 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Generalizable Incremental Learning for Vision-Language Object Detection
Mar 04, 2024
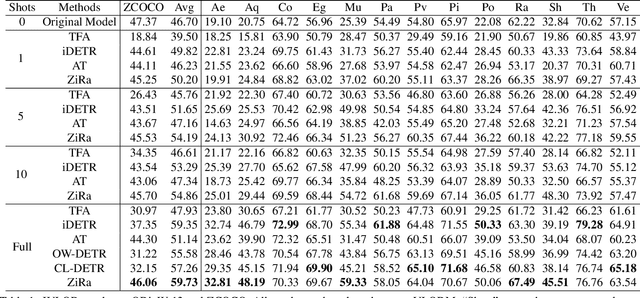
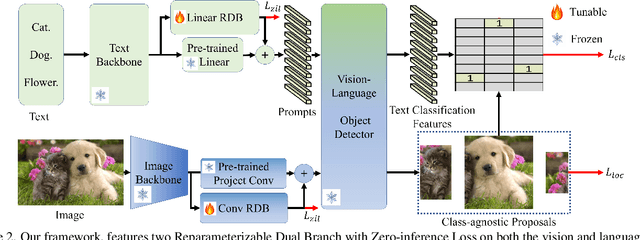

This paper presents Incremental Vision-Language Object Detection (IVLOD), a novel learning task designed to incrementally adapt pre-trained Vision-Language Object Detection Models (VLODMs) to various specialized domains, while simultaneously preserving their zero-shot generalization capabilities for the generalized domain. To address this new challenge, we present the Zero-interference Reparameterizable Adaptation (ZiRa), a novel method that introduces Zero-interference Loss and reparameterization techniques to tackle IVLOD without incurring additional inference costs or a significant increase in memory usage. Comprehensive experiments on COCO and ODinW-13 datasets demonstrate that ZiRa effectively safeguards the zero-shot generalization ability of VLODMs while continuously adapting to new tasks. Specifically, after training on ODinW-13 datasets, ZiRa exhibits superior performance compared to CL-DETR and iDETR, boosting zero-shot generalizability by substantial 13.91 and 8.71 AP, respectively.
Incremental Prototype Prompt-tuning with Pre-trained Representation for Class Incremental Learning
Apr 11, 2022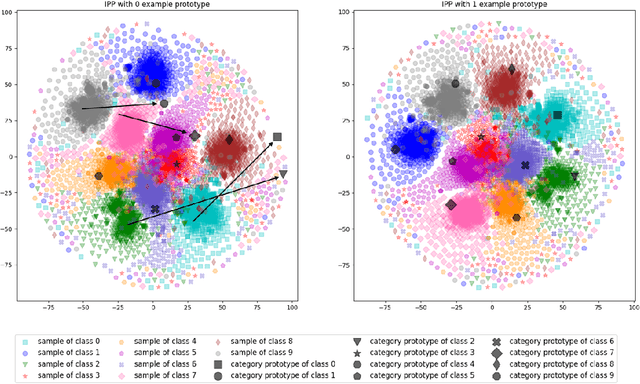
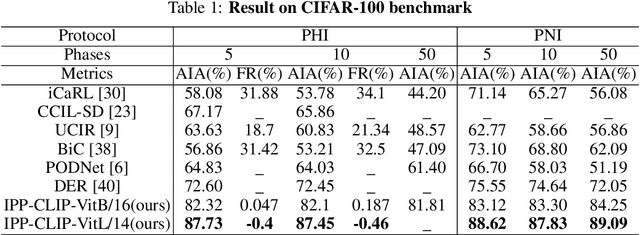
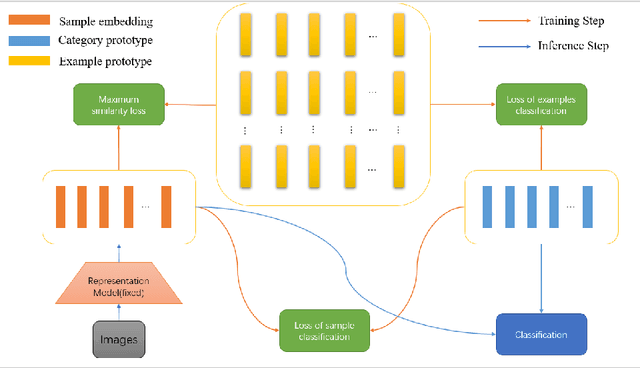
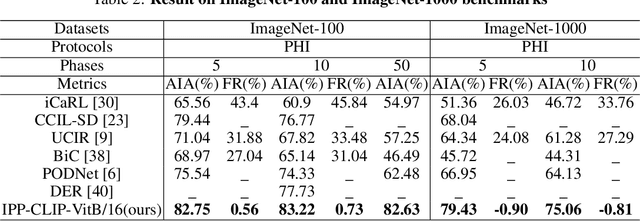
Class incremental learning has attracted much attention, but most existing works still continually fine-tune the representation model, resulting in much catastrophic forgetting. Instead of struggling to fight against such forgetting by replaying or distillation like most of the existing methods, we take the pre-train-and-prompt-tuning paradigm to sequentially learn new visual concepts based on a fixed semantic rich pre-trained representation model by incremental prototype prompt-tuning (IPP), which substantially reduces the catastrophic forgetting. In addition, an example prototype classification is proposed to compensate for semantic drift, the problem caused by learning bias at different phases. Extensive experiments conducted on the three incremental learning benchmarks demonstrate that our method consistently outperforms other state-of-the-art methods with a large margin.