 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSFC-Net: A Dual-Encoder Spatial and Frequency Co-Awareness Network for Rural Road Extraction
Feb 01, 2026Accurate extraction of rural roads from high-resolution remote sensing imagery is essential for infrastructure planning and sustainable development. However, this task presents unique challenges in rural settings due to several factors. These include high intra-class variability and low inter-class separability from diverse surface materials, frequent vegetation occlusions that disrupt spatial continuity, and narrow road widths that exacerbate detection difficulties. Existing methods, primarily optimized for structured urban environments, often underperform in these scenarios as they overlook such distinctive characteristics. To address these challenges, we propose DSFC-Net, a dual-encoder framework that synergistically fuses spatial and frequency-domain information. Specifically, a CNN branch is employed to capture fine-grained local road boundaries and short-range continuity, while a novel Spatial-Frequency Hybrid Transformer (SFT) is introduced to robustly model global topological dependencies against vegetation occlusions. Distinct from standard attention mechanisms that suffer from frequency bias, the SFT incorporates a Cross-Frequency Interaction Attention (CFIA) module that explicitly decouples high- and low-frequency information via a Laplacian Pyramid strategy. This design enables the dynamic interaction between spatial details and frequency-aware global contexts, effectively preserving the connectivity of narrow roads. Furthermore, a Channel Feature Fusion Module (CFFM) is proposed to bridge the two branches by adaptively recalibrating channel-wise feature responses, seamlessly integrating local textures with global semantics for accurate segmentation. Comprehensive experiments on the WHU-RuR+, DeepGlobe, and Massachusetts datasets validate the superiority of DSFC-Net over state-of-the-art approaches.
PDE-Agent: A toolchain-augmented multi-agent framework for PDE solving
Dec 22, 2025



Solving Partial Differential Equations (PDEs) is a cornerstone of engineering and scientific research. Traditional methods for PDE solving are cumbersome, relying on manual setup and domain expertise. While Physics-Informed Neural Network (PINNs) introduced end-to-end neural network-based solutions, and frameworks like DeepXDE further enhanced automation, these approaches still depend on expert knowledge and lack full autonomy. In this work, we frame PDE solving as tool invocation via LLM-driven agents and introduce PDE-Agent, the first toolchain-augmented multi-agent collaboration framework, inheriting the reasoning capacity of LLMs and the controllability of external tools and enabling automated PDE solving from natural language descriptions. PDE-Agent leverages the strengths of multi-agent and multi-tool collaboration through two key innovations: (1) A Prog-Act framework with graph memory for multi-agent collaboration, which enables effective dynamic planning and error correction via dual-loop mechanisms (localized fixes and global revisions). (2) A Resource-Pool integrated with a tool-parameter separation mechanism for multi-tool collaboration. This centralizes the management of runtime artifacts and resolves inter-tool dependency gaps in existing frameworks. To validate and evaluate this new