incurring additional inference costs or a significant increase in memory usage. Comprehensive experiments on COCO and ODinW-13 datasets demonstrate that ZiRa effectively safeguards the zero-shot generalization ability of VLODMs while continuously adapting to new tasks. Specifically, after training on ODinW-13 datasets, ZiRa exhibits superior performance compared to CL-DETR and iDETR, boosting zero-shot generalizability by substantial 13.91 and 8.71 AP, respectively.
Prompt Tuning with Soft Context Sharing for Vision-Language Models
Aug 29, 2022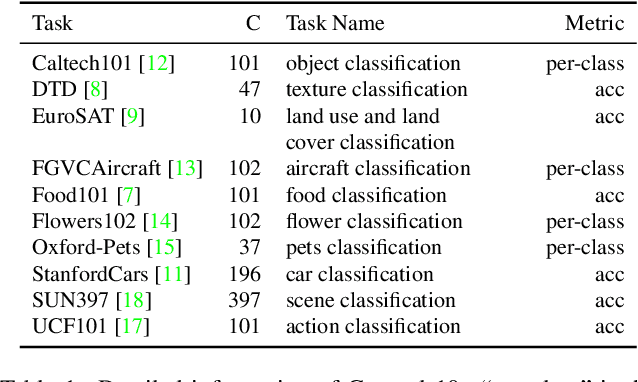

Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.
Incremental Prototype Prompt-tuning with Pre-trained Representation for Class Incremental Learning
Apr 11, 2022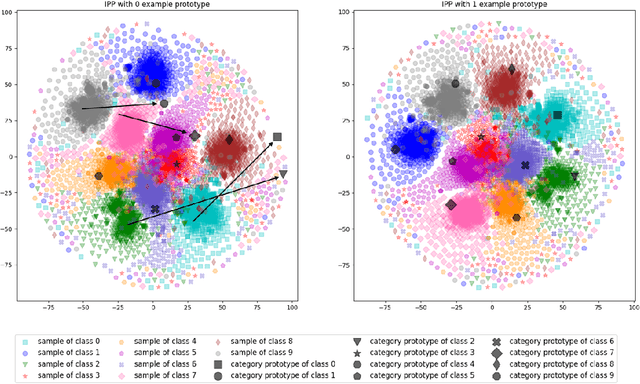
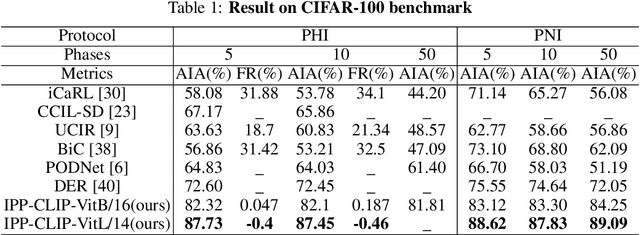
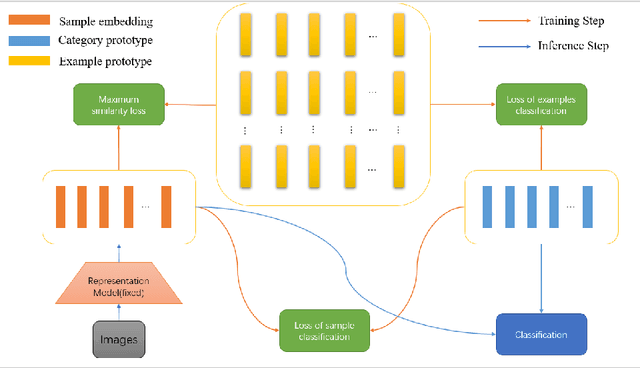
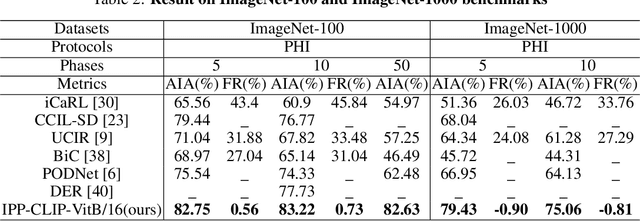
Class incremental learning has attracted much attention, but most existing works still continually fine-tune the representation model, resulting in much catastrophic forgetting. Instead of struggling to fight against such forgetting by replaying or distillation like most of the existing methods, we take the pre-train-and-prompt-tuning paradigm to sequentially learn new visual concepts based on a fixed semantic rich pre-trained representation model by incremental prototype prompt-tuning (IPP), which substantially reduces the catastrophic forgetting. In addition, an example prototype classification is proposed to compensate for semantic drift, the problem caused by learning bias at different phases. Extensive experiments conducted on the three incremental learning benchmarks demonstrate that our method consistently outperforms other state-of-the-art methods with a large margin.
Semi-supervised Models are Strong Unsupervised Domain Adaptation Learners
Jun 01, 2021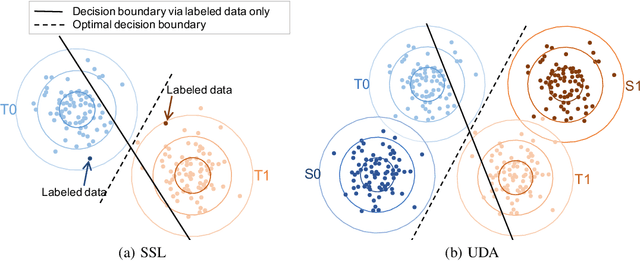

