 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
TransST: Transfer Learning Embedded Spatial Factor Modeling of Spatial Transcriptomics Data
Apr 15, 2025



Background: Spatial transcriptomics have emerged as a powerful tool in biomedical research because of its ability to capture both the spatial contexts and abundance of the complete RNA transcript profile in organs of interest. However, limitations of the technology such as the relatively low resolution and comparatively insufficient sequencing depth make it difficult to reliably extract real biological signals from these data. To alleviate this challenge, we propose a novel transfer learning framework, referred to as TransST, to adaptively leverage the cell-labeled information from external sources in inferring cell-level heterogeneity of a target spatial transcriptomics data. Results: Applications in several real studies as well as a number of simulation settings show that our approach significantly improves existing techniques. For example, in the breast cancer study, TransST successfully identifies five biologically meaningful cell clusters, including the two subgroups of cancer in situ and invasive cancer; in addition, only TransST is able to separate the adipose tissues from the connective issues among all the studied methods. Conclusions: In summary, the proposed method TransST is both effective and robust in identifying cell subclusters and detecting corresponding driving biomarkers in spatial transcriptomics data.
Zero-shot Generalizable Incremental Learning for Vision-Language Object Detection
Mar 04, 2024
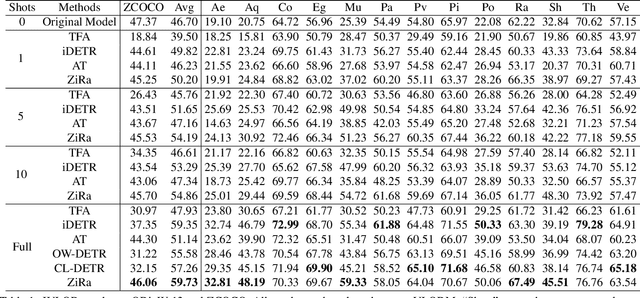
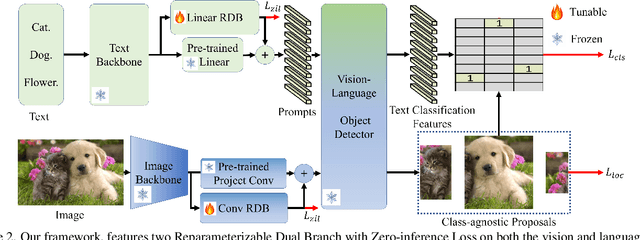

This paper presents Incremental Vision-Language Object Detection (IVLOD), a novel learning task designed to incrementally adapt pre-trained Vision-Language Object Detection Models (VLODMs) to various specialized domains, while simultaneously preserving their zero-shot generalization capabilities for the generalized domain. To address this new challenge, we present the Zero-interference Reparameterizable Adaptation (ZiRa), a novel method that introduces Zero-interference Loss and reparameterization techniques to tackle IVLOD without incurring additional inference costs or a significant increase in memory usage. Comprehensive experiments on COCO and ODinW-13 datasets demonstrate that ZiRa effectively safeguards the zero-shot generalization ability of VLODMs while continuously adapting to new tasks. Specifically, after training on ODinW-13 datasets, ZiRa exhibits superior performance compared to CL-DETR and iDETR, boosting zero-shot generalizability by substantial 13.91 and 8.71 AP, respectively.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023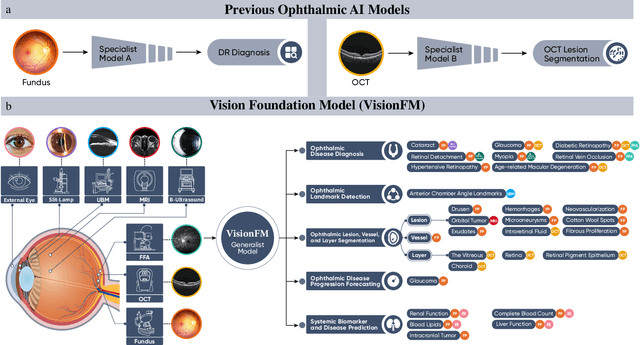
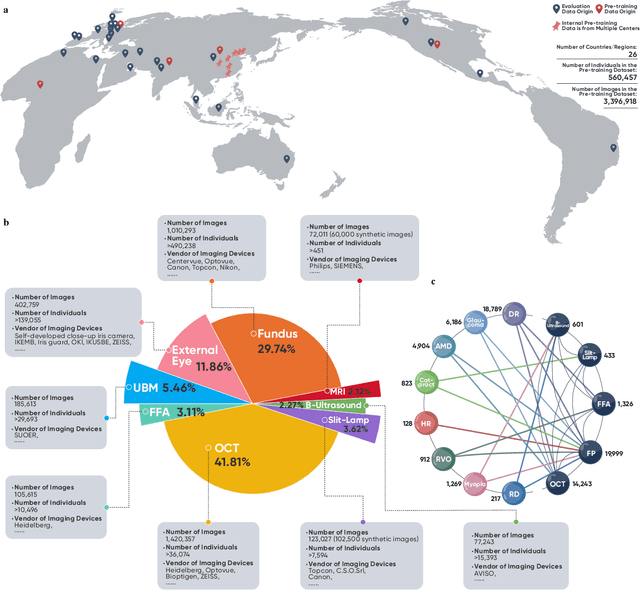