paradigm for PDE solving , we develop PDE-Bench, a multi-type PDE Benchmark for agent-based tool collaborative solving, and propose multi-level metrics for assessing tool coordination. Evaluations verify that PDE-Agent exhibits superior applicability and performance in complex multi-step, cross-step dependent tasks. This new paradigm of toolchain-augmented multi-agent PDE solving will further advance future developments in automated scientific computing. Our source code and dataset will be made publicly available.
Fault Diagnosis and Quantification for Photovoltaic Arrays based on Differentiable Physical Models
Dec 18, 2025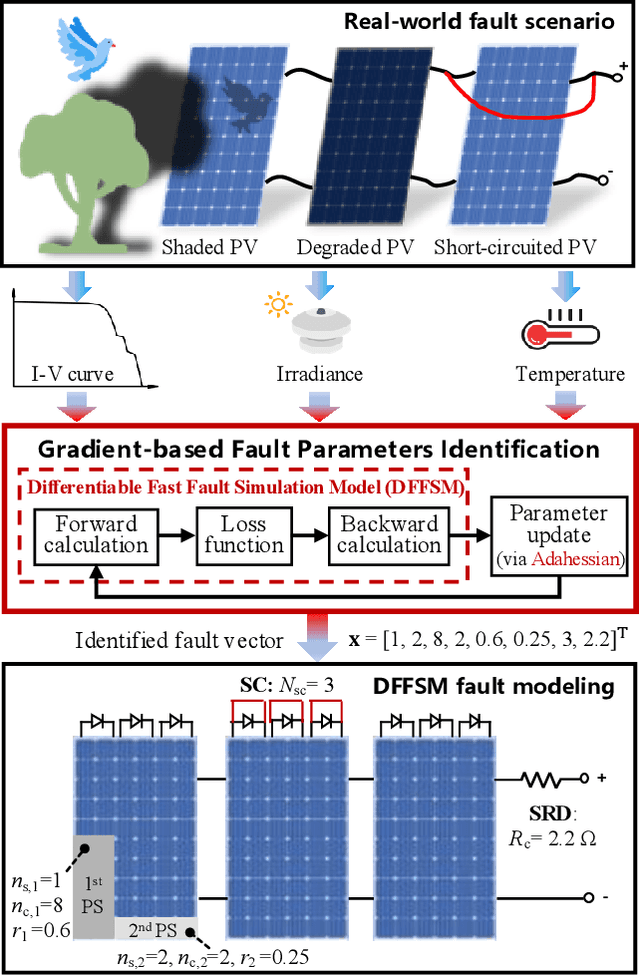
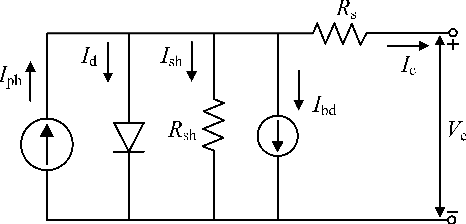
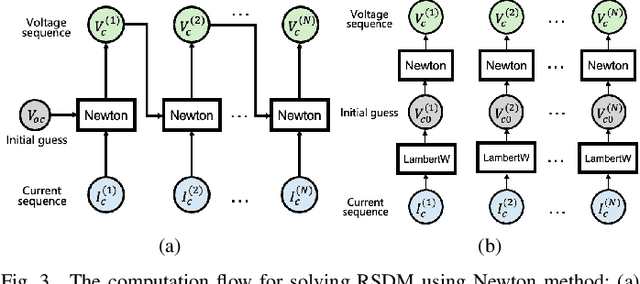
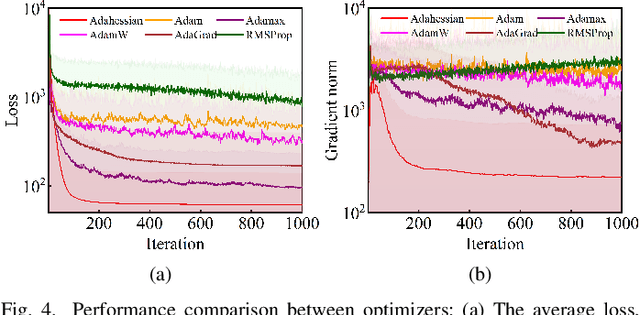
Accurate fault diagnosis and quantification are essential for the reliable operation and intelligent maintenance of photovoltaic (PV) arrays. However, existing fault quantification methods often suffer from limited efficiency and interpretability. To address these challenges, this paper proposes a novel fault quantification approach for PV strings based on a differentiable fast fault simulation model (DFFSM). The proposed DFFSM accurately models I-V characteristics under multiple faults and provides analytical gradients with respect to fault parameters. Leveraging this property, a gradient-based fault parameters identification (GFPI) method using the Adahessian optimizer is developed to efficiently quantify partial shading, short-circuit, and series-resistance degradation. Experimental results on both simulated and measured I-V curves demonstrate that the proposed GFPI achieves high quantification accuracy across different faults, with the I-V reconstruction error below 3%, confirming the feasibility and effectiveness of the application of differentiable physical simulators for PV system fault diagnosis.
IF-Bench: Benchmarking and Enhancing MLLMs for Infrared Images with Generative Visual Prompting
Dec 10, 2025Recent advances in multimodal large language models (MLLMs) have led to impressive progress across various benchmarks. However, their capability in understanding infrared images remains unexplored. To address this gap, we introduce IF-Bench, the first high-quality benchmark designed for evaluating multimodal understanding of infrared images. IF-Bench consists of 499 images sourced from 23 infrared datasets and 680 carefully curated visual question-answer pairs, covering 10 essential dimensions of image understanding. Based on this benchmark, we systematically evaluate over 40 open-source and closed-source MLLMs, employing cyclic evaluation, bilingual assessment, and hybrid judgment strategies to enhance the reliability of the results. Our analysis reveals how model scale, architecture, and inference paradigms affect infrared image comprehension, providing valuable insights for this area. Furthermore, we propose a training-free generative visual prompting (GenViP) method, which leverages advanced image editing models to translate infrared images into semantically and spatially aligned RGB counterparts, thereby mitigating domain distribution shifts. Extensive experiments demonstrate that our method consistently yields significant performance improvements across a wide range of MLLMs. The benchmark and code are available at https://github.com/casiatao/IF-Bench.
Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models Stronger
Jun 09, 2025Recent advancements in Large Vision Language Models (LVLMs) have significantly improved performance in Visual Question Answering (VQA) tasks through multimodal Retrieval-Augmented Generation (RAG). However, existing methods still face challenges, such as the scarcity of knowledge with reasoning examples and erratic responses from retrieved knowledge. To address these issues, in this study, we propose a multimodal RAG framework, termed RCTS, which enhances LVLMs by constructing a Reasoning Context-enriched knowledge base and a Tree Search re-ranking method. Specifically, we introduce a self-consistent evaluation mechanism to enrich the knowledge base with intrinsic reasoning patterns. We further propose a Monte Carlo Tree Search with Heuristic Rewards (MCTS-HR) to prioritize the most relevant examples. This ensures that LVLMs can leverage high-quality contextual reasoning for better and more consistent responses. Extensive experiments demonstrate that our framework achieves state-of-the-art performance on multiple VQA datasets, significantly outperforming In-Context Learning (ICL) and Vanilla-RAG methods. It highlights the effectiveness of our knowledge base and re-ranking method in improving LVLMs. Our code is available at https://github.com/yannqi/RCTS-RAG.
UNIP: Rethinking Pre-trained Attention Patterns for Infrared Semantic Segmentation
Feb 04, 2025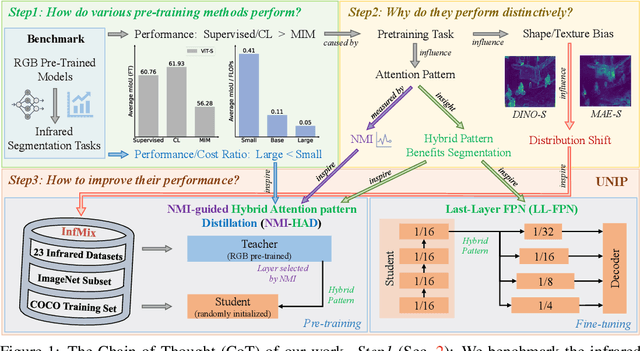
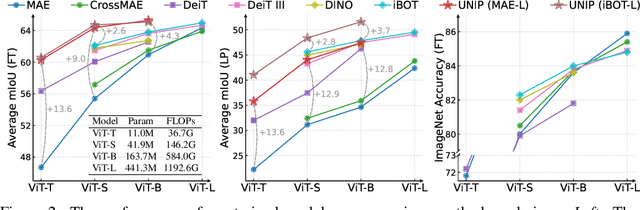
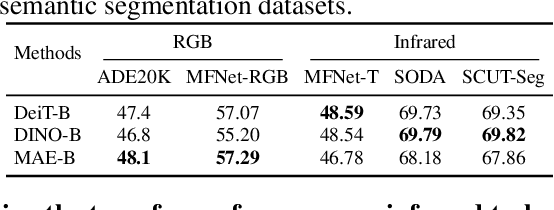
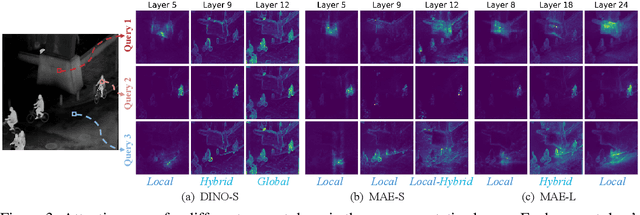
Pre-training techniques significantly enhance the performance of semantic segmentation tasks with limited training data. However, the efficacy under a large domain gap between pre-training (e.g. RGB) and fine-tuning (e.g. infrared) remains underexplored. In this study, we first benchmark the infrared semantic segmentation performance of various pre-training methods and reveal several phenomena distinct from the RGB domain. Next, our layerwise analysis of pre-trained attention maps uncovers that: (1) There are three typical attention patterns (local, hybrid, and global); (2) Pre-training tasks notably influence the pattern distribution across layers; (3) The hybrid pattern is crucial for semantic segmentation as it attends to both nearby and foreground elements; (4) The texture bias impedes model generalization in infrared tasks. Building on these insights, we propose UNIP, a UNified Infrared Pre-training framework, to enhance the pre-trained model performance. This framework uses the hybrid-attention distillation NMI-HAD as the pre-training target, a large-scale mixed dataset InfMix for pre-training, and a last-layer feature pyramid network LL-FPN for fine-tuning. Experimental results show that UNIP outperforms various pre-training methods by up to 13.5\% in average mIoU on three infrared segmentation tasks, evaluated using fine-tuning and linear probing metrics. UNIP-S achieves performance on par with MAE-L while requiring only 1/10 of the computational cost. Furthermore, UNIP significantly surpasses state-of-the-art (SOTA) infrared or RGB segmentation methods and demonstrates broad potential for application in other modalities, such as RGB and depth. Our code is available at https://github.com/casiatao/UNIP.
