 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Network Graph Comparative Learning
Jan 15, 2026The effectiveness of contrastive learning methods has been widely recognized in the field of graph learning, especially in contexts where graph data often lack labels or are difficult to label. However, the application of these methods to node classification tasks still faces a number of challenges. First, existing data enhancement techniques may lead to significant differences from the original view when generating new views, which may weaken the relevance of the view and affect the efficiency of model training. Second, the vast majority of existing graph comparison learning algorithms rely on the use of a large number of negative samples. To address the above challenges, this study proposes a novel node classification contrast learning method called Simple Network Graph Comparative Learning (SNGCL). Specifically, SNGCL employs a superimposed multilayer Laplace smoothing filter as a step in processing the data to obtain global and local feature smoothing matrices, respectively, which are thus passed into the target and online networks of the siamese network, and finally employs an improved triple recombination loss function to bring the intra-class distance closer and the inter-class distance farther. We have compared SNGCL with state-of-the-art models in node classification tasks, and the experimental results show that SNGCL is strongly competitive in most tasks.
Defense Against Indirect Prompt Injection via Tool Result Parsing
Jan 08, 2026As LLM agents transition from digital assistants to physical controllers in autonomous systems and robotics, they face an escalating threat from indirect prompt injection. By embedding adversarial instructions into the results of tool calls, attackers can hijack the agent's decision-making process to execute unauthorized actions. This vulnerability poses a significant risk as agents gain more direct control over physical environments. Existing defense mechanisms against Indirect Prompt Injection (IPI) generally fall into two categories. The first involves training dedicated detection models; however, this approach entails high computational overhead for both training and inference, and requires frequent updates to keep pace with evolving attack vectors. Alternatively, prompt-based methods leverage the inherent capabilities of LLMs to detect or ignore malicious instructions via prompt engineering. Despite their flexibility, most current prompt-based defenses suffer from high Attack Success Rates (ASR), demonstrating limited robustness against sophisticated injection attacks. In this paper, we propose a novel method that provides LLMs with precise data via tool result parsing while effectively filtering out injected malicious code. Our approach achieves competitive Utility under Attack (UA) while maintaining the lowest Attack Success Rate (ASR) to date, significantly outperforming existing methods. Code is available at GitHub.
A Brain-Inspired Gating Mechanism Unlocks Robust Computation in Spiking Neural Networks
Sep 03, 2025



While spiking neural networks (SNNs) provide a biologically inspired and energy-efficient computational framework, their robustness and the dynamic advantages inherent to biological neurons remain significantly underutilized owing to oversimplified neuron models. In particular, conventional leaky integrate-and-fire (LIF) neurons often omit the dynamic conductance mechanisms inherent in biological neurons, thereby limiting their capacity to cope with noise and temporal variability. In this work, we revisit dynamic conductance from a functional perspective and uncover its intrinsic role as a biologically plausible gating mechanism that modulates information flow. Building on this insight, we introduce the Dynamic Gated Neuron~(DGN), a novel spiking unit in which membrane conductance evolves in response to neuronal activity, enabling selective input filtering and adaptive noise suppression. We provide a theoretical analysis showing that DGN possess enhanced stochastic stability compared to standard LIF models, with dynamic conductance intriguingly acting as a disturbance rejection mechanism. DGN-based SNNs demonstrate superior performance across extensive evaluations on anti-noise tasks and temporal-related benchmarks such as TIDIGITS and SHD, consistently exhibiting excellent robustness. Our results highlight, for the first time, a biologically plausible dynamic gating as a key mechanism for robust spike-based computation, providing not only theoretical guarantees but also strong empirical validations. This work thus paves the way for more resilient, efficient, and biologically inspired spiking neural networks.