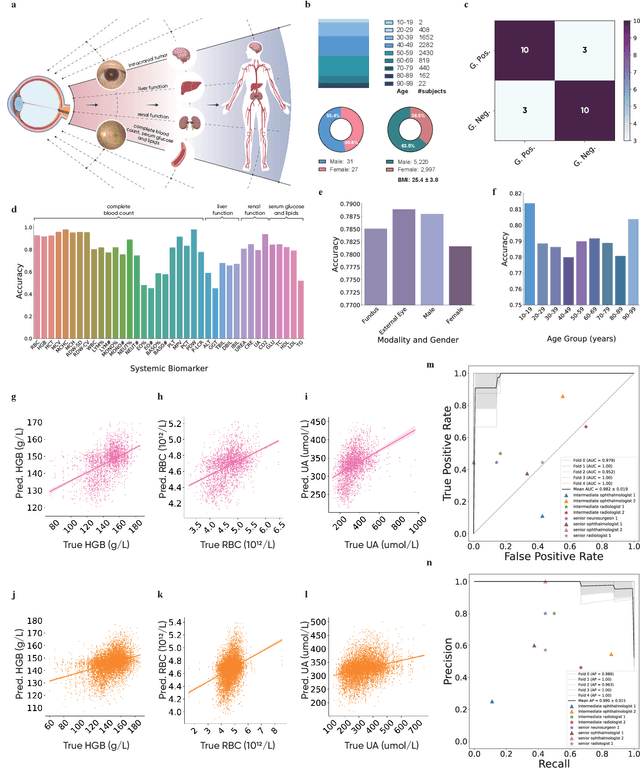
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
Incremental Prototype Prompt-tuning with Pre-trained Representation for Class Incremental Learning
Apr 11, 2022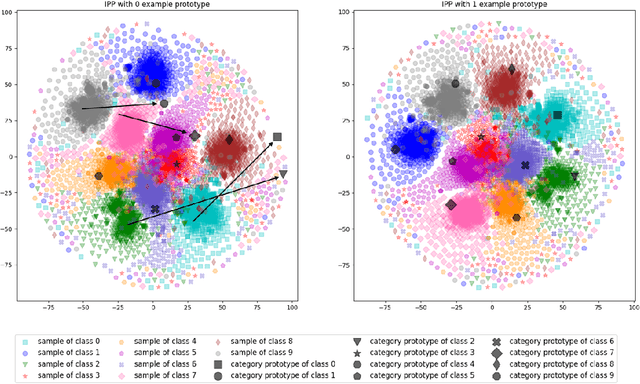
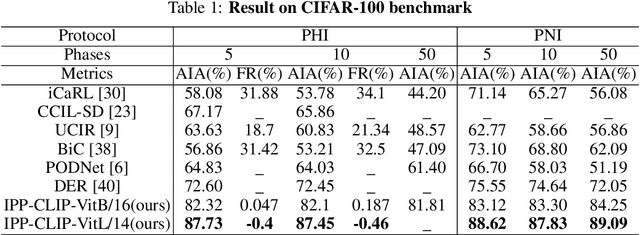
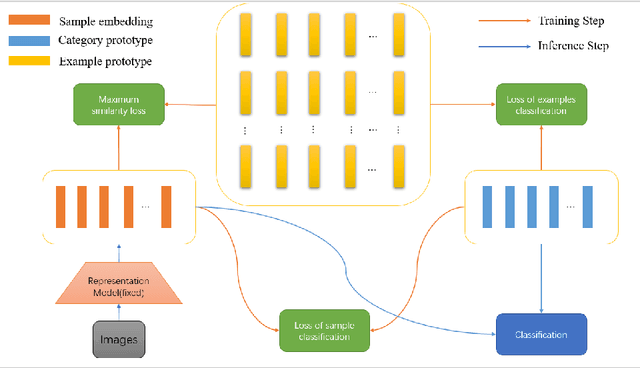
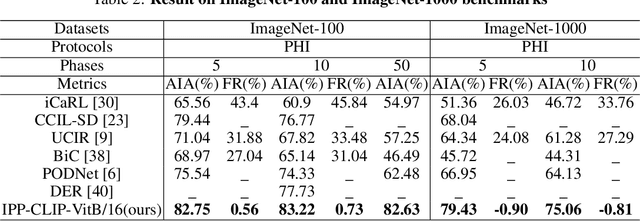
Class incremental learning has attracted much attention, but most existing works still continually fine-tune the representation model, resulting in much catastrophic forgetting. Instead of struggling to fight against such forgetting by replaying or distillation like most of the existing methods, we take the pre-train-and-prompt-tuning paradigm to sequentially learn new visual concepts based on a fixed semantic rich pre-trained representation model by incremental prototype prompt-tuning (IPP), which substantially reduces the catastrophic forgetting. In addition, an example prototype classification is proposed to compensate for semantic drift, the problem caused by learning bias at different phases. Extensive experiments conducted on the three incremental learning benchmarks demonstrate that our method consistently outperforms other state-of-the-art methods with a large margin.