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
Feb 03, 2025



Preference optimization for diffusion models aims to align them with human preferences for images. Previous methods typically leverage Vision-Language Models (VLMs) as pixel-level reward models to approximate human preferences. However, when used for step-level preference optimization, these models face challenges in handling noisy images of different timesteps and require complex transformations into pixel space. In this work, we demonstrate that diffusion models are inherently well-suited for step-level reward modeling in the latent space, as they can naturally extract features from noisy latent images. Accordingly, we propose the Latent Reward Model (LRM), which repurposes components of diffusion models to predict preferences of latent images at various timesteps. Building on LRM, we introduce Latent Preference Optimization (LPO), a method designed for step-level preference optimization directly in the latent space. Experimental results indicate that LPO not only significantly enhances performance in aligning diffusion models with general, aesthetic, and text-image alignment preferences, but also achieves 2.5-28$\times$ training speedup compared to existing preference optimization methods. Our code will be available at https://github.com/casiatao/LPO.
Efficient Redundancy Reduction for Open-Vocabulary Semantic Segmentation
Jan 29, 2025



Open-vocabulary semantic segmentation (OVSS) is an open-world task that aims to assign each pixel within an image to a specific class defined by arbitrary text descriptions. Recent advancements in large-scale vision-language models have demonstrated their open-vocabulary understanding capabilities, significantly facilitating the development of OVSS. However, most existing methods suffer from either suboptimal performance or long latency. This study introduces ERR-Seg, a novel framework that effectively reduces redundancy to balance accuracy and efficiency. ERR-Seg incorporates a training-free Channel Reduction Module (CRM) that leverages prior knowledge from vision-language models like CLIP to identify the most relevant classes while discarding others. Moreover, it incorporates Efficient Semantic Context Fusion (ESCF) with spatial-level and class-level sequence reduction strategies. CRM and ESCF result in substantial memory and computational savings without compromising accuracy. Additionally, recognizing the significance of hierarchical semantics extracted from middle-layer features for closed-set semantic segmentation, ERR-Seg introduces the Hierarchical Semantic Module (HSM) to exploit hierarchical semantics in the context of OVSS. Compared to previous state-of-the-art methods under the ADE20K-847 setting, ERR-Seg achieves +$5.6\%$ mIoU improvement and reduces latency by $67.3\%$.
Rethinking Comprehensive Benchmark for Chart Understanding: A Perspective from Scientific Literature
Dec 11, 2024



Scientific Literature charts often contain complex visual elements, including multi-plot figures, flowcharts, structural diagrams and etc. Evaluating multimodal models using these authentic and intricate charts provides a more accurate assessment of their understanding abilities. However, existing benchmarks face limitations: a narrow range of chart types, overly simplistic template-based questions and visual elements, and inadequate evaluation methods. These shortcomings lead to inflated performance scores that fail to hold up when models encounter real-world scientific charts. To address these challenges, we introduce a new benchmark, Scientific Chart QA (SCI-CQA), which emphasizes flowcharts as a critical yet often overlooked category. To overcome the limitations of chart variety and simplistic visual elements, we curated a dataset of 202,760 image-text pairs from 15 top-tier computer science conferences papers over the past decade. After rigorous filtering, we refined this to 37,607 high-quality charts with contextual information. SCI-CQA also introduces a novel evaluation framework inspired by human exams, encompassing 5,629 carefully curated questions, both objective and open-ended. Additionally, we propose an efficient annotation pipeline that significantly reduces data annotation costs. Finally, we explore context-based chart understanding, highlighting the crucial role of contextual information in solving previously unanswerable questions.
Continuous Speculative Decoding for Autoregressive Image Generation
Nov 18, 2024Continuous-valued Autoregressive (AR) image generation models have demonstrated notable superiority over their discrete-token counterparts, showcasing considerable reconstruction quality and higher generation fidelity. However, the computational demands of the autoregressive framework result in significant inference overhead. While speculative decoding has proven effective in accelerating Large Language Models (LLMs), their adaptation to continuous-valued visual autoregressive models remains unexplored. This work generalizes the speculative decoding algorithm from discrete tokens to continuous space. By analyzing the intrinsic properties of output distribution, we establish a tailored acceptance criterion for the diffusion distributions prevalent in such models. To overcome the inconsistency that occurred in speculative decoding output distributions, we introduce denoising trajectory alignment and token pre-filling methods. Additionally, we identify the hard-to-sample distribution in the rejection phase. To mitigate this issue, we propose a meticulous acceptance-rejection sampling method with a proper upper bound, thereby circumventing complex integration. Experimental results show that our continuous speculative decoding achieves a remarkable $2.33\times$ speed-up on off-the-shelf models while maintaining the output distribution. Codes will be available at https://github.com/MarkXCloud/CSpD