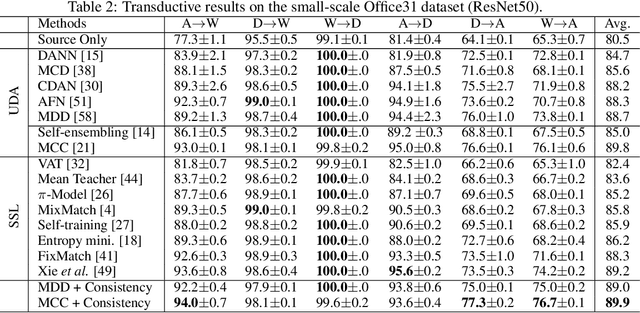
Unsupervised domain adaptation (UDA) and semi-supervised learning (SSL) are two typical strategies to reduce expensive manual annotations in machine learning. In order to learn effective models for a target task, UDA utilizes the available labeled source data, which may have different distributions from unlabeled samples in the target domain, while SSL employs few manually annotated target samples. Although UDA and SSL are seemingly very different strategies, we find that they are closely related in terms of task objectives and solutions, and SSL is a special case of UDA problems. Based on this finding, we further investigate whether SSL methods work on UDA tasks. By adapting eight representative SSL algorithms on UDA benchmarks, we show that SSL methods are strong UDA learners. Especially, state-of-the-art SSL methods significantly outperform existing UDA methods on the challenging UDA benchmark of DomainNet, and state-of-the-art UDA methods could be further enhanced with SSL techniques. We thus promote that SSL methods should be employed as baselines in future UDA studies and expect that the revealed relationship between UDA and SSL could shed light on future UDA development. Codes are available at \url{https://github.com/YBZh}.
Unsupervised Domain Adaptation of Black-Box Source Models
Jan 08, 2021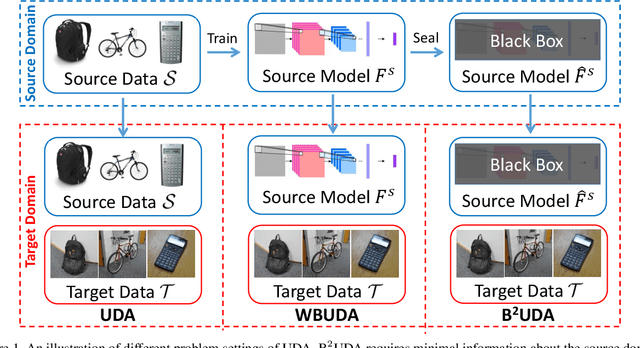

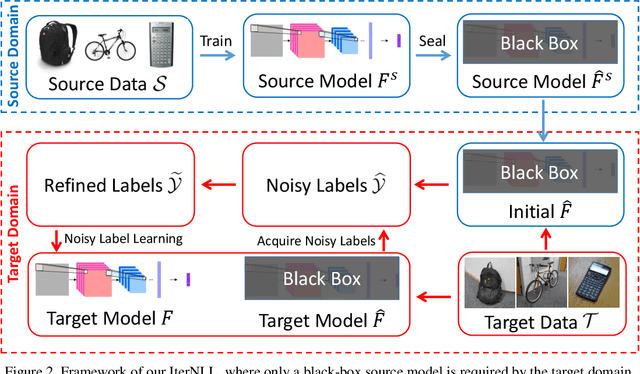
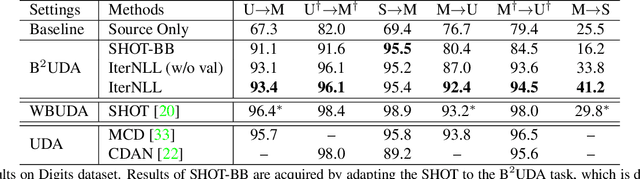
Unsupervised domain adaptation (UDA) aims to learn a model for unlabeled data on a target domain by transferring knowledge from a labeled source domain. In the traditional UDA setting, labeled source data are assumed to be available for the use of model adaptation. Due to the increasing concerns for data privacy, source-free UDA is highly appreciated as a new UDA setting, where only a trained source model is assumed to be available, while the labeled source data remain private. However, exposing details of the trained source model for UDA use is prone to easily committed white-box attacks, which brings severe risks to the source tasks themselves. To address this issue, we advocate studying a subtly different setting, named Black-Box Unsupervised Domain Adaptation (B2UDA), where only the input-output interface of the source model is accessible in UDA; in other words, the source model itself is kept as a black-box one. To tackle the B2UDA task, we propose a simple yet effective method, termed Iterative Noisy Label Learning (IterNLL). IterNLL starts with getting noisy labels of the unlabeled target data from the black-box source model. It then alternates between learning improved target models from the target subset with more reliable labels and updating the noisy target labels. Experiments on benchmark datasets confirm the efficacy of our proposed method. Notably, IterNLL performs comparably with methods of the traditional UDA setting where the labeled source data are fully available.