Quantization Meets Spikes: Lossless Conversion in the First Timestep via Polarity Multi-Spike Mapping
Aug 20, 2025Spiking neural networks (SNNs) offer advantages in computational efficiency via event-driven computing, compared to traditional artificial neural networks (ANNs). While direct training methods tackle the challenge of non-differentiable activation mechanisms in SNNs, they often suffer from high computational and energy costs during training. As a result, ANN-to-SNN conversion approach still remains a valuable and practical alternative. These conversion-based methods aim to leverage the discrete output produced by the quantization layer to obtain SNNs with low latency. Although the theoretical minimum latency is one timestep, existing conversion methods have struggled to realize such ultra-low latency without accuracy loss. Moreover, current quantization approaches often discard negative-value information following batch normalization and are highly sensitive to the hyperparameter configuration, leading to degraded performance. In this work, we, for the first time, analyze the information loss introduced by quantization layers through the lens of information entropy. Building on our analysis, we introduce Polarity Multi-Spike Mapping (PMSM) and a hyperparameter adjustment strategy tailored for the quantization layer. Our method achieves nearly lossless ANN-to-SNN conversion at the extremity, i.e., the first timestep, while also leveraging the temporal dynamics of SNNs across multiple timesteps to maintain stable performance on complex tasks. Experimental results show that our PMSM achieves state-of-the-art accuracies of 98.5% on CIFAR-10, 89.3% on CIFAR-100 and 81.6% on ImageNet with only one timestep on ViT-S architecture, establishing a new benchmark for efficient conversion. In addition, our method reduces energy consumption by over 5x under VGG-16 on CIFAR-10 and CIFAR-100, compared to the baseline method.
Combining Aggregated Attention and Transformer Architecture for Accurate and Efficient Performance of Spiking Neural Networks
Dec 18, 2024Spiking Neural Networks have attracted significant attention in recent years due to their distinctive low-power characteristics. Meanwhile, Transformer models, known for their powerful self-attention mechanisms and parallel processing capabilities, have demonstrated exceptional performance across various domains, including natural language processing and computer vision. Despite the significant advantages of both SNNs and Transformers, directly combining the low-power benefits of SNNs with the high performance of Transformers remains challenging. Specifically, while the sparse computing mode of SNNs contributes to reduced energy consumption, traditional attention mechanisms depend on dense matrix computations and complex softmax operations. This reliance poses significant challenges for effective execution in low-power scenarios. Given the tremendous success of Transformers in deep learning, it is a necessary step to explore the integration of SNNs and Transformers to harness the strengths of both. In this paper, we propose a novel model architecture, Spike Aggregation Transformer (SAFormer), that integrates the low-power characteristics of SNNs with the high-performance advantages of Transformer models. The core contribution of SAFormer lies in the design of the Spike Aggregated Self-Attention (SASA) mechanism, which significantly simplifies the computation process by calculating attention weights using only the spike matrices query and key, thereby effectively reducing energy consumption. Additionally, we introduce a Depthwise Convolution Module (DWC) to enhance the feature extraction capabilities, further improving overall accuracy. We evaluated and demonstrated that SAFormer outperforms state-of-the-art SNNs in both accuracy and energy consumption, highlighting its significant advantages in low-power and high-performance computing.
Calibrated Cache Model for Few-Shot Vision-Language Model Adaptation
Oct 11, 2024
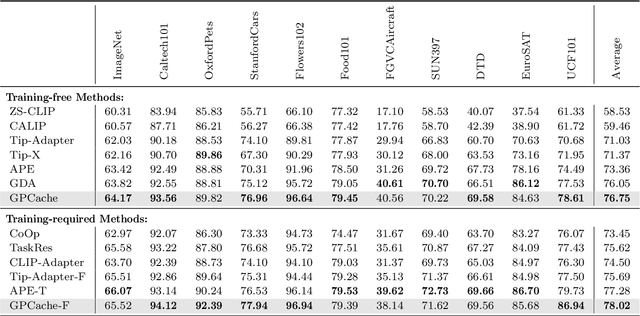
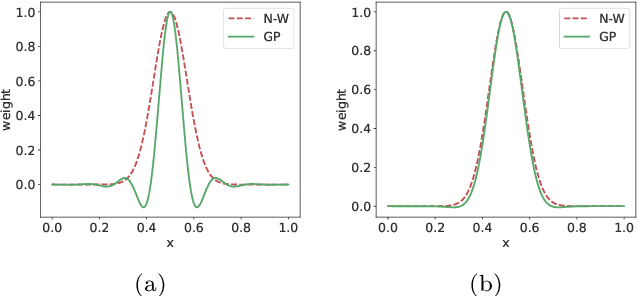
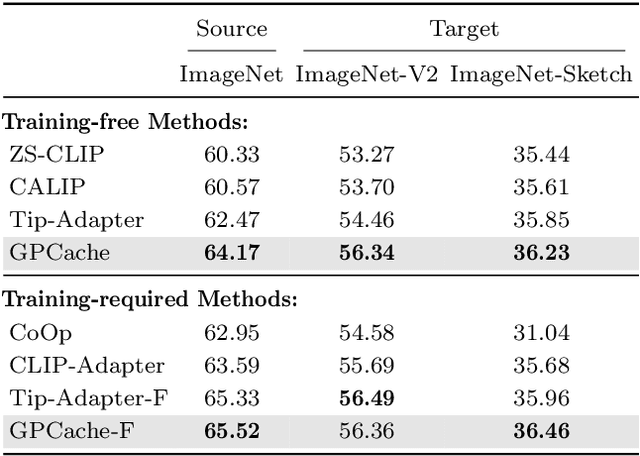
