 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus Graph Representation Learning for Better Grounded Image Captioning
Paper and Code
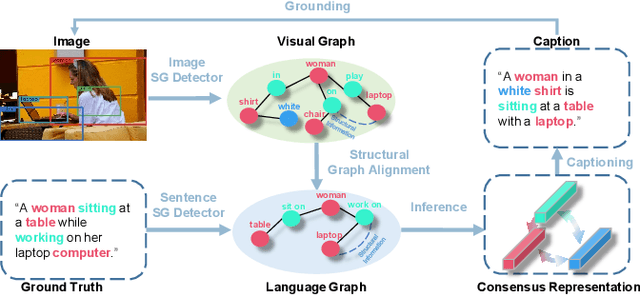
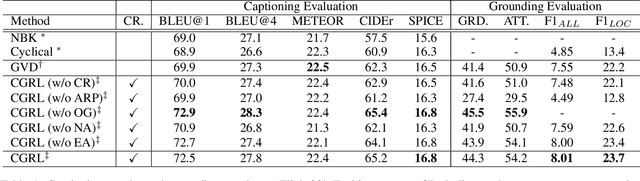
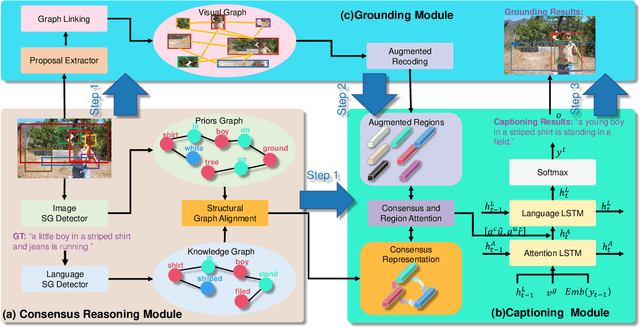
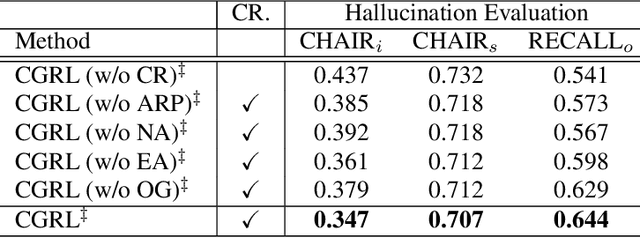
The contemporary visual captioning models frequently hallucinate objects that are not actually in a scene, due to the visual misclassification or over-reliance on priors that resulting in the semantic inconsistency between the visual information and the target lexical words. The most common way is to encourage the captioning model to dynamically link generated object words or phrases to appropriate regions of the image, i.e., the grounded image captioning (GIC). However, GIC utilizes an auxiliary task (grounding objects) that has not solved the key issue of object hallucination, i.e., the semantic inconsistency. In this paper, we take a novel perspective on the issue above - exploiting the semantic coherency between the visual and language modalities. Specifically, we propose the Consensus Rraph Representation Learning framework (CGRL) for GIC that incorporates a consensus representation into the grounded captioning pipeline. The consensus is learned by aligning the visual graph (e.g., scene graph) to the language graph that consider both the nodes and edges in a graph. With the aligned consensus, the captioning model can capture both the correct linguistic characteristics and visual relevance, and then grounding appropriate image regions further. We validate the effectiveness of our model, with a significant decline in object hallucination (-9% CHAIRi) on the Flickr30k Entities dataset. Besides, our CGRL also evaluated by several automatic metrics and human evaluation, the results indicate that the proposed approach can simultaneously improve the performance of image captioning (+2.9 Cider) and grounding (+2.3 F1LOC).