Cache-based approaches stand out as both effective and efficient for adapting vision-language models (VLMs). Nonetheless, the existing cache model overlooks three crucial aspects. 1) Pre-trained VLMs are mainly optimized for image-text similarity, neglecting the importance of image-image similarity, leading to a gap between pre-training and adaptation. 2) The current cache model is based on the Nadaraya-Watson (N-W) estimator, which disregards the intricate relationships among training samples while constructing weight function. 3) Under the condition of limited samples, the logits generated by cache model are of high uncertainty, directly using these logits without accounting for the confidence could be problematic. This work presents three calibration modules aimed at addressing the above challenges. Similarity Calibration refines the image-image similarity by using unlabeled images. We add a learnable projection layer with residual connection on top of the pre-trained image encoder of CLIP and optimize the parameters by minimizing self-supervised contrastive loss. Weight Calibration introduces a precision matrix into the weight function to adequately model the relation between training samples, transforming the existing cache model to a Gaussian Process (GP) regressor, which could be more accurate than N-W estimator. Confidence Calibration leverages the predictive variances computed by GP Regression to dynamically re-scale the logits of cache model, ensuring that the cache model's outputs are appropriately adjusted based on their confidence levels. Besides, to reduce the high complexity of GPs, we further propose a group-based learning strategy. Integrating the above designs, we propose both training-free and training-required variants. Extensive experiments on 11 few-shot classification datasets validate that the proposed methods can achieve state-of-the-art performance.
Weak Distribution Detectors Lead to Stronger Generalizability of Vision-Language Prompt Tuning
Mar 31, 2024



We propose a generalized method for boosting the generalization ability of pre-trained vision-language models (VLMs) while fine-tuning on downstream few-shot tasks. The idea is realized by exploiting out-of-distribution (OOD) detection to predict whether a sample belongs to a base distribution or a novel distribution and then using the score generated by a dedicated competition based scoring function to fuse the zero-shot and few-shot classifier. The fused classifier is dynamic, which will bias towards the zero-shot classifier if a sample is more likely from the distribution pre-trained on, leading to improved base-to-novel generalization ability. Our method is performed only in test stage, which is applicable to boost existing methods without time-consuming re-training. Extensive experiments show that even weak distribution detectors can still improve VLMs' generalization ability. Specifically, with the help of OOD detectors, the harmonic mean of CoOp and ProGrad increase by 2.6 and 1.5 percentage points over 11 recognition datasets in the base-to-novel setting.
Compositional Kronecker Context Optimization for Vision-Language Models
Mar 18, 2024Context Optimization (CoOp) has emerged as a simple yet effective technique for adapting CLIP-like vision-language models to downstream image recognition tasks. Nevertheless, learning compact context with satisfactory base-to-new, domain and cross-task generalization ability while adapting to new tasks is still a challenge. To tackle such a challenge, we propose a lightweight yet generalizable approach termed Compositional Kronecker Context Optimization (CK-CoOp). Technically, the prompt's context words in CK-CoOp are learnable vectors, which are crafted by linearly combining base vectors sourced from a dictionary. These base vectors consist of a non-learnable component obtained by quantizing the weights in the token embedding layer, and a learnable component constructed by applying Kronecker product on several learnable tiny matrices. Intuitively, the compositional structure mitigates the risk of overfitting on training data by remembering more pre-trained knowledge. Meantime, the Kronecker product breaks the non-learnable restrictions of the dictionary, thereby enhancing representation ability with minimal additional parameters. Extensive experiments confirm that CK-CoOp achieves state-of-the-art performance under base-to-new, domain and cross-task generalization evaluation, but also has the metrics of fewer learnable parameters and efficient training and inference speed.
Prompt Tuning with Soft Context Sharing for Vision-Language Models
Aug 29, 2022

Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.
Consensus Graph Representation Learning for Better Grounded Image Captioning
Dec 02, 2021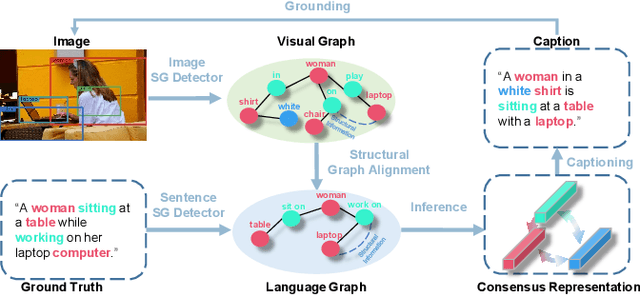
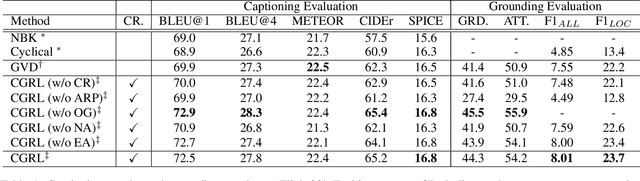
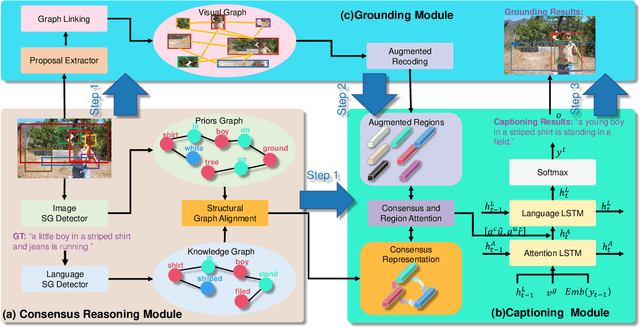
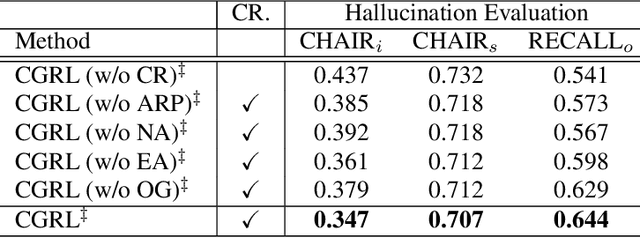
The contemporary visual captioning models frequently hallucinate objects that are not actually in a scene, due to the visual misclassification or over-reliance on priors that resulting in the semantic inconsistency between the visual information and the target lexical words. The most common way is to encourage the captioning model to dynamically link generated object words or phrases to appropriate regions of the image, i.e., the grounded image captioning (GIC). However, GIC utilizes an auxiliary task (grounding objects) that has not solved the key issue of object hallucination, i.e., the semantic inconsistency. In this paper, we take a novel perspective on the issue above - exploiting the semantic coherency between the visual and language modalities. Specifically, we propose the Consensus Rraph Representation Learning framework (CGRL) for GIC that incorporates a consensus representation into the grounded captioning pipeline. The consensus is learned by aligning the visual graph (e.g., scene graph) to the language graph that consider both the nodes and edges in a graph. With the aligned consensus, the captioning model can capture both the correct linguistic characteristics and visual relevance, and then grounding appropriate image regions further. We validate the effectiveness of our model, with a significant decline in object hallucination (-9% CHAIRi) on the Flickr30k Entities dataset. Besides, our CGRL also evaluated by several automatic metrics and human evaluation, the results indicate that the proposed approach can simultaneously improve the performance of image captioning (+2.9 Cider) and grounding (+2.3 F1LOC).